
攝影/余至浩
雲端服務龍頭AWS每年冬天都會在美國拉斯維加斯舉行年度全球用戶大會,但受疫情衝擊,2年前改為全線上進行,儘管相隔一年,隨即於2021年恢復實體舉辦,但實際參加人數明顯不如往年,甚至不到全盛時期一半,許多人都改線上參加,使得去年整場活動似乎沒有像以往那麼熱絡。
到了今年re:Invent用戶大會,官方雖還是採實體和線上併行,但從今年現場參加人數來看,至少超過5萬人參加,人潮逐漸恢復到疫情前的水準。今年活動重頭戲,就是首日主題演講,AWS執行長Adam Selipsky這次登臺,相較去年首次登場,大多時候都在回顧AWS在各項領域發展,如今執掌一年多,他今年對這家公有雲公司未來發展策略,明顯有了更清晰的藍圖。
在他的帶領下,AWS將以資料為主軸,透過整合、治理、安全和透明化,建立更廣闊的數據探索領域,來達成數據創新,甚至更要朝向「全解決方案」產業應用來發展。
一開場,Adam Selipsky先細數他們如何協助大型企業用AWS雲克服自身挑戰,如BMW集團用公雲打造連網汽車服務顛覆駕駛體驗,也有美國遊戲開發商Riot Games靠雲端來應付每秒50萬起事件通報與處理,提高用戶體驗以獲得更高收益。還有全球最大證券交易所Nasdaq完成關鍵核心系統上雲,提高金融市場證券發行業務處理效率,更多系統年底前將上雲。
不僅大型企業有用,Adam Selipsky也引用數據強調,超過8成新創獨角獸都是AWS客戶。
Adam Selipsky不只一開始就大談企業上雲經驗,他對於企業用戶的重視,也反應在今年AWS產品發布上跟往年明顯不同。長達2小時的主題演說,Adam Selipsky用合適工具(Right Tools)、整合(Integration)、治理(governance)以及洞察(Insight)4大主軸貫穿整場演講。他表示,面對複雜的資料規模挑戰,企業需要一套完整工具,可以處理各種類型資料,並將這些資料整合,然後提供治理和安全性,還要能夠以視覺化呈現,方便掌握和快速傳遞,來獲得對於公司業務有價值的洞察。
他所提出的這個企業數據戰略,可以說就是AWS新的產品策略,這次眾多雲端產品發布和服務更新,都是圍繞這個新策略發展,推出各種資料整合、治理、安全和透明化的服務方案。

