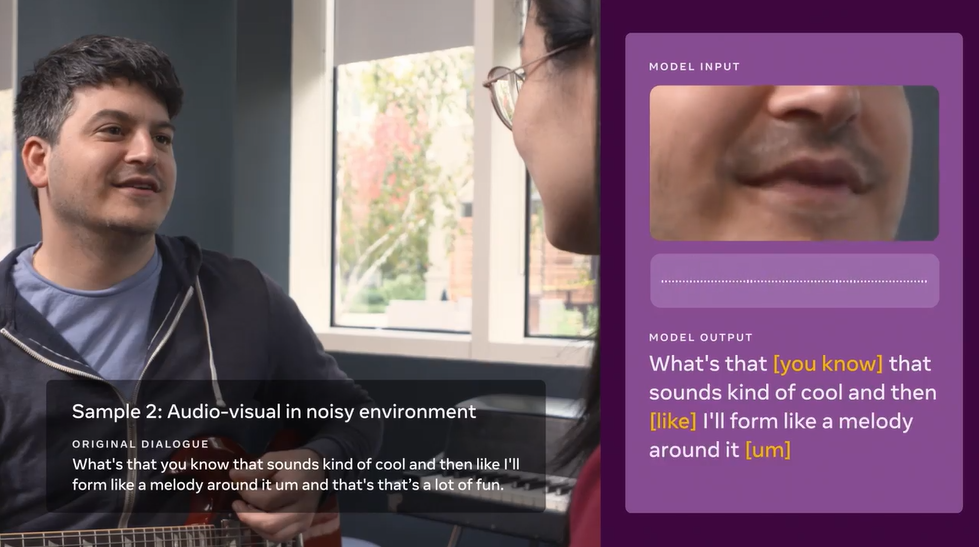
Meta AI研究院發表一款預訓練模型AV-HuBERT,能根據影片的語音和人物唇齒變化,來辨識人物所說的話語。
Meta AI研究院
重點新聞(0107~0113)
Meta AI研究院 讀唇語 NLP
會聽也會讀唇語!Meta AI研究院開源新模型讓語音辨識更精準
Meta AI研究院發表一款新語音辨識預訓練模型AV-HuBERT,不僅能聽人說話,還會讀說話者的唇形,來判斷語句,提高辨識精準度。進一步來說,AV-HuBERT是一款自監督學習框架,也是第一個融合語音分析和唇形判讀的多模態模型,可從非標註資料學習。而且,AV-HuBERT只用十分之一的標註資料,準確率就比現有最好的語音-視覺辨識模型高上75%。
所謂多模態是指,能同時處理不同類型資料的模型,如語音、影像或影片等。以AV-HuBERT來說,Meta AI研究院使用了說話者語音和唇形變化的影片資料集來訓練模型,讓模型同時處理語音和影片訊息,這個方法,讓模型甚至只需少量未標註資料(也就是未附上字幕的影片)就能完成預訓練。
一旦模型學會其中的結構和相關性,就能以少量的標註資料來學習其他任務,甚至是另一個語言。而AV-HuBERT這種自監督的方法,能幫助開發者打造更多語言的抗噪自動語音辨識(ASR)系統,像是理解力更接近人類的語音助理,可用於手機和AR眼睛,不論周遭環境多吵雜都能理解人類語音。(詳全文)
百度 跨模態 ERNIE-ViLG
百度推出中文界最大跨模態圖文生成預訓練模型
百度發表一款跨模態圖文生成模型「文心ERNIE-ViLG」,參數量達100億個,號稱是中文最大的多模態模型。團隊指出,近年來,電腦視覺和語言預訓練模型大幅提高了圖生文的表現,但對大規模的文生圖合成任務來說,仍有待加強。
於是,他們以Transformer架構為基礎,打造一套統一的雙向預訓練模型ERNIE-ViLG,利用自迴歸演算法和來對圖像生成和文字生成這兩任務統一建模,提高不同模態(即圖、文)的語義對齊關係,進而提升圖文生成的精準度。在表現上,這款模型可根據文字敘述生成單一物件圖像,像是一隻呆萌的哈士奇,也能生成複雜場景,如沿著鐵軌行駛的黃藍相間火車,甚至能產生想像中的場景,如吟遊詩貓。此外,模型也能根據圖片產生圖說,如看圖產生「牆角數枝梅的描述等。
這款ERNIE-ViLG模型只是百度文心大模型應用的其中之一,百度在上個月,揭露了自家大模型企業級AI服務藍圖,以EasyDL開發平臺和BML大模型開發平臺,來分別提供入門級開發服務和全功能開發服務,接著由文心大模型作為驅動,包括文心NLP大模型、CV大模型和跨模態大模型,來提供產業專屬的NLP服務(如醫療、金融、對話式)、OCR服務、圖文生成服務。(詳全文)
iPad AR資料集 室內3D場景
全用iPad和專業光達掃描儀拍攝!蘋果打造最大的室內3D場景AR資料集
蘋果ML研究團隊發布一套AR開發資料集ARKitScenes,專門收錄各種真實世界的室內3D場景,使用自家內建光達掃描儀的iPad搭配專用光達掃描儀Faro Focus S70拍攝而成,這是目前最龐大的RGB-D室內場景資料集。
蘋果表示,不論是真實還是合成的,目前AR資料集以RGB-D影像為主,但這得仰賴具RGB-D感測器的裝置來拍攝,雖然市面上已有這類工具,但要大規模收集資料、且具基準值(Ground truth)仍然是個挑戰。
這款資料集包含5,048個RGB-D序列,涵蓋1,661種不同場景,不僅比現有最大的室內資料集大了3倍,還提供高品質的基準值。這個資料集可用於兩種下游任務,包括3D物件偵測和顏色導向的深度圖像放大(Deep upsampling)。這個資料集,也為3D物件偵測任務提供標註資料,像是17種家具類型的3D物件邊界框。(詳全文)

