DBS
原著:Samarth Agarwal, Team Lead, Data Scientist/DBS Transformation Group
翻譯:石平
譯註:文中所稱之”我們”、”星展銀行”或”星展”皆係指新加坡星展銀行,所提及之金融服務亦為新加坡國內之服務)
原文出處:https://medium.com/dbs-tech-blog/using-semantic-search-to-drive-smart-annotations-for-chatbot-models-f317db7fd41e
隨著自然語言處理技術的發展,聊天機器人已成為客戶服務中不可或缺的一環。然而,聊天機器人的使用場景並不僅止於服務客戶。
為了提升員工的工作體驗,星展銀行導入了一套聊天機器人來回答員工們各種面向的問題,包括人資、IT、風控、通訊傳播、設備及各種支援服務。員工們能夠向聊天機器人發問,甚至提交假單、查閱法律文件、搜尋資料,或是尋求IT的支援。
星展銀行的員工聊天機器人模型
星展銀行內部的聊天機器人採用「意向分類模型(intent classification model)」,基於員工提出的問題或敘述(utterance)來判斷員工的意向。模型會分辨員工的意向,並給予相應的回覆。不論是提供相關的資訊,或是使用引導性對話(guided conversation)來解決員工的需求。
模型給予的每則回覆都有一個信賴度分數(confidence score)。經過內部評估,我們將信賴度分數低於0.4的回覆視為低信賴。低信賴度的問題將會被標記為「未知」。這些問題將被匯入「內容管理系統(Content Management System)」,委由各事業單位負責標籤(annotation)的同仁處理。加上標籤的對話將會再次被送回聊天機器人的訓練資料集,使用優化過的資料再次進行訓練。
.png)
我們所遭遇到的問題
在標籤的過程中,同仁們必須親自瀏覽所有被標記為「未知」的句子,才能夠加上標籤。這樣造成了許多不必要且重複的工作;此外,加上標籤的過程目前完全以人工方式處理。若負責的同仁對於使用者提出的問題很熟悉,那就可以快速加上標籤並送回訓練資料集,反之,則需要在冗長的意向分類表中找到最適合的一項。
有鑑於此,星展銀行卓越分析中心(DBS Analytics Centre of Excellence)的同仁John Jianan Lu、Steven Yang-Yu Tseng、Ying Yang Lee、Xuejie Zhang以及我本人在近期於KDD2021 — MLF Workshop發表的論文《Smart Annotation using Semantic Search for Employee Chatbot Platform in Financial Services》中,提出了一套更有效的「智慧標籤系統」以減輕在標籤的過程中瀏覽大量「未知對話」所造成的困擾。
智慧標籤系統的設計
這套智慧標籤系統將會基於我們所要解決的問題,利用語意檢索(Semantic Search)技術對使用者(也就是加上標籤者)提出建議,這個功能在於減少使用者重複檢查以及搜尋相關標籤的時間。以下是本系統的兩項目標:
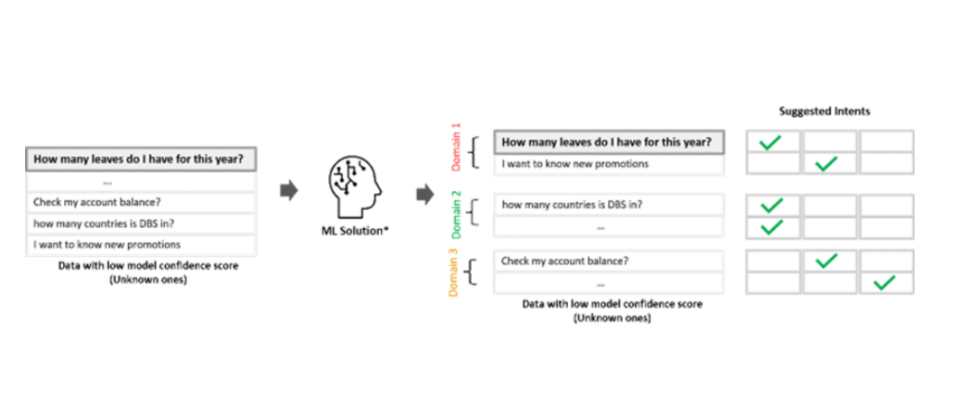
1. 將「未知對話」歸納為相對應的領域(domain),並將各領域的句子交付給相關的團隊,由於預測準確度很高,因此減少了三至四倍的工作量。
2. 提供三個意向(intent)建議給加上標籤者,藉此減少尋找潛在意向所需的時間。

