
中華電信研究院研究員陳逸夫指出,自家模型輕量化以近似運算為核心,來降低耗費運算資源的參數量。
中華電信研究院今(25日)線上分享物件模型輕量化經驗,把輕量重點放在模型頸部和頭部,用近似運算來減少核心參數量和運算量,比如用差值讓長寬一致、用一層卷積讓Channel數一致,以及用深度可分離卷積來重組頭部。但這樣還不夠,損失函數也要輕量設計才行。
從智慧交通AI引發的模型輕量化研究
近年來,中華電信研究院接下不少智慧城市AI專案。光是去年,他們就部署了影像辨識AI,來實現機場防闖電子圍籬、北市府跨年防疫人流偵測、高鐵違規上下車取締。今年,他們更把影像辨識AI部署在桃機捷運,來偵測擁擠程度和遺留物,也運用在高雄市交通科技執法,來揪出闖紅燈的行人,甚至也用在中華電信自家園區,來辨識越線的車輛和車牌。
「但這些AI應用,都在遠端機房計算,」中華電信研究院交通院方研究所研究員陳逸夫指出,遠端運算有著網路、主機存放等大量成本。為降低成本,中華電信思考,這些AI模型的推論作業,是否能在邊緣運算就好?
但要實現AI邊緣運算,得考量邊緣裝置的限制,比如模型大小、運算複雜度、速度和準確度等。能做到這一點的,就是模型輕量化,中華電信也因此著手研究。
輕量化重點1:骨幹直接採用新技術
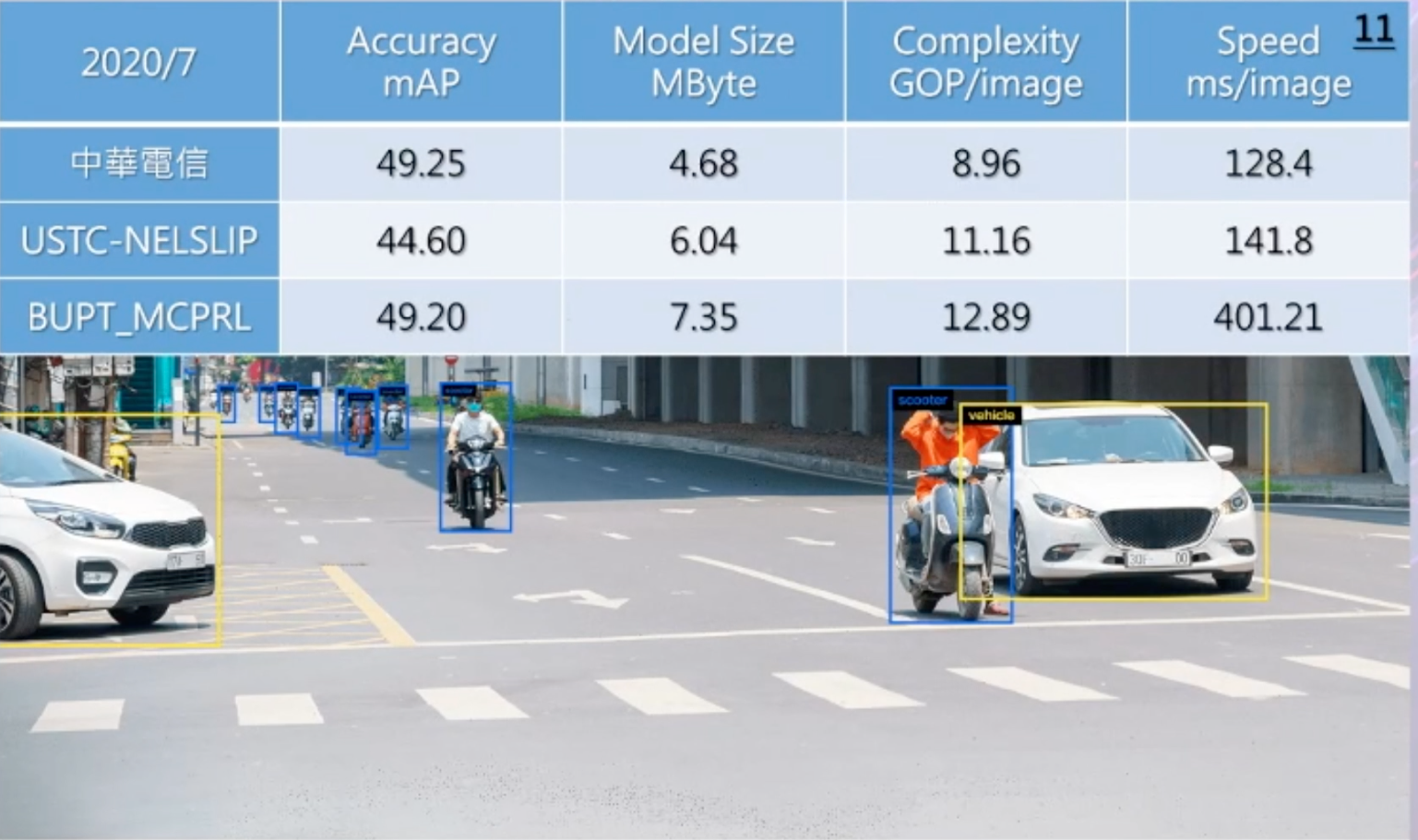
首先,他們參考科交大人工智慧普適中心舉辦的物件偵測模型輕量化比賽,以去年7月公布的第一、二名表現為基準(Benchmark),來設計輕量化模型。這些模型的評分包括準確度、模型大小、複雜度和速度。
接著,中華電信著手調整物件偵測模型。陳逸夫指出,物件偵測模型由3大部分組成,也就是骨幹(Backbone)、頸(Neck)和頭(Head),骨幹負責收集特徵,頸負責連結、融合骨幹抽取的特徵,頭則是預測物件。
