
中國購物平臺美團近日發表YOLOv6物件偵測模型,改良了類神經網路的骨幹、頸和頭部,速度和準確度都比歷屆YOLO系列模型要好。
美團
重點新聞(0624~0630)
各大科技巨頭近日紛紛釋出新模型,比如美團發表新一代物件偵測模型YOLOv6,速度和準確度勝過以往YOLO系列模型,而Meta開源660億參數大型語言模型OPT-66B,同時還釋出完整的部署日誌,堪稱AI圈內第一人。另一方面,俄羅斯最大網路公司Yandex首次開源千億參數語言模型,Google則趁勝發表另一款文生圖模型Parti。除了AI模型,最近也出現重量級AI程式撰寫工具如GitHub的Copilot,AWS也不甘示弱釋出CodeWhisper預覽版。為促進AI民主化,中研院院士孔祥重日前呼籲各界應著重訓練資料、硬體加速和建立產業專屬AI軟體平臺。
YOLOv6 物件偵測 美團
物件偵測模型YOLOv6新版現身,再次打破速度和準確度天花板
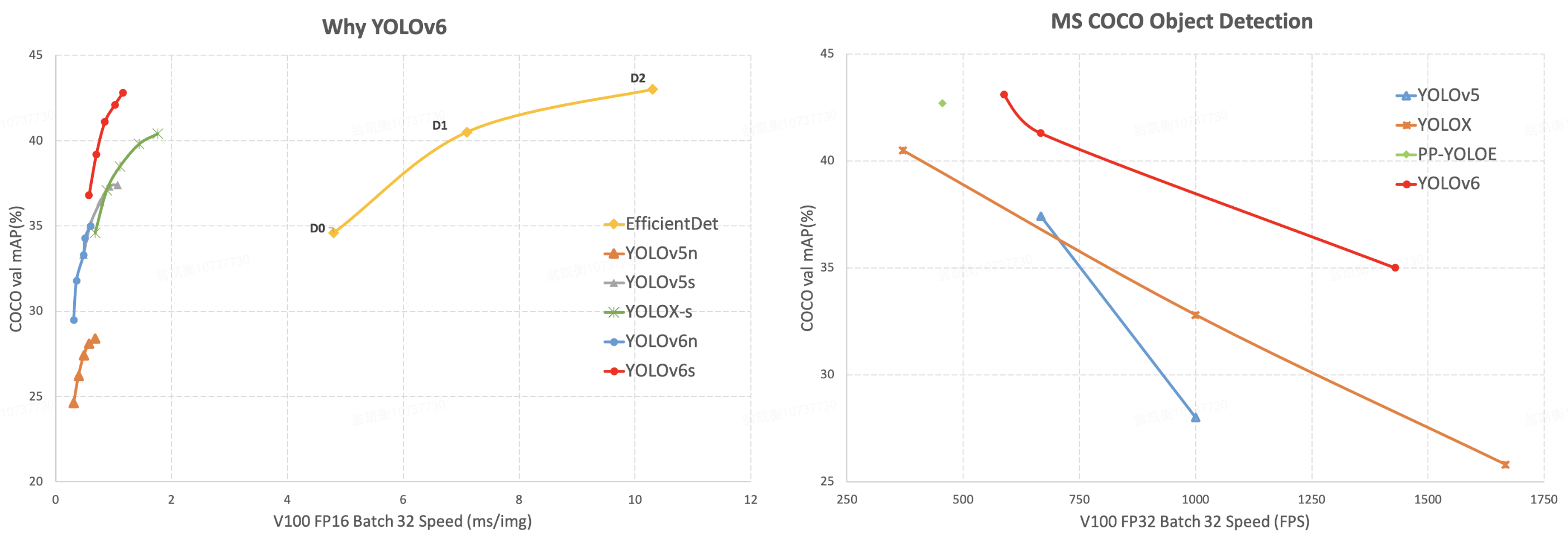
YOLO系列的最新物件偵測模型YOLOv6問世了,最先釋出的nano版在COCO資料集測試中,拿下35.0%平均精度均值(mAP),用T4顯卡的推論速度可達每秒1,242幀(Fps),s版則是43.1%mAP、每秒520幀,表現比前幾代YOLO系列模型都要好。
YOLOv6由中國購物平臺美團視覺智能研發部開發,改善了模型的訓練策略和網路結構,比如,在Backbone和Neck部分,團隊以RepVGG為基礎,設計了可重參數化、更高效的骨幹網路EfficientRep和Rep-PAN Neck,在Head部分,則設計了更簡潔有效的Efficient Decoupled Head,可一面維持精確度、一面降低一般解耦頭的額外時間成本。在訓練策略上,團隊則採用Anchor-free無錨方法,並以SimOTA標籤分配策略和SIoU邊界框迴歸損失,來強化偵測精確度。
