Google雲端在其語音轉文字API(Speech-to-Text API,STT)採用Conformer新模型,以提高STT所支援23種語言和61種區域口音的語音辨識準確性。新模型可能與現有模型的功能略有不同,不過皆提供相同的穩定性和支援。
Google提到,這是一項重大技術改進,使用當前最新的機器學習技術,是他們在語音辨識神經序列到序列模型研究8年來的階段性成果,其經過大量研究和最佳化,使模型能夠適用於不同的用例、噪音環境,並提供最佳的結果。
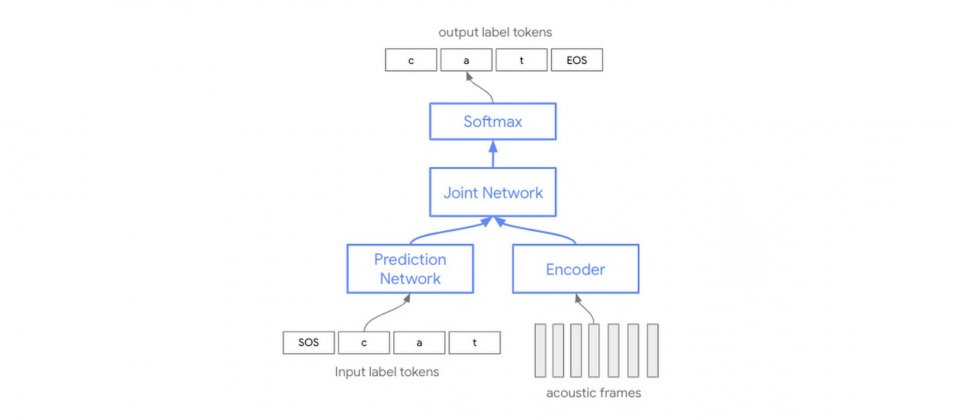
Google解釋了新模型與當前模型的不同,過去自動語音辨識技術都是基於單獨的聲音、發音和語言模型,這三個單獨的元件會獨立訓練,最後組裝在一起進行語音辨識,而Conformer新模型,則是單一神經網路。
與過去需要組合三個獨立模型的方法不同,Conformer模型能夠更有效地使用模型參數,由於這個架構是帶有卷積層(Convolution Layer)的Transformer模型,因此才稱為Conformer,該架構能夠捕捉語音訊號中的區域和全域資訊。
開發者現在使用STT API可立即看到新模型所帶來的品質改進,雖然用戶仍然可以透過調整模型,來改進模型效能,但是Conformer新模型不需要用戶進行任何動作,就能明顯感覺品質提升。
新模型支援更多不同類型的語音、噪音和聲音條件,使得用戶可以將語音技術嵌入應用程式中,並在更多環境產生更準確的輸出。智慧應用程式的使用者,將可以自然地用更長的句子,跟應用程式互動,不需要擔心語音能否被準確擷取。
用戶只要在使用STT API時,添加新標籤latest long和latest short,便可以存取最新的Conformer模型,latest long針對影片等應用設計,可以處理長篇語音,而latest short則是用於命令或是短語上,能提供更好地品質和低延遲。
熱門新聞

2026-02-11

2026-02-09
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10