重點新聞(0422~0428)
推特 GitHub 演算法
推特在GitHub新添演算法公開庫,但又刪掉了
伊隆馬斯克買下推特後,就公開發表要開源推特演算法,提高透明度,像是揭露推特如何排名使用者的推文、如何推播推文給不同使用者,以及為何高度曝光某些推文,而另一些卻不見天日。日前,推特開發者就在開源平臺GitHub上,開設一個名為the Algorithm的程式碼公開庫,然而裡面連一行程式碼都沒有。沒多久,這個公開庫就被刪除了。
其實,推特多年來也開源不少專案,像是R語言開發的異常偵測系統、輕量影片處理函式庫、互動式視覺化工具、RPC服務基準測試等。但這次,外界認為,推特開發者並不想完整開源自家演算法。(詳全文)
北醫 肺癌 NLP
首個肺癌醫病決策共享平臺!北醫大肺癌AI包辦診斷用藥和預後評估
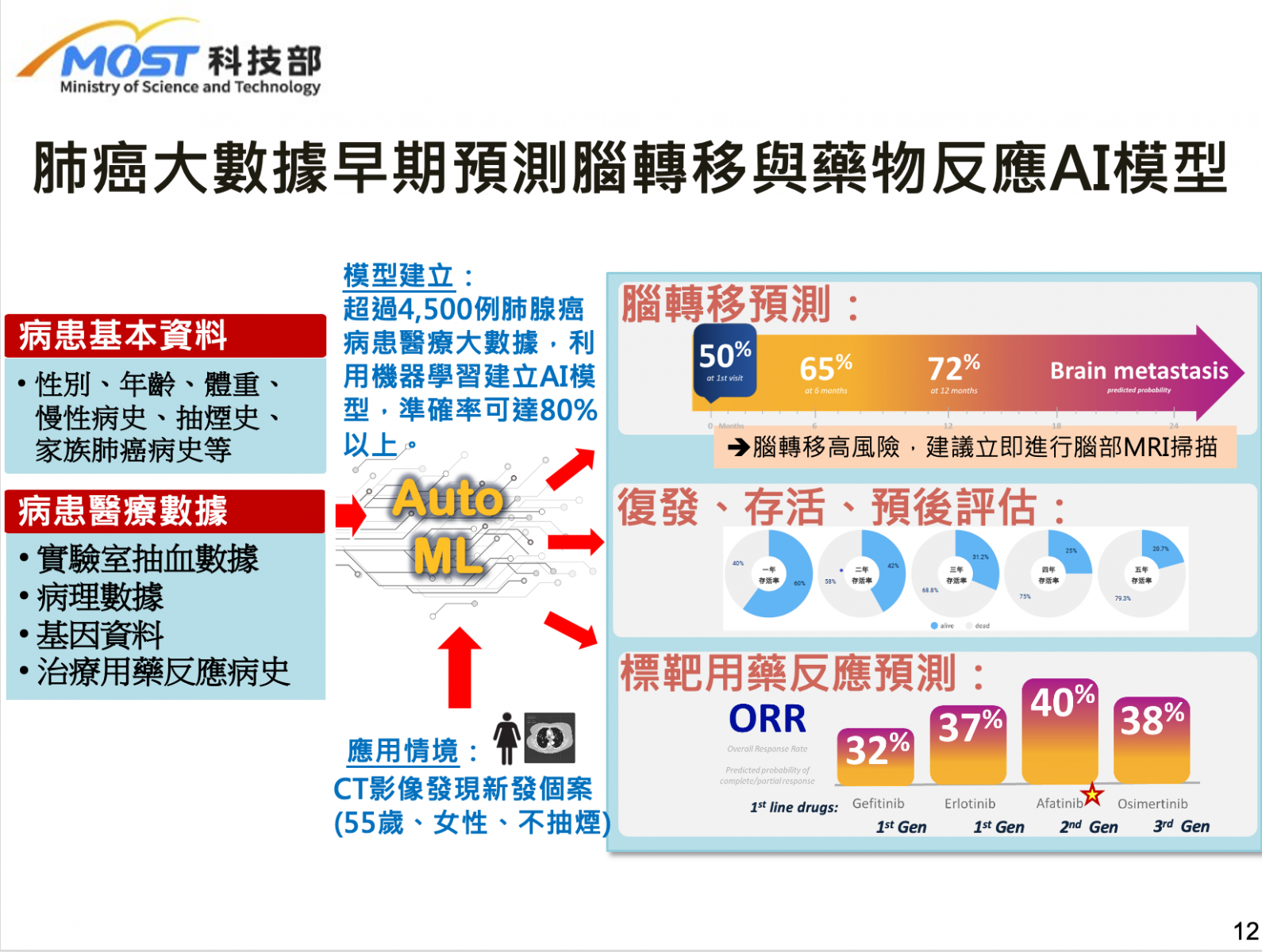
北醫大以影像辨識和自然語言處理(NLP)技術打造肺癌臨床智能決策輔助系統,根據臨床實際流程,提供醫師與病患診斷、用藥、預後評估,是首個肺癌醫病共享決策平臺。該平臺包含3大模型,首先是電腦斷層肺癌基因突變預測模型,可自動從300多張電腦斷層影像自動偵測腫瘤並標示,也能判斷腫塊類型和可能的基因突變,提供肺結節處理建議。
團隊也將電腦斷層預測結果整合臨床大數據,透過肺腺癌病患醫療大數據和AutoML方法建立腦轉移、預後與藥物反應預測模組,當電腦斷層影像發現新發個案時,可立即預測腦轉移風險和選藥建議。
再來,北醫大將與雲象科技研發的全玻片數位病理判讀技術,延伸開發出肺腺癌病理基因突變預測選藥模型,來快速自動標註病灶,並預測最常見基因的突變狀態,來提早精準用藥。最後,團隊也利用NLP開發出病理報告自動判讀選藥檢疫系統和肺腺癌全基因用藥建議模型,只要輸入一份病人病理報告,就能得到存活率較高的健保與自費用藥推薦,且整合治療效果和存活期資訊,篩選出與病患相似且預後最佳的選藥治療建議。對於晚期肺癌無法開刀或已轉移復發的病人,系統還會自動將病人狀況媒和全球新藥試驗場域。(詳全文)
聯合學習 高雄 智慧醫療
聯合學習又有新進展!高雄聯合學習醫療聯盟成立
臺灣聯合學習又有新進展,高醫附醫、高雄長庚、高雄榮總、義大醫院等4家醫院聯手成立高雄聯合學習智慧醫療聯盟,要針對在地臨床需求,發展腦心重症、就醫、智慧照護和健康關懷等領域的聯合學習專案。
該聯盟關鍵推手臺灣人工智慧實驗室(Taiwan AI Labs)透露,將建立跨院聯合驗證確效平臺,來評估軟體醫材成效,加速智慧醫材SaMD發展與落地。高雄聯合學習智慧醫療聯盟是自去年臺灣聯合學習產業大聯盟成立以來,首個落地的產業聚落案例,與此同時,臺灣人工智慧實驗室也在高雄成立研發總部籌備處,預計擴編百人研發團隊,要與當地學界如中山大學、成功大學,來聚焦動態分潤演算、聯合學習資訊安全、智慧醫療聯網、前瞻醫療器材研發等領域發展。(詳全文)

