
在臺灣新創資安公司當中,2017年底成立的奧義智慧以AI資安技術闖出名號, 5年後的現在,身為該公司創辦人之一的邱銘彰(Birdman),趁著2023臺灣資安大會舉行,呼籲大家積極關注AI進展,說明傳統作法日益難行的原因。
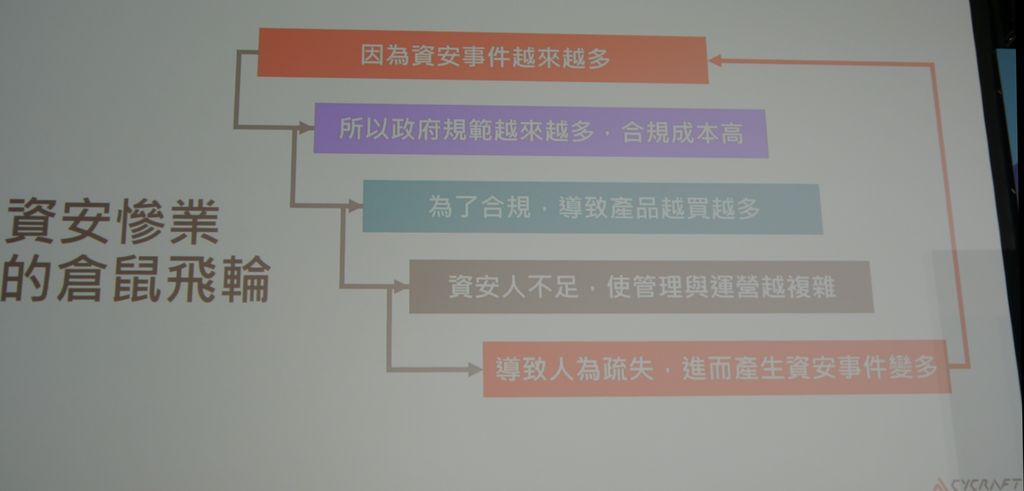
對於AI目前為何與如何用於資安領域,邱銘彰表示,資安產業長期陷入如同倉鼠不停在滾輪奔跑的困局,為了滿足日益嚴苛的政府法規遵循要求,必須在更短時間完成偵測、調查、處置,若繼續仰賴現行的作法,幾乎是不可能辦到的事情,若想控制在短時間內完成這些工作,恐怕會大幅犧牲精準度與作業品質,並無法有效提升整體防護,因此,他特別以魔法來形容AI資安,因為這能為防守方(藍隊)帶來極佳成效,並呼籲我們必須觸發AI的巨人之力。
打破資安「慘」業的惡性循環,擁抱自動化科技勢在必行
隨著網路攻擊與勒索軟體的猖獗,民眾的資安意識逐漸抬頭,然而,許多資安從業人員經常會以身處資安「慘」業來自嘲,因為面臨人力不足與管理營運不易的種種挑戰。
企業與組織能夠因應資安威脅的時間越來越短,則是另一個迫切的挑戰。邱銘彰提到,今年2月金管會召開的金融機構資安長聯繫會議,宣導金融業遇到資安事件須於30分鐘內通報的現行規定,然而,實務上,要達成這樣的要求,難度相當高。
因為在如此短暫的時間當中,我們對於有異常狀況電腦的所在位置都未必能完全掌握,例如,設備位於哪一個區域、哪一家分行,都不一定能找到,更何況還要能夠向主管機關通報狀況,邱銘彰認為,如果單靠人力去處理,難以在30分鐘內完成,要透過自動化的流程,才有辦法應對。
為了進一步了解掌握與通報資安事件的所需時間,邱銘彰將端點防護系統或網路安全設備發出資安事件警示之後的程序,區分為3個階段:平均偵測時間(MTTD)、平均調查時間(MTTI)、平均處置時間(MTTR),將這些時間全部加總起來、要控制在30分鐘以內,並不容易。

資安威脅層出不窮且日益複雜、刁鑽,想要在最短時間完成偵測、調查、應變,越來越困難,奧義智慧點出影響資安威脅總體處理時間長短的4大關卡,均相當仰賴資安人員的主觀判斷,若依據這樣人力密集的流程來進行,很難在半小時內完成,如此一來,將無法符合特定產業的主管機關要求,而可能會受到責罰。