實驗過程中,我們使用敘述(utterance)資料作為訓練資料(資料日期止於2020年12月),並利用已實際上過標籤的資料作為驗證資料(資料日期始於2021年1月)。聊天機器人使用的資料以下列方式做安排:
敘述訓練資料
.png)
語意檢索模型會基於接收到的對話,在訓練資料中找出最接近的敘述。在敘述資料集中,每個敘述皆標註有一個意向(intent)、一個話題(topic),以及一個領域(domain),它們被用來比較對話的相似程度,模型並藉此提出建議。
當對敘述提出前三順位的意向建議時,系統會針對結果去重複化,並提出彼此相異的前三順位意向建議。舉例來說,當使用者詢問「員工識別證」時,最相近的敘述可能皆屬於同一種類型的意向(如新員工識別證),但我們只將其視為同一種意向建議。去除重覆化的步驟,讓系統得以從所有的搜尋結果中提出三項不同的建議。
在領域預測上,各領域中與敘述最相近者,將在訓練資料中被作為建議類別。在正式環境中,若前三順位的意向建議屬於不同的領域,則所有與這些領域相關的事業單位中負責標籤的同仁,都能存取這段由使用者所輸入的對話。
成效評估
我們擷取一組標籤集,並利用以下指標來評估這套系統的成效:
1. 平均領域預測準確度
2. 前K項話題準確度:若任一前K項話題建議與事實相符,則視為正確
3. 前K項意向準確度:若任一前K項意向建議與事實相符,則視為正確
在我們的評量中,本實驗將K設為1及3。最理想的情況是能夠取得非常高的第一順位意向準確度,這樣整套流程即可自動化。然而,由於意向的條目非常多(超過一千項),加上其中一些意向之間僅存在著細微的差異,因此我們也同時評估前三順位的準確度。
每得到一個input,演算法就會找出與其最接近的前三項敘述,並取得相應的意向,如此一來就成了一個kNN(k-nearest-neighbor)問題。所以為了加快搜尋速度,我們比較了完美相符和近似最近鄰(approximate nearest neighbor)兩種方法的搜尋速度。在近似最近鄰方法下,資料集依照詞嵌入(word embedding)被切分為多個小區塊,因此即便在上百萬資料點的向量空間中,也能有效率的搜尋。但值得注意的是,近似最近鄰的搜尋結果未必完全吻合,有時相似度很高的向量也可能會被忽略,可以說是速度和準確度之間的取捨。由於我們並非處理極大量的資料,因此最終決定採用完美相符的搜尋方法。
實驗結果
實驗對照組方面,我們使用以TF-IDF為基礎的詞彙搜尋法(Lexical Search)作為基準。在我們的研究中發現,純粹以名詞作為搜索方式會得到較好的準確度。實驗使用NLTK(Natural Language Toolkit),以Penn Treebank的詞性集(tag-set)進行詞性標註(Part-of-Speech Tagging)。我們將訓練資料集進行上述整理,並對所產生的token(即單詞)依照文件頻率(document frequency)進行過濾以產生出最終的詞彙集來進行一元TF-IDF向量化(unigram TF-IDF vectorization)。修訂過後的詞彙集和逆向文件頻率權重(IDF weight)將用來處理未來輸入的資料。用以衡量兩個句子是否相似的測量方法,則是採用餘弦相似性(Cosine distance)來判定。
對照組能夠達到不錯的領域準確度,但在意向建議上表現則並不出色。
詞袋模型(Bag-of-word)會忽略句子的整體架構,並且當同樣一組詞彙使用在不同的意向或話題時也會失準。舉例來說,當搜尋潛在可能離職的員工(flight risk employee)時,若未加以考量語意,則與flight和risk等詞彙最相近的敘述,將會是關於機票(flight ticket)或是營業風險(business operational risk)等項目。
此外,我們也用驗證資料集比較了一些預先訓練好的BERT語句模型(pre-trained sentence-BERT models),如stsb-distillbert-base、stsb-bert-base、stsb-roberta-base。我們發現stsb-roberta-base在幾種BERT語句模型中的表現最好。由於是預先訓練過的模型,其表現也勝過未施加額外訓練的TF-IDF模型(即對照組)。
然而,在細部分析預訓練模型所得到的錯誤分類結果後,我們發現此類模型在屬於專門領域的對話中表現欠佳。因此,我們接著利用聊天機器人的資料來將stsb-roberta-base模型加以調整,讓它更加熟悉我們的資料集。為了調整stsb-roberta-base模型,句子們以成對的方式呈現,會被給予相似度分數。下表為產生此一相似度資料集的邏輯。