在部署方面,YOLOv6支援GPU(TensorRT)、CPU(OPENVINO)、ARM(MNN、TNN、NCNN)等不同平臺的部署,簡化一般部署時的配置工作。他們也預告,接下來將開源YOLOv6 m/l/x等大小的模型和量化工具。(詳全文)
Meta 語言模型 Transformer
Meta開源660億參數的超大型語言模型,打破先例附上所有部署日誌
Meta最近開源具660億參數的大型自然語言預訓練模型OPT-66B,以及所有OPT-125M到OPT-66B等8種系列基準模型的部署日誌,打破先例成為AI圈內首家發布模型、論文和完整註釋的科技巨頭。
進一步來說,Meta在5月發表了與GPT-3相當的大型Transformer模型OPT-175B,參數量為1,750億,但非常省能源,只產生七分之一訓練GPT-3所需的碳足跡。OPT-175B雖只支援非商業性授權,但在發表的同時,Meta也在最近補上125M、350M、1.3B、2.7B、6.7B、13B、30B和66B版本的模型部署參數,並在推特上說明。(詳全文)
AI民主化 產業專屬平臺 訓練資料
孔祥重:AI民主化首重訓練資料、運算系統和產業AI平臺
孔祥重日前在陳昇瑋紀念講座中指出,為了讓更多人使用AI,臺灣產業可從3大層面著手,包括納入更多元的新訓練資料、建造有效率的AI運算系統,以及發展產業專屬AI軟體平臺。
他解釋,資料驅動的AI系統先天有些限制,像是資料偏移和偏差,但納入更多新訓練資料、採用如自監督學習等方法,可打破限制、擴大AI使用範圍。再來,透過更多通用AI加速器和晶片的發展,可讓AI運算系統更有效率,降低資料在晶片間移動的成本。最後,他鼓勵各產業發展專屬的共享AI軟體平臺,比如由製造業龍頭建造一個AI軟體開發維護平臺,來讓中小型製造業管理資料、維護模型,而臺灣人工智慧學校,則可扮演專案協調和案例教學的角色,來讓更多企業使用模型。(詳全文)