Google 語音轉文字 Conformer
Google語音轉文字模型通吃3種任務,現已嵌入SST服務
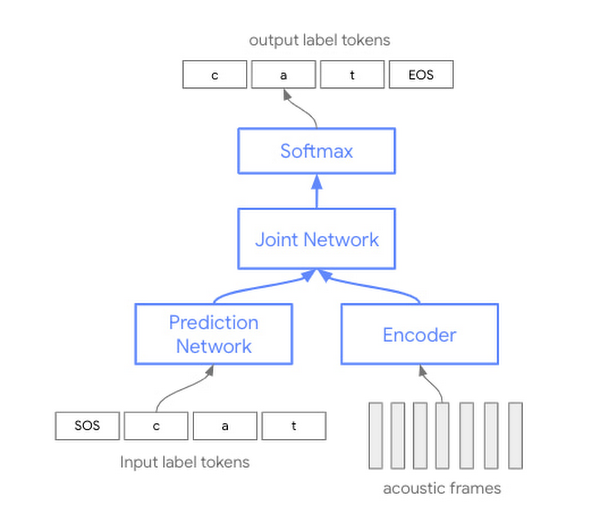
Google雲端在語音轉文字API(STT)服務中,採用Conformer新模型,提高23種語言和61種區域口音的語音辨識準確性。過去,自動語音辨識技術是基於單獨的聲音、發音和語言模型,並各自單獨訓練這3類模型,最後再組裝起來辨識語音。但Google的Conformer新模型,則是單一神經網路,通吃這3種任務。
Conformer架構是帶有卷積層的Transformer模型,可捕捉語音訊號中的區域和全域資訊。用戶使用STT API時,添加新標籤latest long和latest short,就能存取最新的Conformer模型,分別針對影片等應用設計和命令或短語上。新模型能支援更多類型語音、噪音和聲音條件,讓用戶可將語音技術嵌入應用程式中,這讓應用程式的使用者,能用更長的句子與應用程式互動。(詳全文)
AWS 資料集 自然語言處理
AWS開源51種語言AI訓練資料集和程式碼
Amazon釋出一套MASSIVE資料集,涵蓋51種語言,開發者可用來訓練虛擬助理。Amazon表示,到了2023年,全球會有80多億個AI虛擬助理,還有1億多臺智慧喇叭,但大部分的虛擬助理都只使用1種或少數幾種主流語言。
為解決問題,NLP界發展出大量多語自然語言理解(MMNLU)模型。透過學習跨語言的共享資料表徵,模型可將從豐富訓練資料的主流語言學知識,轉移到資料稀少的語言上。為促成MMNLU的出現,Amazon釋出MASSIVE資料集,內含跨51種語言加註過的100萬條語句或單詞,以及程式碼。資料集包括訓練、驗證和測試資料,後者則提供MMNLU模型的執行範例。(詳全文)

