
開放科學合作組織BigCode釋出了一個用於程式開發,具有11億參數的多語言開源語言模型SantaCoder,能夠產生比更大型開源模型,更好的Python、Java與JavaScript程式碼生成和填充建議。BigCode現在於Huggingface網站提供SantaCoder演示,供任何人研究試用。
SantaCoder使用The Stack資料集訓練,由於研究人員想要訓練出一個相對小的模型,因此僅選擇目前流行的三種語言Python、Java與JavaScript。在訓練模型之前,研究人員先註解400個範例,並且建置完善的正規表示式規則,從程式碼中刪除了諸如電子郵件、金鑰和IP地址等敏感資訊。
研究人員藉由實驗不同的因素對模型造成的影響,發現有兩個做法能夠顯著提高模型效能,第一是積極過濾重複專案,另一項則是不篩選GitHub專案星數,研究人員表示,如果只選擇GitHub 5星專案的檔案,模型效能反而會明顯降低。
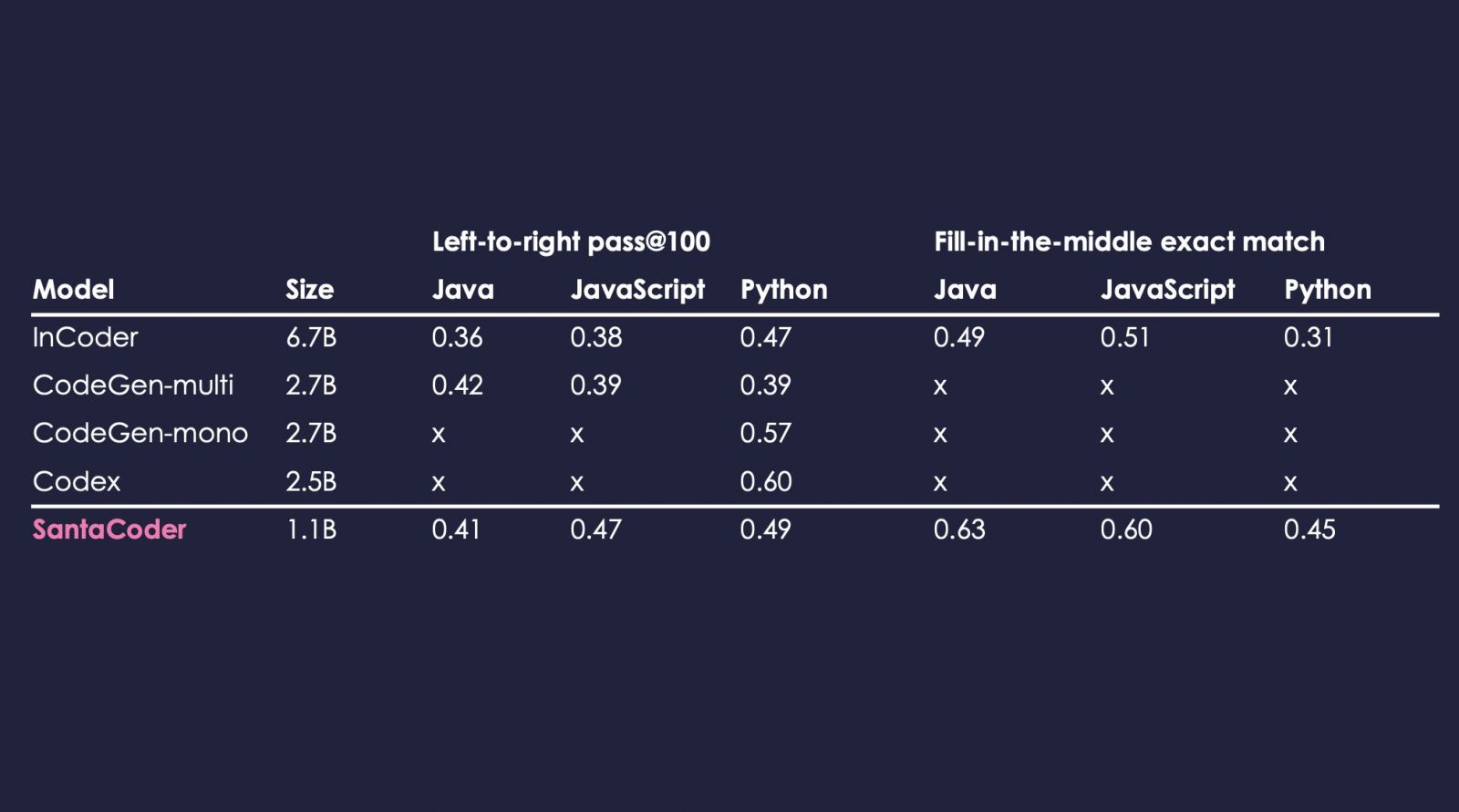
模型訓練完成後,研究人員使用MultiPL-E基準評估模型,MultiPL-E是一個支援18種程式語言的文字轉程式碼基準。SantaCoder從左至右生成和填充MultiPL-E中Python、Java與JavaScript部分程式碼,評估實驗證明,儘管SantaCoder只有1.1B,但效能優於規模較大擁有67億參數的InCoder,以及參數27億的模型CodeGen-multi。
SantaCoder使用開發和負責任人工智慧授權OpenRAIL,更重要的是,由於要讓開發者可以安心的使用SantaCoder,研究人員開發了一個程式碼歸屬查詢介面,讓用戶可以查詢SantaCoder生成程式碼的歸屬。
當開發者使用SantaCoder產生程式碼的時候,結果可能包含預訓練資料集程式碼的副本,研究人員提到,在這種情況下,程式碼的授權可能會要求開發者遵守部分要求,而透過使用程式碼歸屬查詢功能,用戶便可以找到程式碼的來源,遵守程式碼庫特定授權要求。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-12


2026-02-10

2026-02-06