通常,骨幹需要大量資料來進行預訓練,比如用ImageNet,因此「成本很高。」如果這部分改用其他資料來訓練,勢必得花更多成本來驗證。
陳逸夫建議,直接採用最新技術會是個不錯的選擇,比如Google去年3月發表的輕量化結構EfficientNet-Lite,特別是第2版和第3版。
輕量化重點2:頸部用近似運算減少參數量和運算量
至於頸部的用途,則是融合骨幹抽取的特徵。從技術發展來看,「融合不同尺度的特徵,模型可以學得很好,」但陳逸夫也指出,這背後的代價是用運算成本非常高的卷積(Convolution),讓不同的長、寬、Channel數一致,才能融合。「我們輕量化的重點,就是這些卷積。」
於是,中華電信改用差值讓長、寬一致,再用一層卷積讓Channel數一致,如此就能減少卷積的使用。他表示,這些近似運算可保有多尺度融合的精神,「大量減少參數量和運算量。」
輕量化重點3:頭部用深度可分離卷積重組、莫忘損失函數
至於頭部,則由許多卷積組合而成。「這些卷積得保留,」因為,模型就是靠這些卷積來學習任務和預測,因此,中華電信採用深度可分離卷積,來重組頭部。這個深度可分離卷積,與一般卷積近似,保留了卷積的功用,卻大幅減少參數量和計算量。
至此,中華電信的模型輕量化告一段落,核心思想就是以近似運算,來減少參數量和運算量。不過,他們後來發現,這個近似方法讓模型難以收斂。
於是,他們也把損失函數納入輕量化設計,將難以訓練的損失函數,融合到其他損失函數中,直到可以收斂為止。
最後,中華電信將輕量化的模型,部署到前述競賽的邊緣運算平臺PX2上,發現不管是模型大小、準確度、複雜度和速度,都達到原先設定的標準,也就是平均準確度均值(mAP)達49.25%、模型大小為4.68MByte、複雜度8.96GOP/Image、速度為每128.4毫秒辨識一張影像。文◎王若樸
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10