OpenAI在發布對話語言模型ChatGPT之後,有鑒於其強大的語言能力可能在各領域遭到濫用,因此OpenAI釋出反制工具AI生成文字分類器,該工具能夠用於區分由人類編寫或是人工智慧生成的文字,用於輔助解決自動化誤導性活動和學術欺騙等問題。
OpenAI日前推出功能強大的對話語言模型ChatGPT,能以對話的方式解決使用者的各種問題,包括對程式碼進行除錯,與使用者討論天文、數學和文學等各個領域的議題,ChatGPT也足夠聰明被證實可通過大學商學院和法學院課程考試,但不少學生卻利用ChatGPT編寫報告或是論文,造成教學者的困擾。
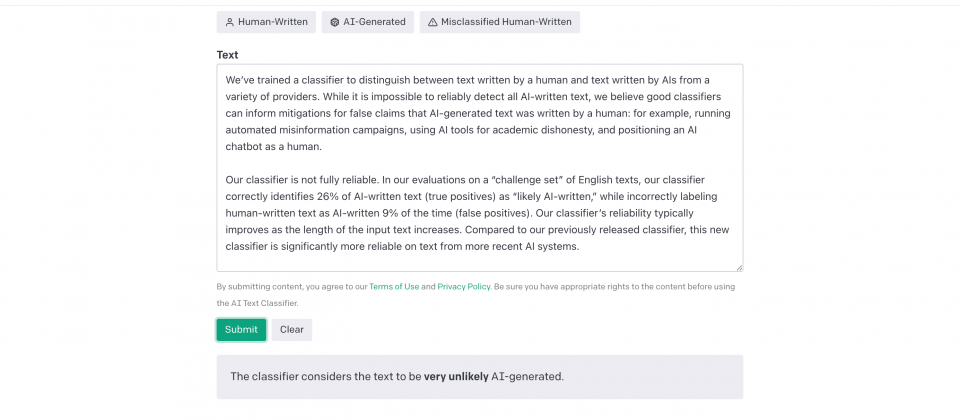
為了緩解這樣的亂象,OpenAI訓練能夠分類人類編寫的文字,以及來自各供應商人工智慧技術生成的文字,官方提到,雖然不可能完全可靠地檢測出所有人工智慧生成的文字,但能對宣稱由人編寫實則由人工智慧生成的文字,提供一定參考價值的判斷。
這個分類器是一種語言模型,OpenAI使用同一主題的人工文本和人工智慧文本資料集微調InstructGPT,只要使用者輸入最少1,000個字元,約為150到250英文單字,分類器就會判斷該文本是由人類編寫還是人工智慧產生。不過為求謹慎,OpenAI調整信度閾值以保持較低的誤判率,因此即便分類器很有信心,也只會將文字標記為可能由人工智慧生成。
OpenAI所釋出的分類器並不完全可靠,在英文文本的評估中,分類器僅能正確地將26%的人工智慧編寫的文本正確分類,同時將9%由人類編寫的文字,誤判為人工智慧生成,不過,分類器的可靠性,會因輸入的文本長度增加而提高,與過去的分類器相比,這個新的分類器在判斷人工智慧文本上還是可靠許多。
官方提醒,目前分類器還有許多限制,不能當作主要判斷的工具,僅可作為其他判斷方法的補充。該分類器在少於1,000個字元的短文本非常不可靠,甚至更長的文本都會被分類器錯誤標記,分類器甚至有時候會將人類編寫的文字,有自信地錯誤標記為人工智慧生成。
目前分類器僅能用於成人編寫的英文文本,可能會在兒童書寫的文字和非英文文本上出錯,同時,該分類器也無法用於辨識高度可預測的文字,像是無法用於預測前1,000個質數是由人類編寫還是人工智慧生成,因為正確答案都是相同的。
其實只要稍微編輯人工智慧生成的文本,就能夠簡單地迴避分類器,官方提到,雖然他們的分類器能夠更新並且再訓練,但目前不清楚這種方式,以長期來說是否存在優勢,而且也因為以神經網路為基礎的分類器,在對訓練集以外的資料表現很差,因此當使用者所輸入的文字跟訓練資料集的文字有很大的差異,則分類器便會以高度信心做出錯誤判斷。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10


2026-02-06

2026-02-10