歐盟 數位服務法 內容平臺
平臺業者得提供推薦演算法!歐盟揭露數位服務法新要求
歐盟近期公布《數位服務法》(Digital Services Act)條文,規範內容平臺需提供2種以上的內容推薦系統,且歐盟有權存取內容平臺演算法,若不合規定,最高可對違法者裁罰6%全年營收。
《數位服務法》今年1月通過,並展開會員國協商,這次要求內容平臺業者得負更多責任,比如更快移除不良或非法內容。這次協商影響最大的規範是,歐盟及會員國可存取超大型平臺的演算法,這些平臺也必須對用戶告知內容推薦系統的運作,且用戶可以有至少一個非依用戶側寫(profiling)推送內容的系統 。不過該法條文尚未底定,歐洲議會代表將於5月前往美國討論這項新法,再由歐洲議會、歐盟理事會做最後許可。一旦完成並公布,將在20日執行,並在2024年上路。(詳全文)
鴻海 Azure 對抗式學習
鴻海用高速雲平臺加速AI模型訓練
鴻海去年開始啟動雲原生技術開發、混合辦公場域建立、核心系統上雲布局全球等三大戰略,近日鴻海研究院分享成果,藉Azure雲平臺高速算力,取得不少AI研究突破。
比如,他們將對抗式模型的訓練時間,從3小時縮短到5分鐘,用來強化自駕車AI系統的安全性。又或是,鴻海用高速平臺縮短高解析度非監督式影像轉換模型,能在硬體資源有限的情況下生成高解析度影像,作為更擬真的自駕車場景訓練資料。此外,他們也加速自監督預訓練模型的開發,將巨量未標註的街景資料用來訓練預訓練模型,之後供不同專案使用,依任務特性,以少量資料微調即可。
鴻海也研究自監督虹膜影像分割技術,也就是以無人工標註資料訓練模型,來更準確分割虹膜,提到辨識準確率。該技術也能用於自駕車的街景影響分割,進而訓練出更準確的模型。最後,鴻海也成功加速研發出符合醫療器械促進協會(AAMI)的即時、連續性血壓偵測AI,模型訓練時間比先前快上400倍。(詳全文)
圖片來源/Disclose.tv、北醫大、高雄市政府、Google、AWS
AI近期新聞
1. 微軟資料治理產品重整為Purview
2. Google發表表格文字辨識新模型
資料來源:iThome整理,2022年4月
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-09

2026-02-10


2026-02-10

2026-02-06