執掌1年多,AWS執行長Adam Selipsky對這家公有雲公司未來發展策略,明顯有了更清晰的藍圖,將透過整合、治理、安全和透明化,來達成數據創新,更要朝向「全解決方案」產業應用來發展。圖片來源/AWS
無伺服器新布局:完善Serverless產品線,通吃旗下所有分析服務
在工具上,AWS已提供完整資料庫、分析、ML/AI工具,協助企業做資料處理和運用。尤其在分析服務上,AWS今年對於無伺服器(Serverless) 布局更加完整了。
去年AWS在年度大會上宣布AWS資料倉儲服務Redshift能支援無伺服器服務後,緊接下來,今年其他分析產品也陸續加入支援行列,包括大數據處理平臺EMR、即時分析工具MSK,若加上原本就能用於無伺服器型態的互動式查詢服務Athena、資料串流服務Kinesis、資料整合服務AWS Glue以及BI服務QuickSight,就只差搜尋和分析引擎服務OpenSearch還沒Serverless化。如今,AWS也把這個缺口填平,在會中宣布OpenSearch也能提供這個服務方案。
Adam Selipsky強調:「沒有人像我們可以做到所有分析服務都能提供Serverless。」
為何Serverless對於AWS如此重要?Adam Selipsky在會中並沒有明講,但他在去年大會上曾提到說,在他來看,雲端運算還在初期發展階段,要先把下水道工程布局布好,所以AWS是以雲還在起步的概念來布局,而Serverless就是一個重要戰略,對於Serverless持續加快布局,就是要把包括分析在內的服務都Serveless化,這一步還在持續發展,但AWS先從資料分析服務著手,並用資料整合來加以擴大。
AWS今年在資料庫和分析服務方面也有推出不少新功能。雲端互動式查詢服務Athena整合Spark,就是其中一個重要更新,使企業可以在Athena控制臺中使用Jupyter Notebook或Athena API來構建Spark應用程式,速度比起傳統啟用做法快75倍,而雲端資料整合服務AWS Glue,加入自動化監測和管理功能,來提高整合的資料品質。
AWS對資料服務布局還不只如此,還加強服務本身擴充性和可靠度,像是因應叢集服務需求,DocumentDB更新後現在可以建立跨多節點的DocumentDB叢集,以獲得每秒數百萬次讀寫吞吐量與PB級儲存規模。Redshit資料倉儲新增Multi-AZ預覽版功能,可以提供高可用配置設定,能跨多個可用區進行配置,讓資料倉儲也能和其他資料庫服務一樣具有高可用。
資料新布局:以實現Zero-ETL願景的資料整合為目標
AWS今年在資料整合也有新布局,以往要做到不同資料庫、資料倉儲的資料整合這件事,需要透過ETL(萃取、轉置、載入)處理流程,對於分析人員來說,太花時間,因此需要有新的資料整合方式,來加快資料運用。過去手動資料整合方式已經跟不上現在資料動態的特性與企業營運快速成長。這也成了AWS想要替企業客戶解決的痛點。
為了讓資料整合能更無縫接軌,AWS這些年一直想要打造一個Zero-ETL的新資料整合方式,以便在分析和ML服務時,就能直接取得這些資料做分析,而不需要搬動任何資料。「我們目標就是要實現Zero-ETL願景。」Adam Selipsky強調。
原先AWS在少數資料服務中就提供類似Zero-ETL的資料整合功能,例如使用AWS串流服務Kinesis時可以直接取得Redshift的資料,執行SageMaker機器學習服務時,也能很快拿到Redshift和Athena資料庫的資料做ML訓練,不需要另外建立資料處理流程(data pipeline)或撰寫程式。其他還有提供聯合查詢工具(federated querying tool ),可以跨資料倉儲、資料庫進行查詢和分析數據。
在今年資料整合更新中,AWS朝向實現Zero-ETL邁出更大一步,徹底無縫整合兩大數據雲端服務Aurora與Redshift的資料。透過 Aurora zero ETL Integration with Redshift這個新功能,每次只要有新資料寫入Aurora資料庫中,資料就會直接同步到Redshift資料倉儲,不需要重新建立和執行繁鎖ETL流程。這種Zero-ETL資料整合方式,也讓企業在Redshift實例中更多了一種資料分析來源,能從Aurora資料庫叢集的數據分析,來獲得跨多應用的整體洞察。
AWS對於資料倉儲的布局,也跨到整合串流大數據分析領域的主流平臺Spark,企業以後在Redshift上構建和執行Spark應用將變得很容易,不需要使用第三方Apache Spark連接器,就能馬上取得Redshift中的資料,提供給Amazon EMR做為大數據分析使用。這也為Redshift帶來新機會,能讓更多分析和ML服務都能用。
不光如此,Redshift在資料安全管控上也有加強措施,利用AWS Lake Formation資料湖治理功能,使Redshift數據共享達到顆粒度更高的權限控管,可以針對單一欄或行,來設定不同角色的存取權限,進而提高資料安全性。這也是AWS端到端資料治理策略一環。
在AI產品發展上,AWS延續去年端到端的資料戰略,AWS從去年就已經建構更加完整的機器學習和AI服務,從底層機器學習框架及基礎架構,到機器學習訓練環境全託管服務SageMaker,以及上層AI服務。目前上萬家企業用SageMaker建立ML模型,來執行每月上兆次的ML預測。
儘管,今年SageMaker沒有重大更新,但AWS仍推出不少局部功能更新,持續補強SageMaker服務完整性,像是新增ML Governance治理功能,可以讓開發者在端到端ML開發過程中,就能開始使用治理和審計,來滿足企業需求克服ML治理的挑戰。
對於使用SageMaker建立機器學習模型,現在也能支援地理空間類型資料作為ML訓練資料,來幫助開發團隊建立、訓練和部署這類型的ML模型,還可以將模型預測結果顯示在一個互動式3D地圖來查看。SageMaker以後可以擴展到更多應用領域,如農業、都市發展、商業新據點拓展。
在No-Code服務上,AWS針對No-Code的QA工具Quicksight Q推出新功能,不只能以自然語言進行提問,還能讓使用者可以用「為什麼」來發問,再根據機器學習模型得到預測和分析的結果,給出建議或答案。而透過採用這個方式,可以降低專業IT或資料科學家的負擔,讓更多非專業素人更容易運用AI。