句子相似度資料集
.png)
由於具備有不同的意向、話題及領域,我們能夠較輕易的將相似的句子做分類。相似句透過排序所組成,因此並非完美相符。
此方法產生的資料量相當龐大。舉例來說,若我們僅考慮相似度為1的情況時,我們的資料集將會產生435,000組相似句子。在我們的案例中,透過抽樣方法減少相似度小於1的情況,最終產生的資料集共計約兩百萬筆。
用於訓練的資料約三十至五十萬筆中,我們優先擷取符合特定標準的資料,以利取得較複雜的相似句。判斷標準如下:
- 相似度=1者,優先取用文字重複度低者。
- 相似度<1者,優先取用文字重複度高者。
本研究使用孿生神經網路(Siamese networks)及餘弦損失函數(Cosine Similarity Loss)來優化stsb-roberta-base預訓練模型,以此減少兩個語句向量間標籤及餘弦相似度的差異。下列為訓練細節及參數:
- Data size: 300,000 sentence pairs
- Number of epochs: 2
- Batch size: 8
- Warm up steps: 10% of total steps
- Learning rate: 2e-5
.png)
本實驗使用斯皮爾曼等級相關係數(Spearman correlation)來比較優化前、後詞嵌入之間的相似度,並發現優化後的stsb-roberta-base模型表現有顯著的提升。
我們採用結合了TF-IDF向量及語句嵌入(Sentence Embedding)向量(優化後的模型)作為我們的最終搜尋方法,因為它在資料中融合了詞彙層級及語意層級的資訊。
由於TF-IDF和語句詞嵌入的向量空間維度並不相合,我們採取了以下手法:
首先,我們從訓練資料集中分別抽取出同一段搜尋文字在TF-IDF及語句詞嵌入中,透過餘弦距離找出的一組「最近鄰(nearest neighbor)」。接著我們將兩個權重參數,個別與兩個模型所產生的餘弦距離相乘,最後再相加,得出最終距離維度。
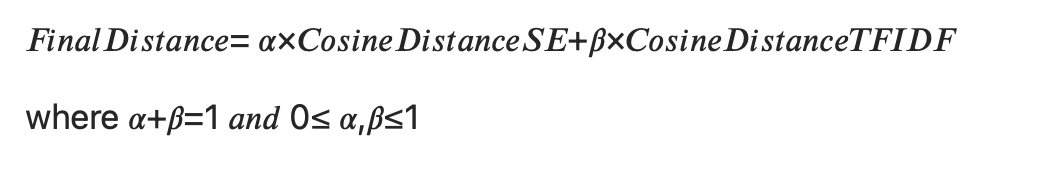
利用此最終維度距離所產生的「最近鄰」可用來找出最高順位的話題及意向建議。在我們的實驗中,將α設為0.66;β設為0.34,賦予語句詞嵌入相當於TF-IDF兩倍的權重。僅納入名詞的TF-IDF模型能讓演算法更著重在使用者感興趣的物件或產品。
這個結合兩者模型的方法在尋找相符合的話題和意向上,稍微比單純使用語句詞嵌入的方法更好。
實驗結果
.png)
錯誤分析
隨著越來越多來自不同團隊的意向和敘述陸續加入,即便提出了一套準則,仍然很難得到一份完全周延、互斥的意向及敘述清單。與此同時,最近有個很熱門觀點叫DataOps,其概念是透過改善資料本身的品質,藉此優化模型的表現。一旦完成模型,我們會分析模型中預測表現較差的部份,並提出改善策略。因此為了解決模型中的錯誤,我們使用了以下的分析方法:
1. 前三順位中主題、意向層級的精準度:找出預測表現不佳的意向,觀察模型預測出哪些意向,而非著眼於正確的解答。
2. 文字層級:檢查是否有特定文字總是表現不佳,以及在訓練資料集中有多少此一文字。
透過以上分析,我們找到以下問題,並與相關單位合作改善資料品質,以及模型的表現。
1. 不同意向中有相同的資料:同樣的一段敘述,有時會包含多種不同的意向,導致分類錯誤。
2. 進階案件:進階案件是指模型無法處理的案件,它們可能需要經由主管或人資單位審核。由於這類案件的可能性相當多樣化,模型在預測的表現比較差。
3. 新詞:某些特定領域專用字,例如系統名稱,在資料集中並不常出現,因此無法妥善地被預測。
4. Transformer模型偏見:自然語言模型對於數字及日期較敏感,例如當輸入「申請9月2日休假」時,模型將會把它和其他提到日期的敘述視為具有更高的相似性,即便其他的敘述與申請休假無關。這可能與模型在訓練時針對資料集的偏見有關。
影響
藉由導入智慧標籤系統,我們在HR和IT領域等佔使用者提問比例較大的問題中減少了40–60%上標籤的工作量。此外,在較少被詢問的領域(如法遵),即便需要上標籤數量一樣,仍然減少了90%的工時。
未來發展
透過本研究,我們展示出基於語意檢索的智慧標籤系統能夠有效的被利用在聊天機器人上。結合文字及詞嵌入(針對個別領域進行優化)的方法比其他方法表現更優異。DataOps策略在處理大量文本資料上,能更有效改善資料品質,以及模型表現因此變得更好。透過改善資料品質,我們預估模型準確度能提升10%以上。
整體來說,使用語意檢索方法比起傳統文字分類方法,有以下三層優勢:
1. 它能被使用在較少出現的意向上,傳統文字分類方法則會剔除較少出現的敘述。
