")
Line用機器學習建立一個可以從使用者的原始Log資料來推測其特徵屬性的自動化推測機制,再套用到所有使用者,而且可以不斷自動化進行,再定期更新。(圖片來源/Line)
去年,Line重新改造了使用者人格(User Persona)預測系統,這是一個用來推測用戶屬性的系統,可以利用機器學習技術自動預測使用者的興趣、特質、特徵等,作為內容推薦或目標行銷等需要用戶分類資訊的應用場景。
這個系統有多重要?負責打造這套系統的Line資深機器學習工程師渡辺哲朗舉三個場景來說明。因為在這套系統中,記錄了兩大類使用者屬性資料,一種是與人口變項有關的屬性,例如性別、年齡,或是使用者所用裝置資訊,例如OS平臺,另一種則使用者的心理屬性,例如興趣,喜好等。
常見用途是廣告發送,Line廣告發送時,外部廣告主可以瞄準目標用戶,在特定可用的屬性中,指定想要行銷的目標對象的屬性,這個屬性就是使用者人格系統中記錄的使用者屬性之一。或者是官方帳號訊息推播,也能簡單指定特定條件的對象,這些條件包括性別、年齡、所用OS類型,地區、訂閱持續期的資訊,也來自人格系統的屬性記錄。
還有一項Line自己常見作法是用來解決新服務的冷啟動(Cold Start)問題。當新服務上線時,Line會透過推播訊息來吸引可能有興趣採用的潛在用戶,但是新服務的Log資料有限,無法用於推薦,就能使用者人格系統中累積的推測屬性(非真實而是由機器學習模型抽取的推測屬性),作為推薦對象的篩選,縮小推播範圍。「這對新服務上線的成本控管,有很大幫助。」渡辺哲朗說。
但Line用戶全球將近2億人,光是日本就有8,900萬個用戶,臺灣每月活躍帳號也有5千萬個,其中不少是一人有多個帳號。很難一一要求用戶填寫各式各樣的資料,甚至一些心理傾向的屬性,如何標記是一大挑戰。
這些用戶屬性資料在Line機器學習訓練中,也是一項重要的資料。在Line統一資料平臺IU中,有一個Z-feature特徵資料集,內有所有用戶可用來提供模型訓練用的使用者特徵資料,例如日本8,900萬名用戶的特徵維度高達480萬維,而臺灣5千萬名用戶的特徵維度則有140萬維。這些龐大的使用者特徵維度,正是Line各種與使用者相關的機器學習模型用來訓練的重要資料集,讓Line的訊息推播服務、廣告發送服務或是各種內容推薦能夠更精準鎖定目標對象的關鍵。
如何用機器學習自動推測出龐大使用者的人格特徵
如何產生龐大的使用者特徵資料庫,Line的作法是利用機器學習建立一個可以從使用者的原始Log資料來推測其特徵屬性的自動化推測機制,再套用到所有使用者,而且可以不斷自動化進行,再定期更新,例如每天,這些特徵資料,儲存到UI平臺的Z-feature特徵資料集中,讓各項服務的機器學習模型,都能有最新的使用者特徵資料可用,也可用於各種推播或推薦篩選目標對象條件之用。
不過要建立這樣的自動抽取用戶人格特質特徵的機器學習模型,也需要先有一個用戶人格特質資訊正確答案的資料集,作為訓練機器學習之用的Groud Truth資料。Line過去的作法是利用問卷調查來蒐集特定用戶的人格特質的正確答案,做為校正用的參考資料。不過,這種作法成本太高,效率太慢,也不容易累積夠多的訓練樣本。
