金融建模總監Tim Thornham表示,不論是哪一種風險預測場景,以Julia撰寫的模型計算時間都比原IBM系統Algo來得快,最高可加速200倍。(圖片來源/Aviva)")
英傑華(Aviva)金融建模總監Tim Thornham表示,不論是哪一種風險預測場景,以Julia撰寫的模型計算時間都比原IBM系統Algo來得快,最高可加速200倍。(圖片來源/Aviva)
主打科學運算的Julia,不只活躍於學術圈,近幾年也開始獲得不少產業巨頭的青睞,不只是科技圈,如Google、臉書、IBM等紛紛採用,國際百年金融老店、世界製藥龍頭、IT品牌大廠和政府機構等,都開始出現應用實例,不同產業的企業都對Julia讚譽有加,我們從中挑選出國外6大應用實例,來介紹各產業應用Julia的趨勢和經驗。
實例1:世界第五大保險公司也用Julia,讓上萬行程式碼縮成1千行
圖片來源_Aviva
英傑華(Aviva)金融建模總監Tim Thornham表示,不論是哪一種風險預測場景,以Julia撰寫的模型計算時間都比原IBM系統Algo來得快,最高可加速200倍。
英傑華(Aviva)發跡於英國,不只是英國最大保險業者,更是世界第五大保險公司。它曾與第一人壽聯手,一度跨足臺灣。
但2008年引爆的一場危機,改變了它的命運。那年金融危機爆發,不只讓數百萬名美國人頓無居所,更擊潰歐洲多國的金融體系;冰島和愛爾蘭銀行系統崩潰,希臘失業率從7%飆升至28%,西班牙房地產價格下跌 50%,全球總損失高達22兆美元。
危機過後,歐盟通過了嚴格的新清償能力II(Solvency II)法規。這套監理機制要求保險業者必須備妥必要資源,來應付類似的金融危機,像是,保險業者得做更多的風險建模,進行日常風險模擬,而不只有特殊情況才做。此外,保險業者還要增加分析的複雜性,甚至法規要求業者必須更快、更透明化,也要更有效的管理風險。
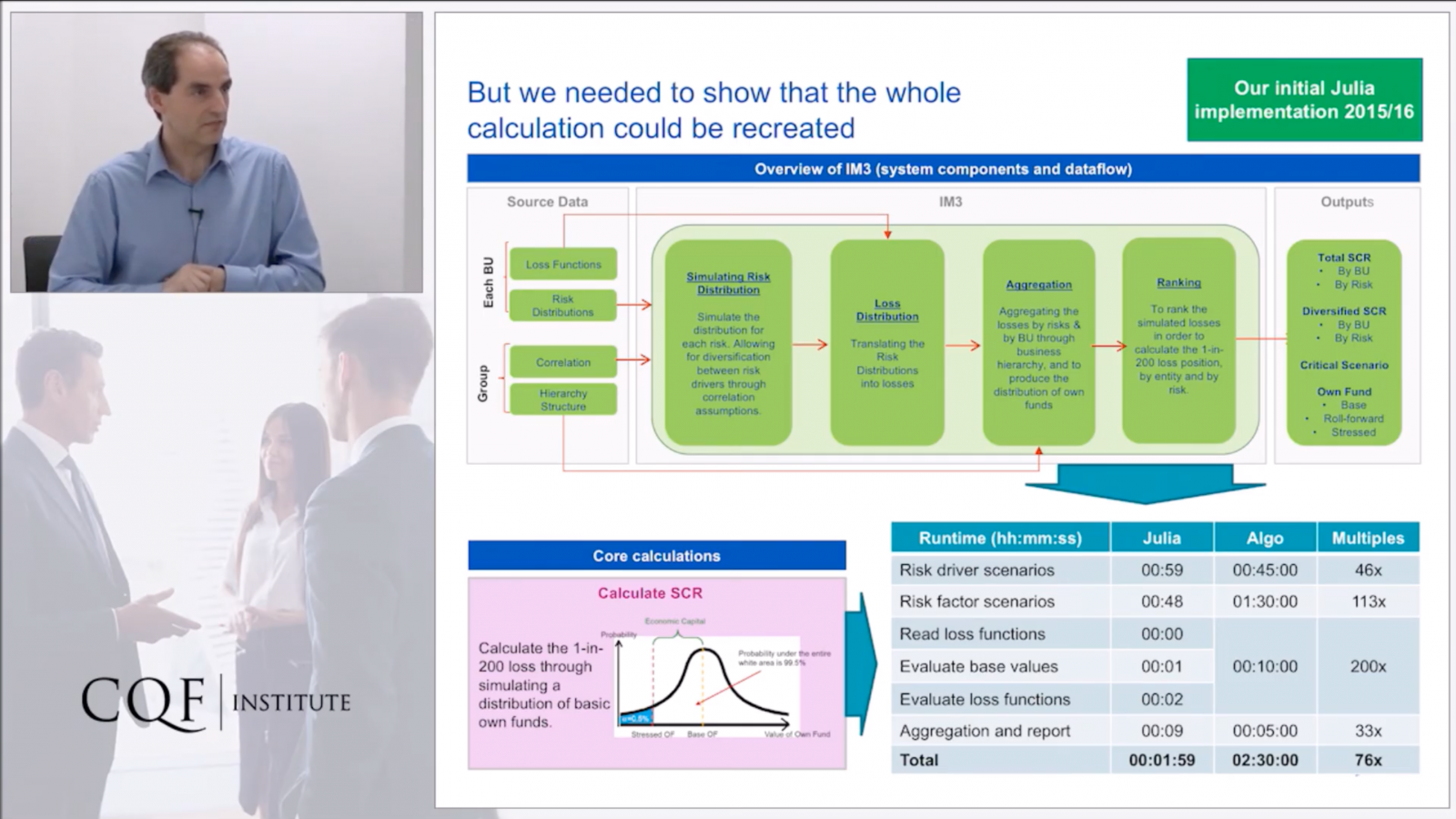
英傑華原本在2012年啟用了一套風險模型Algo,以IBM Algorithmics系統打造。不過,英傑華金融建模總監Tim Thornham指出,他早就意識到原有風控系統的不足,於2015年初開始研究才開源三年的Julia。