以初期的MTTD為例,這裡所謂的偵測(Detection)不只是代表資安產品產生事件的時間,而是涵蓋安全維運中心(SOC)偵測到威脅而開設工單(ticket)的時間;中期的MTTI是指開單之後,需予以審查(Review)、分類(Triage),以及調查(Investigation);至於末期的處置(Response),因為可能會產生不同的業務衝擊影響,通常需要一定程度的人為介入處理,所以很難自動化,例如,若察覺公司的Exchange Server被駭客入侵,我們不能馬上將這臺受害的伺服器強制進行網路隔離,因為一旦這麼做,有可能導致全公司的使用者無法收取或寄送電子郵件,所以,需要透過其他作法來緩解。邱銘彰認為,相較之下,在MTTD、MTTI這兩個階段當中,較有機會去進行自動化處理。
AI獲重大突破,資安人員需與時俱進,善用特性以提升效率
作為防守方,邱銘彰也替藍隊(Blue Team)抱屈。他說,大家都以為藍隊是神奇寶貝,認為這裡面的成員不只是專家,而是世界頂尖的駭客、超人,期盼他們能在1分鐘之內完成所有的事情,但其實沒那麼厲害,因為實際上這是很辛苦的工作:每天的警報成千上萬,根本看不完,只能抽幾個出來進行調查,沒辦法快速處理,再加上還要進行合規、資安事件調查,以及應付長官、廠商等工作,他們要的不多,只希望能夠準時下班、準時休息,維持基本的生活品質。
面對這樣的攻守不對稱的困境,我們不能繼續抱持舊方法,邱銘彰認為:「我們的Blue Team需要魔法」,也是他這場演講名稱的由來。因為紅隊駭客這麼多,藍隊人力卻很有限,所以,自動化科技是大家一定要接受的,而且,這幾年的機器學習技術有很大的進展,若能善用這類新興的科技,有機會幫我們做到更自動化、更快速地反應。
為了讓所有在場聽眾快速了解這類AI技術的突飛猛進,他直接點出「魔法」的起點,正是2017年發表的重要論文《Attention is all you need》,裡面提出目前在AI領域相當知名的模型架構Transformer,而且,從語言處理的部分開始切入,後續在多個模態的資料,像是在聲音、影像的處理上,都有很大的進展。
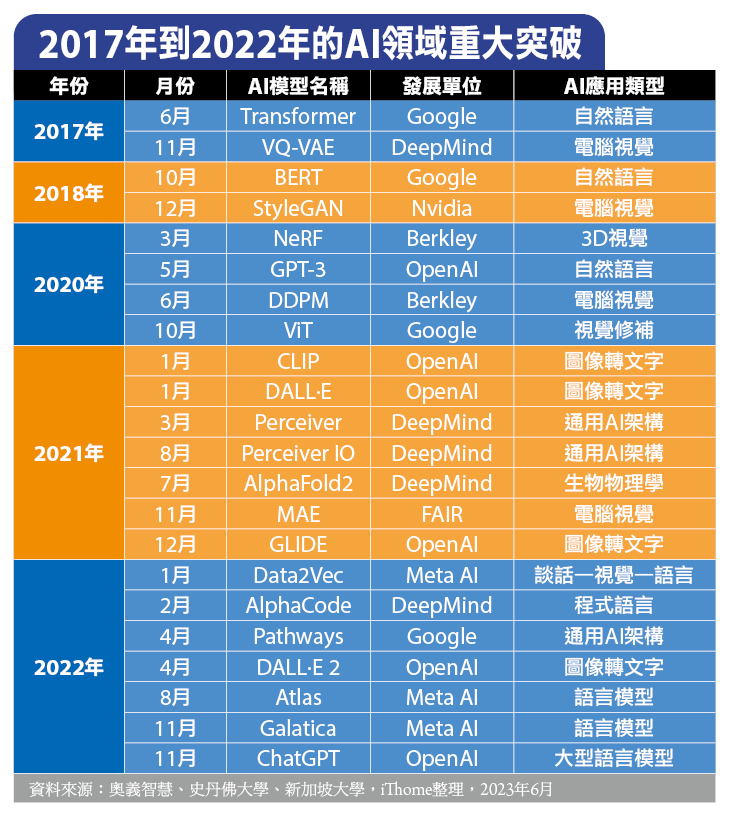
舉例來說,出現自我監督型學習(Self-Supervised Learning)的技術,像是2021年OpenAI推出的AI模型CLIP,能使圖片資料在無需標記處理(Labeling)的情況下,就能進行自主整理跟學習。而在2022年11月OpenAI推出AI模型ChatGPT之後,開始帶動新一波全球AI應用狂潮,到了2023年的2月到3月更是大爆發,因為大型網路公司Meta、百度,雲端服務業者微軟、Google,AI實驗室OpenAI、Anthropic、Midjourney,以及學術機構史丹佛大學,恰巧都在這短短一個月內,發表各種AI模型與服務整合。