Parti Google 圖生文
才剛發表Imagen逼真文生圖模型,Google再推新模型Parti
Google前陣子才發表令人驚艷、表現優於OpenAI DALL-E 2的文生圖模型Imagen,最近又發布一款新版進階模型Parti,可根據文字產生天馬行空但逼真的圖片,但模型未開源。
雖然DALLE-E 2、Imagen和Parti都以Transformer架構為基礎,但有別於前兩者採用擴散模型、可將隨機的點樣式轉換為影像,Parti使用自迴歸模型,先將一組圖片轉換為一系列代碼條目,再將輸入的字句,轉換為這些代碼條目,並產生一張圖片。Google發表的Parti有幾種版本,包括3.5億參數、7.5億參數、30億和200億參數的版本,目前仍在優化模型的不足,像是特徵混合、錯誤的物件計數等。(詳全文)

GitHub Copilot 程式撰寫
GitHub正式推出AI寫程式幫手Copilot,月租10美元、學生免費
GitHub正式上線AI程式自動撰服務GitHub Copilot,每月訂閱費用為10美元,年費則是100美元,學生與熱門開源專案的維護者可免費使用。GitHub Copilot是GitHub與OpenAI共同開發的服務,底層技術為OpenAI打造的AI系統Codex。該系統以Transformer為基礎,以大量程式碼和自然語言訓練而成,可同時理解程式和人類語言,並根據工程師撰寫的程式碼,提出整行程式或整個函式的撰寫建議。
在經歷過一整年共120萬名開發者的預覽後,GitHub Copilot現可整合到Neovim、JetBrains IDEs、Visual Studio與Visual Studio Code 等開發環境。(詳全文)
Yandex Transformer GPT-3
Yandex開源1千億參數語言模型
俄羅斯最大網路公司Yandex日前開源1,000億個參數的YaLM 100B語言模型。為訓練模型,Yandex先從網路、書籍和眾多來源收集英文及俄文等17TB的資料,花了65天的時間,利用800張A100顯卡的叢集上,來訓練YaLM 100B。特別的是,YaLM也實際應用在Alice數位語音助理和搜尋引擎上,超過1年多了。
Yandex表示,大型語言模型近年來已是NLP的進展關鍵,但大型模型的訓練耗時耗力也耗大量資金,如數百萬美元,導致只有科技巨頭才能發展這種先進技術,若要這個領域快速進展,就必須允許全球研究人員、開發者來使用這些解決方案,這也是Yandex決定開源的原因,並分享訓練經驗。(詳全文)
AWS 寫程式 CodeWhisper
不只GitHub有,AWS也預覽程式撰寫AI小幫手
不只GitHub上線AI程式撰寫工具Copilot,AWS最近也預覽一項ML程式撰寫輔助服務Amazon CodeWhisper,可支援多種IDE和Python、Java、JavaScript等程式語言,可幫助學生、開發新手或資深開發人員加速開發、提高生產力。
進一步來說,AWS用開源儲存庫、自有儲存庫、API文件和論壇上數十億行程式碼來訓練CodeWhisper,可根據使用者原始碼中的游標位置、游標前的程式碼、註解及同一專案中其他檔案的程式碼,來提供建議。開發者可直接套用或客製化加工。AWS透露,預覽版的CodeWhisper支援Visual Studio、IntelliJ IDEA、PyCharm、WebStorm、AWS Cloud9,以及Python、Java、JavaScript,之後會新添AWS Lambda Console。(詳全文)
微軟 負責任AI 臉部辨識
微軟公布負責任AI指導準則,將限制部分臉部辨識能力
微軟近日更新負責任AI的指導準則,6月起就會限制部分AI臉部辨識。微軟更新的準則,是2019年公布的6項AI開發及應用準則,包括公平、可靠性、隱私及安全性、包容性、透明性及權責等。最近,微軟根據新研究結果加以改良,將新版負責任AI容納三點。
首先是語音轉錄,該技術對少數族群的辨識錯誤率偏高,微軟將擴大訓練樣本多元性。再來是AI聲音模擬和臉部辨識服務,微軟Azure AI的神經網路語音服務可用AI模擬出原人物相仿的聲音,但可能被用作Deepfake影片,AI臉部辨識亦是如此,微軟將納入多層控管框架,限制可使用的客戶、明確定義使用情境。最後則是限制Azure Face臉部辨識服務,微軟將拿掉這項服務推論情緒狀態,以及辨識性別、年齡、微笑、臉部毛髮、頭髮及化妝的能力。(詳全文)
圖片來源/美團、孔祥重、Google、GitHub、AWS
AI近期新聞
1. AWS機器學習基準值服務SageMaker Ground Truth也支援合成資料了
2. Amazon展示首款全自動化行動機器人Proteus
資料來源:iThome整理,2022年6月
熱門新聞

2026-02-11

2026-02-12
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-09

2026-02-13


2026-02-10