他當時就發現,Julia語言簡潔易懂,也能平行化運算、快速處理複雜模型,於是決定用這個語言,來打造一套新的風控系統IM3。
2016年,新清償能力II規範上路,在該年中,IM3就正式取代使用多年的Algo。英傑華比較,IM3比Algo快上1,000倍,採用Julia語言開發後,不只將原本Algo的1萬4千行程式碼縮短到1,000行,啟動時間只有Algo的十分之一。甚至,執行風險模擬模型所需的伺服器叢集,也從100臺縮減至5臺。
Tim Thornham坦言,改用開源語言不只降低英傑華對商用軟體公司的依賴,也減少了授權費和運算成本,一年下來可省下數百萬英鎊。不過,他提醒想採用Julia的企業,最好先從一臺伺服器開始嘗試平行化運算,再循序漸進擴大規模。
不只用於風控,英傑華後來擴大導入Julia,將Julia寫成的應用程式部署到全球的壽險、一般保險和保險工具上,並進一步用Julia打造風險分析、信用管理和資產管理等系統。
實例2:百年輝瑞製藥大廠研發新幫手,心臟模擬運算靠Julia百倍加速
一場疫情讓輝瑞(Pfizer)紅遍大街小巷。這家200多歲的藥廠是世界5大製藥公司之一,光是美國市場,就有356種藥物上市。不過,藥物上市得經過嚴謹的開發流程,光一種藥物的人體試驗和監管審核,可能就要花上10年,成本超過20億美元。
為加速研發效率、降低成本,輝瑞用了不少模型藥物開發(MIDD)方法,比如用定量系統藥理學(QSP)模型,在臨床試驗前,先模擬新療法的療效。QSP模型可在臨床試驗的不同階段前,找出藥物有效性和安全性問題,而整套MIDD方法,更可用來預測試驗是否會失敗,幫藥廠省下資源,專注在更可能成功的臨床試驗。
不過,要在步調快的臨床開發周期中,發揮MIDD最佳效果,一直是藥廠建模團隊的難題。因為QSP這類的分析,可能需要找出上百萬種非常複雜的剛性微分方程解,越複雜越花時間,難以快速求解。
輝瑞發現Julia這個語言處理剛性微分方程式有不少優勢,不只可以支援GPU加速,還具有進階的微分方程函式庫DifferentialEquations.jl,其中更有一些可以利用藥物計量系統特性的新演算法,效能甚至比經典C++和Fortran微分方程的解算機(Solver)還好。
利用Julia求微分方程解不僅快,DifferentialEquations.jl也是所有語言中功能最完善的微分方程解算機。科學研究者不必像使用其他開發語言時(如R或Python)般,得花大量時間寫程式,而是善用Julia這個函式庫即可。