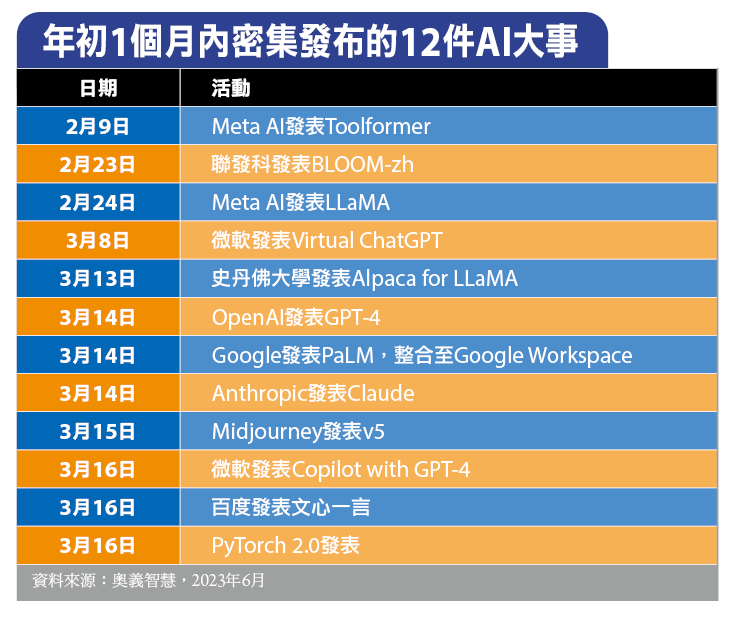
關於近期的AI技術發展,邱銘彰觀察到的第一個變化,就是設計思維的不同,他區分為4大階段:特徵工程(Feature Engineering)、架構工程(Architecture Engineering)、目標工程(Objective Engineering)、提示工程(Prompt Engineering)。
對資安人員來說,特徵工程是大家最熟悉的模式,因為是由專家來決定與判斷惡意程式的欄位、檔頭、API等特徵,再以此來進行偵測,換言之,仰賴人類專家決定特徵,主要運用統計的模式來看出特徵,然後依據特徵來設計演算法,而這是一種監督式學習;後來我們有了類神經網路(NN),能用深度學習的模式、更深層的網路來重現問題,此時雖然不需要準備特徵,但還是需要準備訓練資料、提供教材來讓機器學習,而這樣的作法屬於架構工程的範疇。
到了目標工程的階段,AI研究人員發現沒有標記的資料(unlabeled data)也能讓機器學習,可代表某些潛在的、抽象的知識,而此階段的處理模式就是預先進行訓練(Pre-train),以及精細調校(Fine Tune),同時,他們也發現類神經網路的最後幾層是能被換掉的,或者加幾層在後面,幫上游跟下游任務切割開來,所以近期才會有這些大型科技公司,做出預先完成訓練的語言模型,之後就能進行改裝,以因應各種領域的任務需求。邱銘彰說,由於上游任務跟下游任務是可以分開,導致機器學習工業化的可能發生了。
這樣的差異何在?他具體舉例說明。過去我們如果訓練出一個駕駛車輛的模型,這只能用來開車,若訓練出一個下圍棋的模型,也只能下圍棋,但現在我們可以做出通用刑的機器學習AI大腦,然後再加入上下游任務的指導,讓它精細調整而成為某些特定領域的專家,這也是為何目前大部分的人都是拿模型來改裝,當中可能包含精細調整與提示(Prompting),繼而引出最新的提示工程。
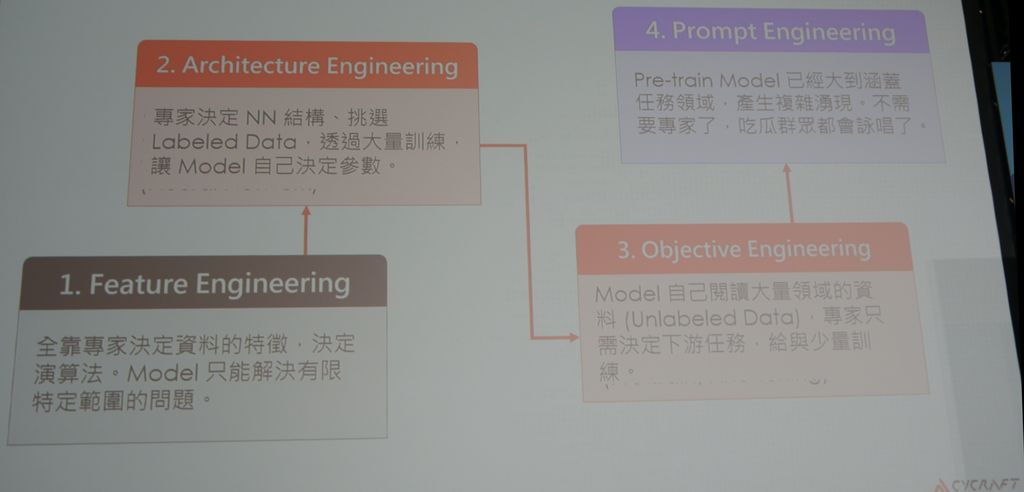
在提示工程的階段,我們只需要預先進行訓練即可,不需要再作過多的精細調整、不用去改模型的權重,直接用「咒語」來指導他——透過Prompting In-Context Learning的方式去引導模型,使其進入我們的領域進行問題的解決。邱銘彰說,目前的提示工程已到了匪夷所思的地步,我們不用準備特徵、你只要提示預先訓練模型、問它對的問題,它就能夠解決問題。