除錯偵測 自監督學習 微軟
微軟用自監督AI抓程式碼臭蟲,效能提高3成
微軟發表自家研究成果,利用自監督學習打造一款AI出錯系統BUGLAB,能揪出程式碼字裡行間的錯誤,還能修復問題。進一步來說,BUGLAB包含兩套模型,一套用來偵測程式碼中的錯誤並修復,另一套用來產生錯誤的程式碼,來訓練模型的偵測力。為測試效果,微軟研究院團隊也自建一套Bug資料集PYPIBugs,累積了2,374個真實錯誤。結果發現,BUGLAB偵測錯誤的表現比現有方法提高了30%,而且還發現了19個先前未知的開源軟體程式碼錯誤。(詳全文)
![]()
歐盟 超級電腦 Exascale
歐盟計畫砸1.5億歐建超級電腦,可望成全球第2快
歐洲計畫投1.5億歐元,來打造一座近Exascale等級的超級電腦。這個計畫由歐洲高效能運算聯合協會(EuroHPC JU)發起,他們在去年12月公布一份招標文件,將採購近Exascale(pre-exascale)的高階超級電腦,也就是運算速度超過100 Petaflops、但小於1 Exaflop。
這臺超級電腦名為MareNostrum5,旨在強化醫藥研發、疫苗開發、病毒擴散模擬及AI與大數據處理應用,來促進歐洲醫療研究。這座新超級電腦也將支援傳統HPC應用,像是氣候研究、工程、材料科學及地球科學等領域。文件指出,MareNostrum5浮點運算速度至少可達205 petaflops,而且電腦運算將全部採用潔淨能源,並使用熱源再利用技術。打造完成後,MareNostrum5可望擠下2021年11月公布的Top500中第2、3名,也就是美國能源部的2座超級電腦Summit及Sierra。(詳全文)

Python TIOBE 程式語言
Python再次奪榜,拿下TIOBE年度程式語言
Python不只是AI開發的熱門程式語言,也是許多程式開發的愛用語言。Python繼2020年來,再次獲得2021 TIOBE年度程式語言獎,是過去一年中,評分成長最多的程式語言。這次C#差點有史以來第一次拿到這個獎項,但Python得分在上個月超過了C#,成為最終獲獎者。
Python在2021年的表現讓人印象深刻,從年初TIOBE Index第3名,一路追趕超過Java和C,成為第1名,而且持續往上,目前比第2名C的評分高超過1%,雖然離Java在2001年的巔峰26.49%還有一段距離,但官方提到,Python在許多領域都已經成為標準程式語言,他們相信Python仍會繼續成長。(詳全文)
Nvidia 自駕車 Drive Hyperion 8
Nvidia拓展自駕版圖,由系統駕駛的無人卡車將上路
Nvidia推出最新的自駕車平臺Drive Hyperion 8,在近期舉辦的全美消費型電子大展CES 2022上,揭露更多合作進展。最新一代的自駕車平臺,擁有12個先進的環繞攝影鏡頭、12個超音波裝置、9個雷達、3個內部感測攝影機,還有一個前置光達。
進一步來說,Drive Hyperion 8的冗餘架構設計確保安全性,當一臺電腦或感測器故障時,還有另一個備用可替補,確保自駕車輛能安全抵達目的地。不少中國電動汽車公司已採用該平臺,自駕計程車服務Cruise、Zoox、滴滴出行、Volvo、Navistar和Plus等卡車運輸服務,也都開始採用Drive Hyperion 8。無人卡車運輸公司TuSimple,也宣布將採用Drive Hyperion和DRIVE Orin系統單晶片打造無人卡車車隊,建立自動貨運網路來滿足大量卡車運輸需求。(詳全文)
圖片來源/Meta AI研究院、百度、蘋果、微軟、IBM、Nvidia
AI趨勢近期新聞
1. Coqui釋出零樣本文字轉語音模型YourTTS,較傳統TTS模型使用更少訓練資料集
2. 微軟與高通合作開發AR眼鏡專用晶片
3. Avalanche發布可加速AI模型訓練的低程式碼工具hAIsten AI
資料來源:iThome整理,2022年1月
熱門新聞

2026-02-13

2026-02-13

2026-02-13

2026-02-13

2026-02-13

2026-02-13