Line還有一套自動化蒐集校正資料的作法,是利用廣告點擊行為來找出少量使用者的興趣,再用這一群少數使用者的特徵,來自動推測出其他使用者的興趣特質。
要採取這個作法,需要進行兩套機器學習模型分兩階段進行。一套是用來自動標記各種廣告內容的屬性,用來蒐集對這些廣告有興趣的使用者,第二套是再利用這群使用者,來自動推測出其他沒有點擊廣告的使用者的興趣。
第一階段,Line先利用人工對特定廣告或網頁內容進行特徵標記或註解,例如將一批遊戲廣告,由人工在這些廣告的屬性標籤上標記出「遊戲」類,再用這批已標記廣告來訓練一個自動標記廣告特性的ML模型(例如比對廣告描述、圖片、關鍵字等),稱為AD ML模型,用這個模型來自動標記大量廣告內容,可以找出其他也屬於「遊戲」類的廣告,這些廣告可以得到一個AI推測而來的「遊戲」標籤。
透過第一階段可以找到大量同類屬性的廣告,例如找出大量「遊戲」標籤的廣告,再將這批遊戲廣告推播到Line的遊戲頻道上,來吸引使用者點擊,就可以較快找到一群對「遊戲」有興趣的使用者。
Line會將點擊了這些「遊戲」廣告的使用者,在他們的人格特質檔案中的「興趣」屬性中加上「遊戲」這個標籤,換句話說,就是透過點擊以得廣告的行為,來得知「遊戲」是這個使用者的興趣之一。
接這利用這群有「興趣」標籤的使用者的人格特質檔案視為有正確「興趣」資料的人格特質Ground Truth資料集,搭配沒有興趣標籤的使用者人格特質檔案,來訓練人格特質預測模型,就可以得到User ML模型,用來推測所有使用者的人格特質的興趣屬性。反覆進行同樣的流程,不只是「遊戲」興趣,可以找出一批各種興趣類型的廣告,再找出有這些興趣傾向的使用者,利用這群已經興趣傾向的使用者人格特質特徵,再來自動推測出其他所有使用者的各種特徵。運作流程如下圖:
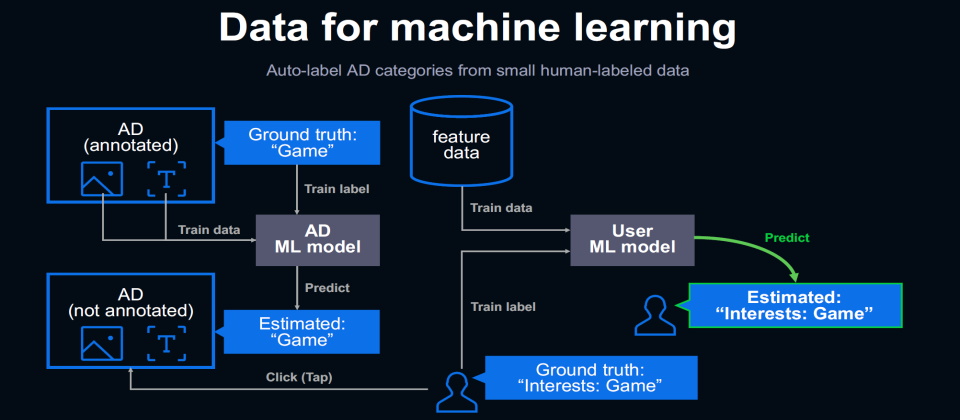
不過,不是所有的使用者人格特徵,都可以用廣告點擊行為來預測,但是,只要可以透過機器學習預測的特徵,Line都會盡量這樣做,來取代用調查建立標記的做法,「用點擊行為蒐集,只需要少量標記工作,而不用大規模調查。」渡辺哲朗表示:「這種兩階段蒐集資料來訓練模型的做法,有一個問題是很難調校優化模型,因此每一次打造模型時,都要特別講究優化。」
Line在2014年就打造出第一代的使用者人格推測系統,當時利用Scrath實作出用推測人格特質的神經網絡模型程式碼,為了處理大規模資料,後來進一步導入了MPI平行處理技術,2016年更進一步使用深度學習框架Theano和Mesos叢集打造出一整套系統,這就是第一代的使用者人格推測系統。
第一代系統的運算以CPU為主,所用的Theano深度學習框架,經過幾年反而漸漸沒落,甚至無法使用新的主流機器學習函式庫,例如就無法使用PyTorch。
隨著使用者規模越來越大,推測系統老舊的問題越來越嚴重,所以,去年夏天,Line決定導入GPU運算技術,也將整套系統轉移到現在主流的容器管理平臺K8S上。為了善用這個環境,Line還自行發展了一套分散式計算的機器學習函式庫稱為ghee,可以使用最新的主流深度學習函式庫來進行使用者人格特徵模型的訓練和推測之用。