但要這麼做,需滿足一個前提,那就是這個模型必須大到能夠涵蓋絕大部分的任務空間(Task Space),而目前的方法是可以做到的,因為目前運用的大資料跟大模型而成的自我監督型學習技術,已經能夠涵蓋大部分的問題,所以對於專業的問題,它都能解答。
邱銘彰說,我們的模型已經能夠大到能夠涵蓋人類的所有知識了,我們可以想像這個語言模型就像人類文明的結晶體,現在只要解壓縮,將裡面的部分取出來、指個方向,它就可以解決那個領域的問題。所以,在這樣的概念之下,我們有個通用大腦,可裝在車子、機器人等各個領域之中,然後加上精細調整之後,它就有了新的能力,而這是工業化的進展。
面對這樣的技術突破,邱銘彰也向大家坦承自己的焦慮,他說:「我覺得Machine Learning的進展,已經快到超過人類能控制的範圍了」。隨著大模型加上大資料的應用,使得未經標記的資料能被AI學習,令人匪夷所思,因為「我們沒指導的事情,AI卻學會了」,例如,沒有人教它如何解開Base64編碼,後來AI竟能產生解開這類編碼的程式碼,然而,不能否認的是,目前的AI技術進展真的很成功,而這是值得的變化。
回顧過去AI發展,早期的特徵工程階段,是靠專家決定資料特徵,AI模型只能解決特定、小型的任務,進入架構工程階段、有了類神經網路,只需要決定訓練資料、提供經過標記的資料,讓AI模型來決定參數,從2017年至今,目標工程的作法崛起,AI能學習沒有經過標記的大量資料,我們只要在特定領域做些微調跟訓練,之後給它少量資料、少量標記,就能解答領域的問題,例如,在ChatGPT當中,有時我們只需提供幾個範例,AI就能依此完成指定工作,而到最新的提示工程階段,預先完成訓練的AI模型已經能涵蓋許多任務空間,導致新的能力湧現,因此會出現「我們先前沒有教它的事情,它卻學會了」的狀況,接下來,所有的人都能在AI的幫助之下,降低專業領域的進入門檻,而能變成各種領域的專家,當然資安也不例外,處於受影響的範圍。
關於機器學習能力近期大幅提升,邱銘彰也特別提到另一個關鍵,那就是AI研究人員發現「雙下降現象(Double Descent Phenomenon)」。簡而言之,過去大家總認為,AI模型增大,錯誤率應該會隨之逐漸增加,因此必須在偏差(Bias)與變異(Variance)之間進行權衡,而這也是傳統的統計、特徵工程運用的地方,但幾年前,研究人員發現AI模型若大到一定程度時,錯誤率會竟出現下降狀況,目前無法解釋原因,然而,基於這種反轉現象所呈現的效益,也促成現在AI大模型的盛行,我們會發現這些模型使用的參數量甚至比資料量還大。