輝瑞也用Julia來加速一些藥物研發用的模型,例如心臟穩定狀態模型的運算時間,可以從原本的一天縮短為40分鐘,甚至搭配多執行緒作法,總模擬時間還能進一步縮短到9分鐘,等於效率快了115倍。
另一個則是活性藥物標靶模型。改用Julia後,這個模型的總模擬時間,從每位患者15.5小時縮短為1小時。而且,只要將原有設定Threads改為Distributed和Distributed GPU,就能讓輕鬆將程式碼從單臺主機擴展到部署在CPU或GPU上的JuliaRun套件,能在一天內完成分析,實現過往不可能做到的任務。
實例3:澳洲打造國家級電力預測模型,能估算沿岸各洲未來30年每一小時的電力需求
圖片來源/James Foster
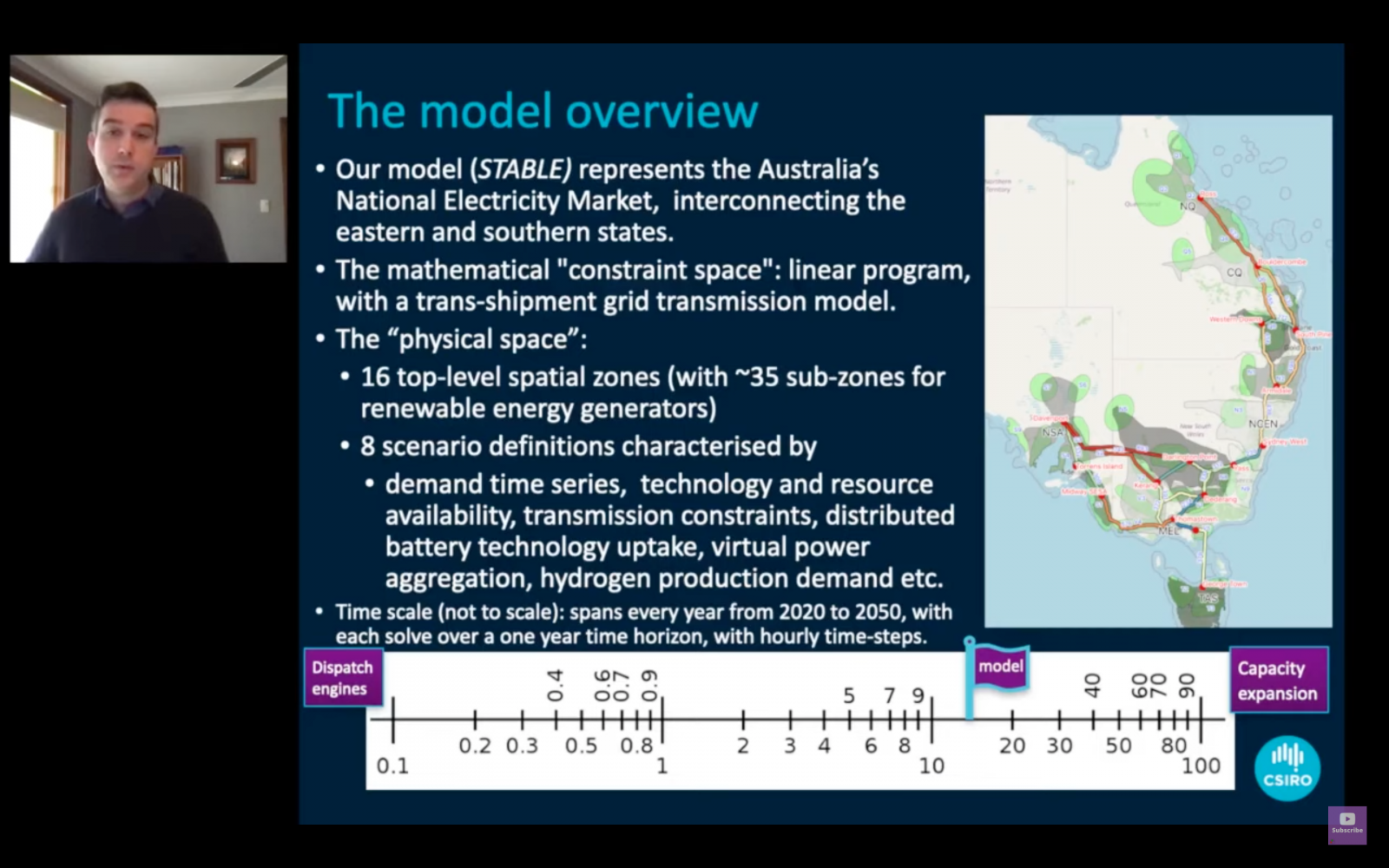
澳洲科技研究組織CSIRO利用Julia開發電力需求預測模型STABLE,可用來計算2020年至2050年間,東澳至南澳沿岸各州每一年中,每小時的電力需求變化。
澳洲聯邦科技工業研究所CSIRO為澳洲政府主要的國家級研發機構,就像臺灣工研院的角色一樣。CSIRO擁有許多創新專利,例如開發出世界第一種塑膠鈔票。
負責研究能源模型的CSIRO研究科學家James Foster,他在今年JuliaCon 2021中,分享自己如何用Julia知名的JuMP.jl套件,來打造澳洲國家電力市場預測模型STABLE,可以用來計算東澳至南澳沿岸各州的電力流動狀況。
STABLE利用一套現成的開源能源計算模型DIETER為基礎,擴大規模來計算各州不同用電場景下電力成本最小化的線性程式,可以計算電力傳輸系統的交互作用,包括了一年內每小時的電力系統變化,如發電、儲存、傳輸、再生能源的利用以及氫電解作用等變化,以便進一步估算成本。
CSIRO的目標,是要計算2020年至2050年間,每一年中每小時的電力需求變化,而且可以套用到8種不同特性的電力場景。這對James Foster來說是一大挑戰,因為他要想辦法整合模型程式碼和資料工作流程,來打造出一個可以套用到實際數據進行預測的國家級規模可用模型。
