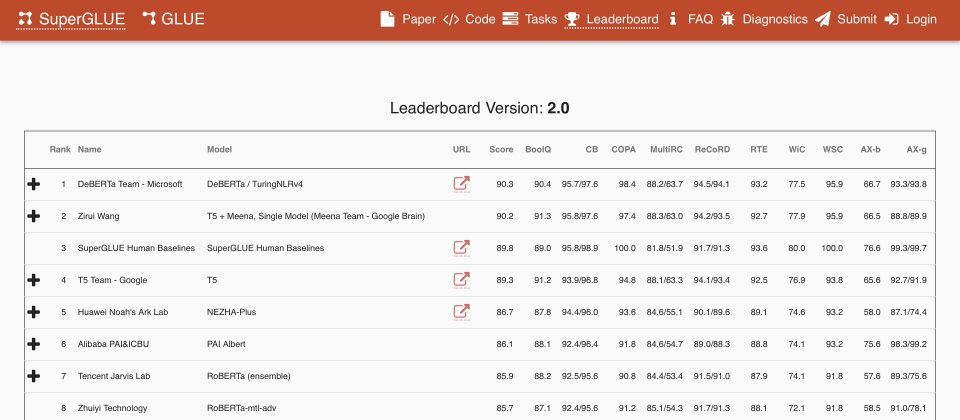
微軟的DeBERTa模型在SuperGLUE基準中,超過了人類基準線的89.9分,以90.3分成為SuperGLUE排行榜的第一名。SuperGLUE是2019年,臉書人工智慧研究院、Google DeepMind、華盛頓大學和紐約大學共同推出的一系列基準任務,用來衡量現代高效能語言理解人工智慧的能力。
DeBERTa是一種變換(Transformer)神經語言模型,使用自我監督式學習技術,以大量原始文字資料進行預訓練,與其他預訓練語言模型一樣,DeBERTa目的在於學習通用語言表達形式,用來解決各種自然語言理解任務。
由於對話式人工智慧深度學習模型已發展到一定的程度,過去的基準測試被認為不敷使用。紐約大學、華盛頓大學和DeepMind在2018年的時候,發布通用語言理解評估(GLUE)基準,來評估模型的語言理解程度,但是有不少自然語言處理模型,在GLUE特定任務的表現,已經遠遠超過人類,但是即便這些模型可以在GLUE超越人類,但是卻無法良好處理某些人類可以輕鬆且完美解決的問題,因此研究人員設計出SuperGLUE,來更好地評估模型能力。
微軟提到,SuperGLUE是目前評估NLU模型最具挑戰的基準。SuperGLUE共含有8種不同任務,包括選擇合理的替代方案(COPA)的因果推理任務,模型必須在取得前提之後,從兩個可能的選擇判斷其因果關係,人類能在COPA任務簡單地達到100%精確度,但是人工智慧模型則還有許多進步空間。
微軟舉例,當考慮到前提是「孩子對疾病免疫了」,並且提問「造成這種結果的原因?」,要求模型從「他避免暴露在疾病中」和「他使用了該疾病疫苗」中做選擇,通常人類都可以選對,但是這卻對人工智慧是很大的挑戰,因為模型必須要了解前提,才能夠正確選擇因果關係。
而微軟最近透過更大規模地訓練DeBERTa模型,使得模型能力獲得提升,最新版本的模型擁有15億個參數48個變換層,光單個DeBERTa模型就能超越人類在SuperGLUE上的表現達到89.9,而組合DeBERTa模型更可達到90.3分,更大幅度超過人類的89.8,另外,DeBERTa模型也在GLUE基準獲得90.8分,也是排名第一。
微軟將會對外發布這個具有15億參數的DeBERTa模型以及其程式碼,此外,該DeBERTa模型,也會整合到微軟圖靈自然語言表達模型的下一個版本Turing NLRv4中,支援微軟的各種產品。
圖靈模型融合了多種微軟開發的語言創新技術,並且經過大規模訓練,用在Bing、Office、Dynamics和Azure認知服務等產品中,提供諸如聊天機器人、推薦、搜尋以及內容生成等人機互動任務中。
在SuperGLUE超過人類基準的模型,不只有微軟的DeBERTa模型,還有Google大腦結合T5與Meena的語言模型,得分為90.2,分數僅差距DeBERTa分數0.1分,另一個分數也很接近人類基準的Google T5模型,也有89.3分。
熱門新聞

2026-02-11

2026-02-12
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-09

2026-02-13


2026-02-10