Meta在自我監督學習技術上,取得最新進展,其所開發的Data2vec,是第一個適用於多模式的高效能自我監督演算法,可以分別應用於語音、圖像和文字,效能比過去僅針對電腦視覺和語音的演算法更好,並且在NLP任務也具有一定的水準。
研究人員提到,現在大多數的人工智慧技術,仍然是以監督學習作為基礎,必須使用標記資料。不過有許多人類希望機器人做的事情,不可能收集到標記資料,像是雖然目前有許多研究人員,在收集英語語音和文字,來創建大規模標記資料集,但對於地球數以千計的語言來說,這種方法並不可行。
但自我監督技術,能夠讓電腦自己觀察世界,並且弄清楚圖像、語音和文字的結構,Meta提到,對於不用明確教導分類圖像,或是理解口語的機器,可擴展性高上許多。
但現在自我監督學習的研究,幾乎都集中在同一種模態上,Mata舉例,像是文字,研究人員訓練模型來填補句子的空白,語音模型則需要預測語句中缺失的聲音,對電腦視覺任務而言,模型要從多張圖像裡,找到更為相關的照片。
演算法在不同的模態使用不同的處理單位,視覺是以像素或是視覺標記為預測單位,文字是單字,而聲音則是音訊波形等。演算法設計會與特定的模態關聯在一起,演算法底層的實作也不相同。
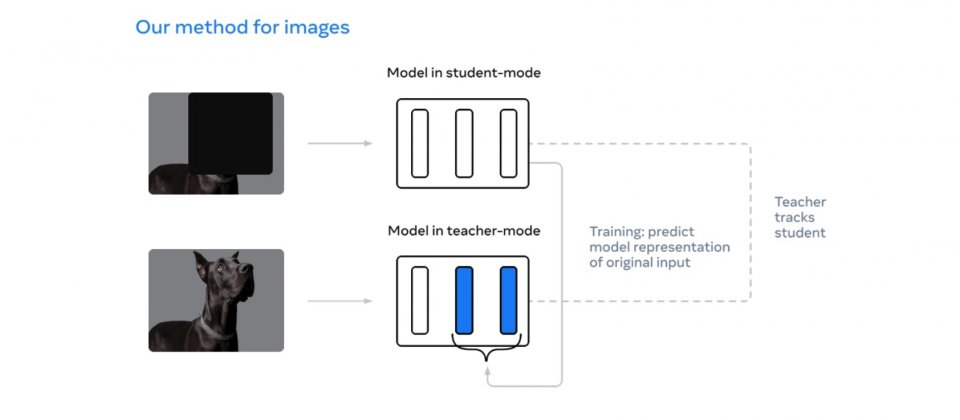
而Meta最新開發的Data2vec則簡化了這個麻煩,無論模態為何,能夠對不同的輸入資料,預測各自的表示(Representation)。這些表示為神經網路的分層,而不是單詞或是波形,這消除了學習任務中對特定模態目標的依賴。
Meta的方法是使用一個導師網路,計算圖像、文字和聲音中的表示,接著遮蔽部分輸入,要學生模型重複該過程,並且預測導師網路的潛在表示,學生模型必須在只看過部分資訊的情況下,預測完整輸入資料的表示。導師網路和學生模型相同,但權重略為過時。

Meta使用ImageNet電腦視覺基準來測試Data2vec,在一般的模型大小中,Data2vec比現在所有方法表現都還要好,語音上的效能表現,更勝於wav2vec 2.0或HuBERT,在文字方面,效能與BERT重新實作的版本RoBERTa相同。
官方提到,Data2vec代表了一種新的自我監督學習範式,能夠處理多模態,而非僅單一模態,而且Data2vec也不仰賴對照學習(Contrastive Learning)或是重建輸入的範例。
因此Data2vec除了能夠加速人工智慧的發展,也更加能夠建構無縫學習周圍環境的各種機器,使得人工智慧更具適應性,並擁有執行更多任務的能力。現在Meta對外開源程式碼以及預訓練模型,讓其他研究人員可以接續Meta的研究。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10