因此,James Foster設計一個靈活架構來解決問題。他先用JuMP實作出一個核心模型計算模組DIETER.jl,再搭配一個負責管理配置的模組稱為STABLE.jl,來進行配置、階層設置、場景定義等工作,再搭配一組描述領域知識和邏輯的Julia腳本,將實際數據和Julia模型程式碼串聯,來進行計算和預測,才完成了這套電力預測系統,也順利上線了。
James Foster也提醒,擴展任何現成模型前,要給自己充足時間,準備一系列檢查工具,才能順利完成任務。
實例4:思科看上Julia簡潔快速,研發試驗AI產品原型不用再混兩套語言
思科是全球數一數二的IT老牌大廠,2013年買下捷克資安新創Cognitive Security。這家公司的技術主管Tomas Pevny進入思科後,專門研究如何用機器學習技術來找出被入侵或被病毒感染的電腦。
他大量運用圖像隱碼技術(Steganography)和隱碼分析技術,目標是要實作出一套可優化的訊息傳遞圖學演算法,想要設計出涵蓋整個網際網路的圖(Graph)架構來建模。
後來有位朋友推薦了一篇部落格文章給他,文章講述如何以Julia實作RBM類神經網路,而且可以比C語言少2倍運算成本。他被Julia深度學習框架Flux.jl吸引,認為這個框架,可以讓他快速實現目標。
「Julia是我用來打造原型的主要語言,」Tomas Pevny表示,而且只需用Julia單一個語言即可,不必像過去得用「Python + TensorFlow + C」三劍客的組合,不能單用Python,還得動用到C語言才行。
在Flux.jl釋出0.3版後,他就自己建立的多實例類神經網路函式庫主要功能全都移植到Flux.jl框架上,他與同事也跳下來擴充Flux,來支援自建的Mill.jl函式庫中一般與多實例學習問題。
為何看上Julia來打造雛形?Tomas Pevny舉例解釋,在實作卷積網路時,他用布林值來定義稀疏矩陣,只寫兩行Julia程式碼,就能比同樣用途的Python程式碼快上7.5倍。對他來說,Julia的簡潔快速,讓他更有效率打造原型、快速開發和試驗。
實例5:數秒計算能模擬5萬輛車真實車流,德勤澳洲用Julia打造更即時的數位分身模擬平臺
圖片來源/德勤澳洲
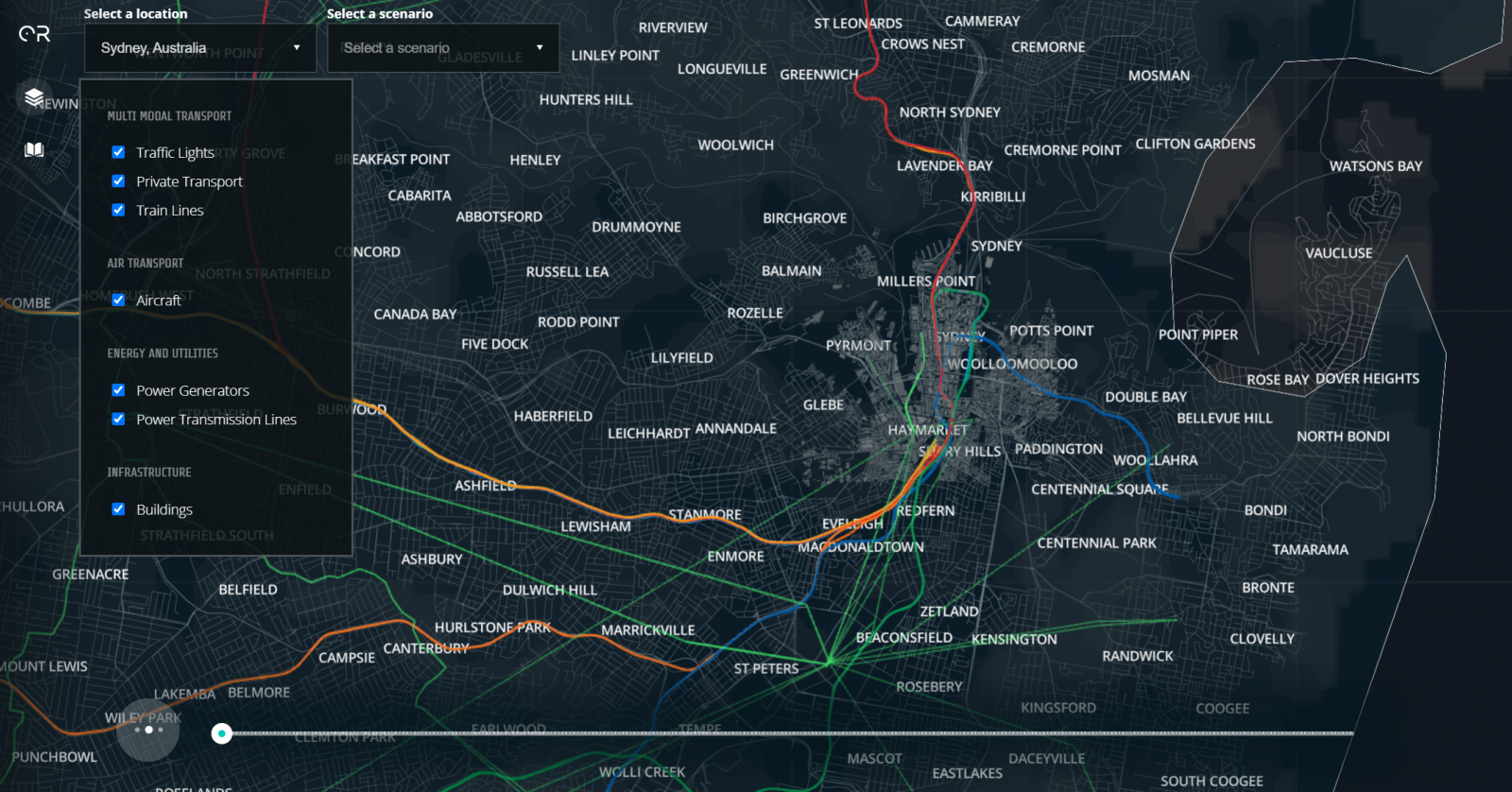