去年夏天打造第二代系統,採用GPU和K8s
不過,去年夏天完成了第二代系統後,Line還不滿意,尤其日後要因應與日本Yahoo整併後暴增的3億人用戶規模,得讓這套使用者人格預測系統更有效率,也要更容易擴大規模,Line後續還展開了幾項系統改造工程。
為提高效率處理更龐大用戶規模,展開多項系統改造
為了提高推論預測的準確度,Line將去年夏天所用的單層DNN,改為多層架構的CNN卷積神經網絡中的ResNet深度殘差網絡,也針對不同類型的服務,來區分不同的embedding層,進行不同的嵌入處理程序,進而改善準確度, 另外還採用了MLP-Mixer作法,來讓模型更快速達到SOTA等級的預測效果。渡辺哲朗解釋,不是每一個用戶都會用到Line的所有服務,MLP-Mixer這種作法可以彌補用戶所用服務有限時資料不足的影響,能讓對這類少量服務用戶也能達到SOTA等級的預測效果。
除了改善模型,另一方面還需要維持屬性推測的穩定性。渡辺哲朗表示,因為採取自動化作法來推測用戶屬性,有時模型推測的結果差異很大,例如昨天推測的40歲族群有10萬人,但隔天模型推測有此特徵的人卻是7萬人,但業務人員可能還來不及調整推播策略的設定,導致這波行銷對象的人數就會少發送3萬人,而不是原本預期的10萬人。「模型輸出不穩定會對業務團隊產生很大的影響。」他強調。
所以,Line後來也採用了一些作法,來避免單日波動過大。例如開發了一個數據平滑化API,採用逐日分階段釋出新模型預測結果的作法,例如新模型雖然預測這項屬性的人有10萬人,但Line不會一天就將10萬人的屬性都套用新值,而是分幾天,每天只更新部分使用者的屬性,來避免突然一天出現增加 10萬人異動的大波動,避免業務團隊來不及因應。
另外,Line也打造了一套MLOps系統稱為Lupus,可以用來追蹤模型品質,來監控是否出現推論極端變化的情況,例如自動透過SQL指令來查詢不同屬性的用戶數量,來判斷新模型預測屬性是否出現劇烈變化。
因為第二代使用者人格預測系統,可以針對不同的資料來源或屬性類型,來採取不一樣的特徵抽取處理程序,但不同流程各自抽取特徵時,處理流程中會有類似的階段或步驟,例如特徵抽取訓練、建立資料集作法,或是進行模型再訓練的作法也會類似。
因此,Line建立了一套可以讓不同處理流程都能共用的機器學習函式庫ghee,還提供了一套共用的Model API來進行訓練,甚至是,連預處理都有一套處理API,方便開發者快速進行特徵屬性的資料預處理作業。「經過這些改造,Line才有了一套成熟的使用者人格預測系統。」渡辺哲朗指出。
下一階段,Line要將ML函式庫擴充方式也標準化和自動化,建立一個機器學習模型的基礎框架,內有一套可共用的基礎程式碼配置檔。
專案團隊中的資料科學家只需要添加額外的程式碼或者是這次專案特殊的配置設定資訊就可以建立新處理流程的模型,來加速建立新模型的速度,未來還要打造一套Auto-persona API,能用來處理所有用戶的屬性預測,自動產生各種服務的使用者屬性預測。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10


2026-02-06

2026-02-10