Meta在早前發布了Data2vec模型,這是同時以同一方式學習三種不同模式,分別為語音、影像和文字的高效能自我監督演算法,而Meta現在釋出Data2vec 2.0,這個新的演算法更快更有效率,速度達當前熱門電腦視覺自我監督演算法的16倍。
官方提到,近期人工智慧技術的突破,都是採取自我監督式學習,但是當前演算法有幾個明顯的限制,包括通常只能用於單一模式,像是圖像或文字,並且需要大量的運算能力。這顯然與人類的學習方式不同,人類的學習效率更高,並且習慣從不同類型的資訊中學習,而不僅仰賴文字、 語音或其他單獨的學習機制。
Data2vec演算法便是Meta在這方面的突破,使得文字理解等技術更容易應用在圖像分割或是語音翻譯等應用,而Data2vec 2.0新演算則是朝這個目標更進一步,效率大幅提升,在能夠以16倍的速度,達成與現有熱門電腦視覺自我監督演算法相同準確度。
研究人員解釋,自我監督學習的想法,是讓電腦藉由簡單地觀察世界,來學習圖像、語音和文字結構,而這產生了諸如語音模型Wav2vec 2.0、電腦視覺模型MAE,以及用於自然語言處理模型BERT,但是這些系統對於運算的要求很高,訓練大型模型需要龐大的GPU運算資源。
Data2vec 2.0與Data2vec演算法類似,針對資料的脈絡化(Contextualized)表示進行預測,而非只是圖像的畫素、文字段落或是語音的單音。研究人員提到,這和大多數的演算法不同,這代表演算法將整個訓練範例納入考量,像是考量整個出現Bank這個單詞的句子,就更容易了解其正確含義,由於脈絡化目標帶來更豐富的學習任務,因此Data2vec 2.0也就比其他演算法學習的更快。
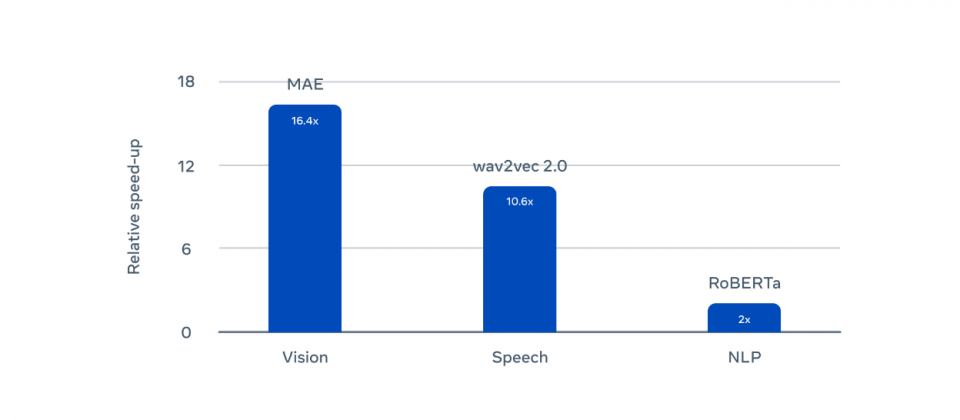
研究人員使用基準測試Data2vec 2.0,測試其在電腦視覺、語音和文字任務的表現,了解新的演算法與其他模型的差異。研究人員以ImageNet-1K圖像分類基準評估Data2vec 2.0,發現準確度可媲美MAE,但是速度要快16倍,給Data2vec 2.0更多時間也就能達到更高的準確度,但是仍然比MAE快得多。
語音方面則是使用LibriSpeech語音辨識基準進行測試,Data2vec 2.0執行速度是Wav2vec 2.0的11倍以上,達類似準確度。自然語言處理任務則使用GLUE基準測試,其以RoBERTa一半的時間,獲得相同的準確度。
熱門新聞

2026-02-13

2026-02-13

2026-02-13

2026-02-13

2026-02-13

2026-02-13