德勤澳洲用Julia打造數位分身平臺Optimal Reality Digital Twin,幾秒內就能模擬出數百萬個真實物件的數位分身,來呈現彼此間的網絡關係作為決策參考之用。
德勤(Deloitte)澳洲分公司用源自F1賽車的模擬技術,打造了一個即時數位分身模擬平臺Optimal Reality Digital Twin,可以在幾秒內,就模擬出數百萬個真實物件的數位分身,來呈現彼此間的網絡關係作為決策參考之用。
例如,德勤用這套系統來模擬澳洲空域24小時內所有航班的飛機移動路徑,來找出調整航線改善空中交管的維運效率,或是可以找出更好起降排程,來縮短飛機在空中等待降落的繞場時間,也能減少油耗。另外,這個平臺也能用來模擬一座城市的各種能源即時使用情況,作為打造智慧城市的參考。
還有一個進入PoC驗證的實例是,用來模擬5萬輛汽車的分身,來呈現在城市道路上移動的即時車流情況,可以模擬出車對車,以及車與環境之間的互動,例如車禍事件或塞車,甚至可以模擬車流如何受到城市大眾運輸的影響,作為設計大眾運輸方式的參考。
為了讓這套模擬系統可以更即時完成龐大的模擬計算,德勤澳洲在背後所用的關鍵技術就是Julia。
不只如此,為了讓這套平臺可以套用到更多場景和產業,德勤澳洲採用微服務架構的設計。但Julia是一門年輕的語言,還在快速發展階段,為了讓產品團隊專注於上層應用和功能,而不用時時跟進Julia套件的最新進展,德勤團隊利用Julia套件生態系資源,打造一款內部使用的專用SDK。
這個SDK包括一個微服務樣板、一個公用程式樣板,還有各種公用程式套件和一個自定義的GraphQL介面。其中,微服務樣板是開發者打造微服務的第一步驟,樣板中含有多種功能,像是預設通訊路由、日誌記錄行為、自動文件生成、CI/CD腳本(如建立、測試和雲端部署)等。
德勤澳洲的研發工程師Malcolm Miller指出,微服務樣板套件節省開發微服務的時間,也讓團隊更專注於微服務的核心功能,而且能確保不同微服務的程式碼,都是標準化的。而公用程式樣板,則收錄了所有微服務都會用到的共通功能,並為這些功能提供一致的介面。
他總結,這套以Julia開發的SDK,讓團隊更能專注於自己的工作,也加速整體微服務開發流程,而且團隊更容易維護程式碼、降低重複性。
實例6:美國紐約聯邦儲蓄銀行亮相史上最複雜DSGE模型

