
Google新開發IconNet視覺物體偵測模型,用來強化其無障礙應用程式Voice Access辨識圖標的能力,進而改進行動應用程式的可存取性。Voice Access是一個Android上的應用程式,可讓使用者以口語命令來自由控制裝置,過去Voice Access需要仰賴螢幕上使用者介面元素的無障礙標籤來運作,但是在許多應用中,像是圖像或是圖標,並非總能提供適當的無障礙標籤,如此也就降低了Voice Access的可用性。
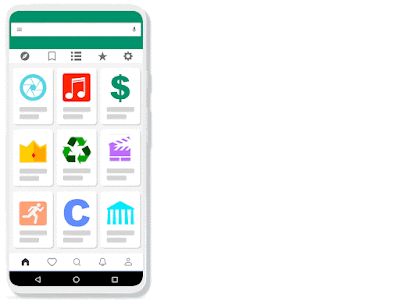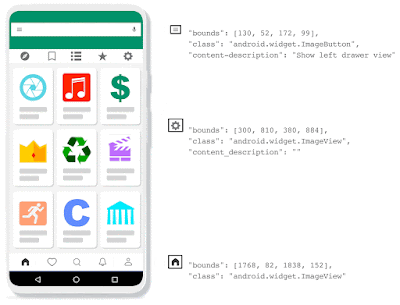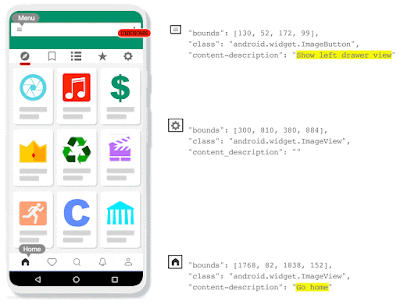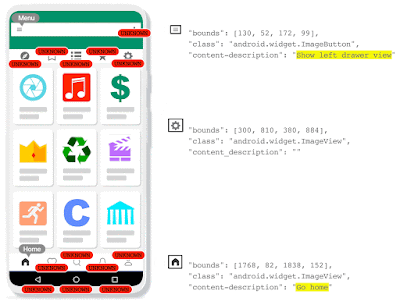
為了解決這個問題,Voice Access必須要能夠藉由偵測螢幕上的畫素,來自動辨識圖標,而非僅仰賴無障礙標籤,因此Google開發了IconNet,這是一個以視覺為基礎的物體偵測模型,該模型可以使用與應用程式低層架構無關的方法,自動偵測螢幕上的圖標,目前這項功能已經加入到最新的Voice Access應用程式中。
IconNet僅透過使用者介面螢幕截圖,就可以偵測31種不同的圖標類型,接下來還會擴充至70多種,為了要讓IconNet在裝置上順暢運作,IconNet經過最佳化使其適用於行動環境,模型被設計成小巧且快速的形式。
裝置上使用者介面元素偵測器,為了能夠在多種效能的手機上執行,因此需要具有低推理延遲的特性,Voice Access需要使用標籤來回應用戶的話語,因此推理時間必須很短,在Pixel 3A上要小於150毫秒才行,而且模型大型不能超過10 MB。
Google提到,從技術的角度來看,偵測應用程式螢幕上的圖標,問題類似典型的物體偵測,因為模型可以透過位置和大小,來標記各個元素,但從另一方來說卻又是完全不同的問題,圖標通常為小物體,具有相對簡單的幾何形狀和顏色,應用程式的畫面跟自然圖像有很大的不同,更加結構化和幾何化。
IconNet採用先進的CenterNet架構,該架構可以從輸入的圖像中擷取特徵,並且預測適當的包圍框中心與大小,研究人員提到,CenterNet特別適合用來偵測圖標,因為使用者介面元素由簡單且對稱的幾何圖形構成,比自然圖像更容易辨識中心。
研究人員收集了超過70萬張螢幕截圖來訓練模型,並且使用啟發式和輔助模型,來強化模型辨識稀有圖標的能力,進而簡化了資料收集的工作,而且Google還對螢幕截圖使用資料增強技術,強化模型辨識少見圖標的能力。
研究人員使用傳統的物件偵測指標來量測模型效能,將IconNet與其他模型MobileNetEdgeTPU和SSD MobileNet v2相比,在固定延遲時間的條件下,IconNet辨識能力明顯較高。Google會持續改進IconNet,增加支援的使用者介面元素,並且擴充IconNet,要透過辨識圖標的功能,來區分外觀相似的圖標。

熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10


2026-02-06

2026-02-10