當模型夠大、資料量增加時,AI開始出現一些複雜能力,像是自我監督型學習,能在資料未進行標記的狀況下,學到新的模式,而我們所要給予AI的部分,主要是預先訓練與精細調整。
因應這樣的變化,邱銘彰強調,我們要知道要解決的問題,以及所用AI模型的定位,才能確定應該增加資料量或模型的複雜度。

稍早的AI研究指出,模型逐漸變大時,錯誤率會先減少、再提升,此時大家陸續採用與發展的作法是基於統計模型而成的特徵工程(1),以及基於深度學習模型而成的架構工程(2)。之後有人發現如果將類神經網路的參數數量增加到更大程度時,錯誤率會減少,稱為雙下降(Double Descent Phenomenon),也促成機器學習的超大模型,以及超大模型與超大資料的盛行,基於預先訓練模型而成的目標工程開始大行其道(3),也帶動接下來的提示工程(4)。
展望AI發展,邱銘彰大膽提出他對下一階段的預言。
首先,給予 AI模型記憶與自我訓練的能力。
為何AI模型會被允許有記憶能力?因為現在AI模型並沒有這方面的能力,權重是靜態的,當模型完成訓練之後,就只能拿來套用,但如果AI對於外部互動歷程有記憶能力,例如我們與ChatGPT 聊天的過程能夠保留,這些內容就可以拿來改善模型本身的配置。
第二是給予AI可獲取外部資料的API介面,能操作其他軟體、體驗網路世界,獲得它自己的體驗。
AI開始使用外部API會是什麼樣子?以資安產品的開發為例,有啟動設備、掃描、鑑識調查、產生文件等各種API可用,如果這些介面能被AI學習、使用,它就擁有與外部溝通的能力,邱銘彰比喻:「這就像10萬年前人類開始用火」,而且,「AI開始使用工具」很快就會實現,因為Meta AI今年2月4日發表的Toolformer論文,就是探討予這股趨勢有關的技術發展。
第三是允許AI代理程式之間互相合作、分享經驗與資料。
未來會有負責開車的AI、做資安的AI、作教育的AI、執行政府相關工作的AI,不同的AI可以彼此合作、分享經驗與資料,如果我們讓AI進到人類世界,使其「經驗」我們的經驗時,它會獲得全新的能力。因為,當我們允許它進行交流之後,會產生新的現象。
第四是AI代理程式之間的組織成形,會湧現更高層次的複雜因果。
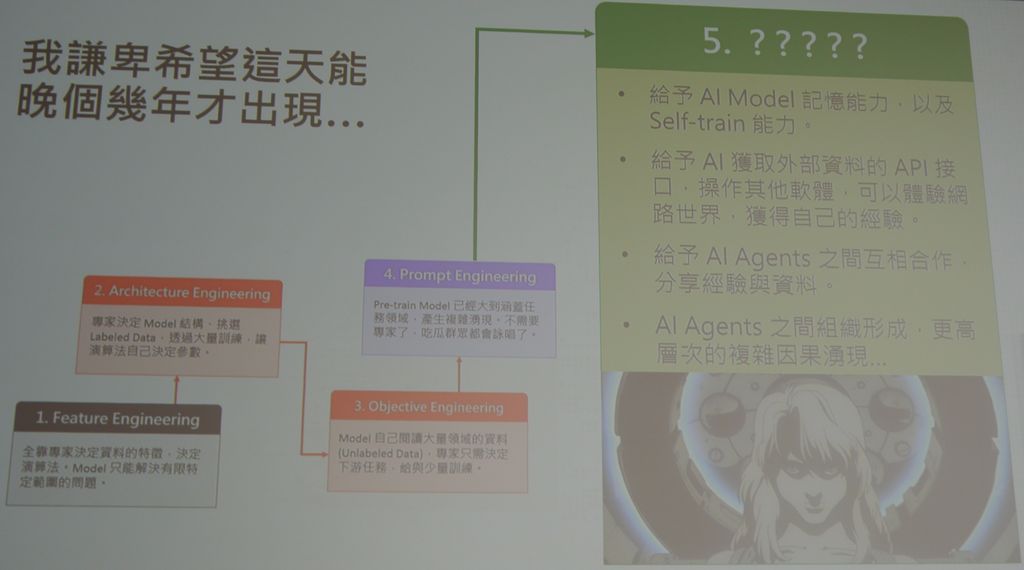
邱銘彰表示,目前AI代理程式之間面對的複雜系統相當有限,只有模型本身參數之間的複雜現象出現,但當AI模型之間的複雜系統出現時,會形成社群(community)、社會(society),甚至是另一個世界,而我們未來要跟這個世界合作,所以未來會有新的組織呈現,然後故事就會出現了。邱銘彰認為,在日本動漫《攻殼機動隊》裡面的「傀儡師」這個角色,所有未來的AI的模樣,都在這裡面可以看到。