圖片來源/Erica Moszkowski
美國紐約聯邦儲蓄銀行以Julia打造自家史上最複雜的總體經濟模型DSGE,研究分析師Erica Moszkowski指出,當時的Julia 0.4版執行效能就已比MATLAB語言還要快。
2015年,美國紐約聯邦儲蓄銀行(FRBNY)公布了自家有史以來最全面、最複雜的總體經濟模型:動態隨機一般均衡模型(DSGE),而且是以Julia寫成。
DSGE模型非常重要,因為,它是各國央行用來分析貨幣政策、預測經濟走向的工具,舉凡經濟成長、消費支出和投資等趨勢都包括在內,臺灣央行也用DSGE來分析貨幣策略。
對FRBNY來說,DSGE模型的複雜程度更勝以往,需要更快速有效的運算。這是因為,美國自身和全球的經濟龐雜度大增,資料也越來越複雜,因此得開發更有效的工具,來分析經濟變數間的關係,提供政策建議。
為此,FRBNY研究分析師Erica Moszkowski帶領團隊,試著用Julia來打造DSGE模型。在他們看來,Julia有兩大優勢,首先是開源的免費軟體,對沒資源購買軟體授權的學術研究單位或組織來說,取得性更高。再來是,隨著DSGE模型越來越複雜,他們需要一個能高速計算的語言,來執行預測和政策分析。
接著,他們做了簡單的比對,發現用Julia寫成的模型計算時間,比經典的MatLab和Fortran語言還要快,更比原有系統快上10倍,就連模型中的特定求解測試也快了11倍。
「這對性能改善十分重要,因為,這個測試通常得跑上萬次,」Erica Moszkowski補充,測試時間縮短,意味著模型能更快速執行其他計算,也能節省模型運算成本。
她總結,Julia讓FRBNY寫出更通用簡潔的程式碼,也更容易維護。而且改用Julia後,DSGE模型的程式碼庫精簡了一半。FRBNY分析團隊在設計套件時,發現用Julia寫經濟模型有幾個好處,如彈性且強大的型別系統,能讓團隊設計出更直覺、簡單的程式碼庫,而多重派送(Multiple dispatch)能讓他們寫出更通用的程式碼。
最後,FRBNY也把他們打造的DSGE.jl模型開源出來,讓需要研究總體經濟的使用者免費使用。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10


2026-02-06

2026-02-10