2. 即便沒有重新訓練,模型也能對含有新詞彙的句子進行相當程度的預測。
3. 由於系統提出多個順位的高相似度結果提供觀察,讓模型具有更高的可解釋性,亦提供我們更多檢討模型為何失敗的線索。
最後提出本系統的未來計畫以及如何擴展目前的解決方案:
1. 多語言模型:開發橫跨多語言的模型,例如中文及印尼文模型。如此能幫助我們將本系統擴展到星展銀行位於其他國家及地區的使用者。
2. 加入交互編碼(Cross-encoder)模型層來重新排序:研究論文顯示,交互編碼模型藉由在第一階段得到的句子上再加入一層重新排序的步驟,能得到更好的表現。這是因為交互編碼器在預測相似度時是同時參考所有輸入的問題。
參考資料
1.Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova, 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), (Jun 2019), 4171–4186.
2.S ́ebastien Harispe, Sylvie Ranwez, Stefan Janaqi, Jacky Montmain and Ecole des mines d’Al`e, 2015, Semantic Similarity from Natural Language and Ontology analysis, Synthesis Lectures on Human Language Technologies, (May 2015).
3.Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer and Veselin Stoyanov, 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv:1907.11692.
4.Nils Reimers and Iryna Gurevych, 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv:1908.10084.
5.James Pustejovsky and Amber Stubbs, 2012. Natural Language Annotation for Machine Learning. O’Reilly Media, Inc, (Oct 2012).
6.Ting Liu, Andrew W. Moore, Alexander Gray and Ke Yang, 2004. An Investigation of Practice Approximate Nearest Neighbor Algorithm. Neural Information Processing Systems, (Dec, 2004).
7.Luyu Gao, Zhuyun Dai, Tongfei Chen, Zhen Fan, Benjamin Van Durme and Jamie Callan, 2021. Complementing Lexical Retrieval with Semantic Residual Embedding. arXiv:2004.13969, (Apr 2021).
8.Andrew Ng. Machine Learning Yearning (Draft Version). https://d2wvfoqc9gyqzf.cloudfront.net/content/uploads/2018/09/Ng-MLY01-13.pdf
9.Nils Reimers, 2021. Sentence Embedding Models. Retrieved From https://www.sbert.net/docs/pretrained_models.html#sentence-embedding-models
免責聲明和重要通知
本文章(英文)係由DBS LTD提供並經星展銀行(台灣)(下稱「本行」)翻譯為中文,僅供參考,本行及DBS LTD不對使用本文章所引起之任何損失或損害負任何責任。如您有任何疑問或欲參考本文章而為行事之依據,本行建議您諮詢您的專業顧問之意見,以保障您的權益。非經本行之事前書面同意,任何人不得對本文章為複製、轉載、引用、抄襲、修改、散佈或為任何其他方式之使用
熱門新聞

2026-02-09

2026-02-10

2026-02-06

2026-02-10

2026-02-10

2026-02-09

2026-02-10