AWS雲端機器學習服務SageMaker今年雖然沒有發布重大更新,大多是提供一些補強功能,但也持續加強SageMaker服務完整性,像是新增ML Governance治理功能,可以讓開發者在端到端ML開發過程中,就能夠開始使用治理和審計,來滿足企業需求克服ML治理的挑戰。攝影/余至浩
產業應用新布局:力推雲端供應鏈管理新服務
在產業應用上,AWS開始朝向全解決方案發展,新推出的AWS Supply Chain雲端供應鏈管理服務,就是瞄準全產業供應鏈管理需求。雖然目前是預覽版,但AWS強調,透過這套服務,企業未來可以自動組合和分析跨多個供應鏈系統的數據。該服務更是借助了Amazon電商物流供應鏈多年經驗與技術發展而來,但不限於電商,其他行業也能用。
更進一步來說,企業可以使用該服務內建的連接器,建立統一供應鏈數據湖,並運用母公司在供應鏈預先訓練完的ML模型,來自動匯整各套ERP和供應鏈管理系統中的所有數據,然後將分析 結果以視覺化呈現,不僅方便管理者隨時查看庫存變化,也能以此建立風險預警機制,一旦經過ML判斷為潛在高風險情況,就會提供警訊給負責人員,因此就能早一步採取避險行動。
但初期只有支援以SAP S/4HANA、SAP ECC、EDI、Amazon S3這4類為主的ERP、供應鏈相關系統和資料源。美國、歐洲將會先上線,其他地區陸續也將推出。
其他產業應用,還有支援大規模空間模擬的運算服務SimSpace Weaver。AWS表示,透過這個新運算服務,最多能支援超過1百萬個獨立動態實體,也就是可以在虛擬環境中模擬大規模人群、城市規模的環境以及複雜交通等。因為是提供企業或政府建立大型數位分身應用所需的運算基礎設施,所以將空間模擬擴展到多個EC2執行個體,管理底層運算、記憶體或網路執行大規模模擬,將有助於加速企業數位分身應用發展。
在資料安全性也有獲得不少強化,AWS推出名為Amazon Security Lake的安全數據湖服務,可以協助企業組織聚集、管理和分析日誌和事件數據,包含AWS和其他合作廠商的數據,讓資安威脅檢測、調查和事件應變速度能更加提升。新數據管理服務DataZone則可以讓資料專案團隊在統一資料協作環境中發布所需分析資料,來提供團隊成員查詢、存取或共享,並搭配治理與存取權限控管,來確保資料使用安全。GuardDuty EKS Protection防護服務中,也提供部署容器runtime威脅偵測。
雲端基礎設施也迎來不少更新,AWS目前超過600種運算實例類型,涵蓋一般用途、運算優化、記憶體優化、儲存優化、爆漲型效能及加速硬體等,AWS這次發布採用新一代Nitro系統和Graviton處理器的執行個體服務。
Nitro是AWS打造的EC2執行個體基礎平臺,歷經4代改版後,新一代Nitro大幅提高網路傳輸能力,每秒封包傳輸速度較前一代提高60%,反應速度加快30%,每瓦效能也有獲得40%改善。AWS還更新Graviton產品,儘管未是如外界預期Graviton4,而是改推出一款經改良的Graviton3E處理器晶片,但是該款處理器的向量指令性能表現,較前一代Graviton3能再提高30%,可適用於HPC應用場景。
AWS運用Graviton3E和Nitro推出多個執行個體服務,包含能支援200Gbps超大網路頻寬的C7gn,還有推出高效能運算專用的Hpc7G等。AWS這次也更新x86架構EC2實例,推出名為R7iz的新類型,能夠支援第4代Intel Xeon Scalable處理器,使每個vCPU效能比z1d再提升20%。C7gn、R7iz先推預覽版,Hpc7G最快明年才推出。
整體來看,AWS今年產品策略以擴大和延續為主,許多產品發布都是對既有服務或產品的補強,看似平淡無奇,但是這些更新背後,卻是有著AWS更長遠的企業數據產品戰略的考量,正透過一步步紮實的步伐,一一把各種企業需求的關鍵拼圖補齊。
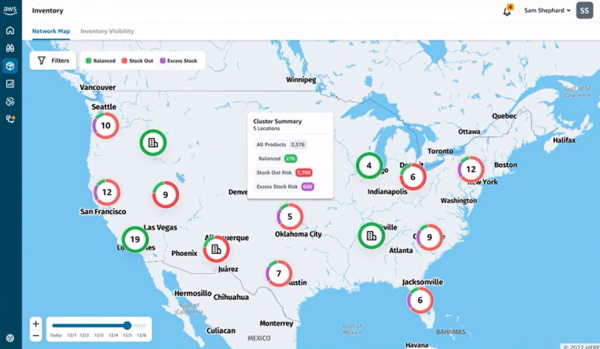
AWS推出Supply Chain雲端供應鏈管理新服務,借助母公司電商物流供應鏈多年經驗與技術,來匯整各套ERP和供應鏈管理系統中所有數據,然後將分析結果以視覺化呈現,方便管理者從互動地圖上隨時查看庫存變化,也能以此建立風險預警機制。圖片來源/AWS

在基礎設施也迎來不少更新,AWS目前超過6百種運算實例類型,涵蓋一般用途、運算優化、記憶體優化、儲存優化、爆漲型效能及加速硬體等。AWS這次發布採用新一代Nitro系統和Graviton處理器的執行個體服務。包含能支援200Gbps超大網路頻寬的C7gn(上圖),還有推出高效能運算專用的Hpc7G等。圖片來源/AWS

熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-09

2026-02-10


2026-02-10

2026-02-06