Google發布了一個稱為ToTTo的資料集,由開放領域的表格到文字(Table-To-Text)生成資料組成,包含來源的表格資料,以及總結表格資料的句子配對,另外,還有可用來評估模型幻覺(Hallucination)的文字生成任務。ToTTo擁有121,000個訓練樣本,以及7,500個用於開發和測試的樣本,Google提到,由於其標註的高精確性,該資料集很適合用來作為,高精確文字生成研究的基準。
在過去幾年,自然語言生成研究已經有巨大的進步,但Google提到,儘管神經系統已經可以產生順暢流利的文字,但是仍然會產生可理解,但是並非忠於(Faithful)來源資料的文字,這種情況被稱之為幻覺,Google舉例,像是神經基準模型總結比利時足球運動員Constant Vanden Stock,在維基百科的條目資訊框,總會錯誤總結Constant Vanden Stock是位美國花式溜冰運動員。模型產生幻覺的可能性,使得有高準確性要求的應用,無法使用自然語言生成系統。
.jpg)
透過評估生成的文字是否忠實呈現來源內容,可以緩解這個問題,不過這個評估過程有其困難性,幸運的是,諸如表格等結構化來源內容的評估,通常會比較容易,而且結構化資料,還可以用來測試模型在因果以及數字的推斷能力。
但Google表示,現有的大規模結構化資料集通常存在雜訊,也就是參照的句子,無法完全由表格資料推斷出來,進而使得在模型開發中,難以量測幻覺。
因此Google製作了ToTTo資料集,除了包含表格到文字資料對之外,還添加一系列受控的生成任務,該任務會提供維基百科表格,以及一組選定的資料格,作為生成總結這些資料格句子的材料,這些任務存在多種挑戰,包括數值推論、開放領域詞彙以及多樣的表格結構等。
ToTTo資料集使用了一種特別的資料標註方法,以產生沒有雜訊的資料集,Google提到,要從表格資料中,獲得自然又乾淨的目標句子,是一件困難的工作,諸如Wikibio和RotoWire之類的資料集,其配對表格和文字的過程,總會出現許多雜訊,而這讓研究人員難以區分,究竟幻覺是由資料雜訊造成的,還是模型本身缺陷造成的。
而且即便註釋者從頭開始撰寫句子,也會因為要忠於表格資料,而使得最後結果缺乏結構和樣式的多樣性,為了解決這些問題,ToTTo使用新穎的資料註釋策略,Google要求註釋者分階段修改現有維基百科的句子,而這個方式讓句子既乾淨又自然,且還能包含有趣且多變化的語言特性。
.jpg)
Google使用目前最先進的三個模型,產生了一些基準結果,實驗結果顯示,BERT-to-BERT模型在BLEU與PARENT兩個指標,表現的比Pointer Generator和Puduppully et al. 2019模型更好,但這3個模型,在研究人員另外準備的挑戰子集上,效能表現皆不好,Google表示,因為挑戰子集飽含領域外樣本,對於3個模型都更具挑戰性。
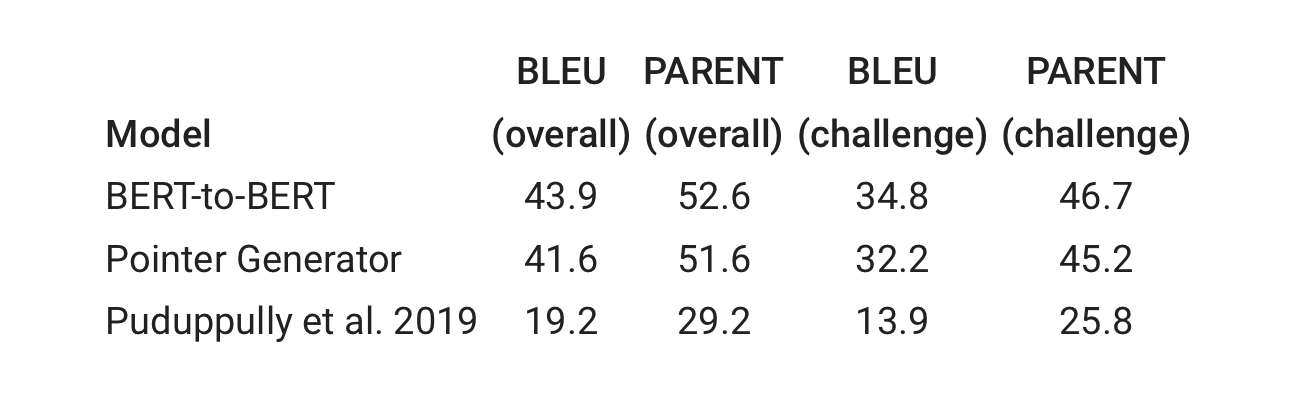
但這些結果並不足以評估文字生成系統的幻覺,為了更好地了解幻覺,研究人員假設內容上的不一致,都是幻覺造成,並手動評估最佳表現基準,以確定句子忠於來源表格內容的程度,而結果顯示,BERT-to-BERT較人類專家,多出約20%的幻覺。
基準測試顯示,即便是現在最先進的模型,也難以解決幻覺、數值推論以及稀有主題等問題,而且即便模型輸出正確,但是資訊也不如參考資訊豐富。透過提供這些基準測試,Google說明ToTTo是可用於建模研究,並且發展模型評估指標的資料集。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-09

2026-02-06

2026-02-09