跳脫特徵工程的局限,善用機器學習技術掏金
了解AI模型的演進之後,邱銘彰提醒我們要知道自己現在處於何種位置,他鼓勵我們多看新的方法、新的論文、新的研究,而在資安領域當中,也必須思考目前我們對於AI應用的方式,是否過於保守。
事實上,經常自詡為懂得高科技的我們,卻還是使用低科技的方式作資安,需要很多的資安專家進行高度人工作業,被視為人力密集型工作並不為過,而對照上述AI的發展歷程,我們可以清楚地意識到當前的資安,仍停留在特徵工程的階段。
舉例來說,關於惡意軟體的偵測,許多鑑識專家在撰寫專門用來定義這些威脅的YARA規則時,往往都是憑自己的直覺和經驗而成,但可能說不出為何要寫出這樣的模式和架構。邱銘彰說,當資安人員被問到這樣的問題,有人會回答:「不知道,我覺得怪怪的,這東西有妖氣,一定要寫成Pattern」,依此說法而言,顯然寫規則是一門「藝術」,藝術卻是很難複製的。
而在安全資訊與事件管理系統與安全維運中心的作業上,同樣有不少人是靠自己的感覺去撰寫警報通知的關聯規則——他們覺得某些行為之間應該有關係,所以寫出一個規則、用電腦名稱跟IP位址把它們關聯在一起,但這麼做可能並無任何科學依據。然而,這麼做的門檻很低,「隨便亂寫都可以」,之後究竟是否帶來實質的成效或誤判,也不容易驗證。
對於資安部門主管而言,絕大多數都是憑主見來判斷事情的等級,例如,有些人會認為駭客也會跟一般上班族一樣週休二日,因此週五下午之後不會有任何資安事件,因此,要求不要發資安警報通知。
縱觀上述三種職務的資安人員,大家都是靠直覺、靠感覺、靠主見在做資安,而原因正是資安界長期以來都仰賴專家來決定特徵。因此,邱銘彰直言:「如果資安產業跟專家Coupling一起,我們永遠不能Scalable」,他並非否定專家的重要性,而是認為術業有專攻,他強調,專家應該做專家的事情,就像醫生應該去做醫生的事情,而非去門口掃地,或是做護士的事情」。

若要擺脫特徵工程的作法,有不少資安人員對於改用機器學習來提升資安效率,仍然抱持遲疑的態度,對此並不熱中,邱銘彰提出三大理由。
首先是擔心因此增加額外的負擔。邱銘彰用「心很累」來概括大家對於現行資安產品的使用體驗,因為買一堆產品、每天要面對許多誤判,而機器學習的成效除了存在不確定性,也會產生誤判,而且大家也無法解釋誤判的原因,平時已經「被放羊的孩子嚇死了」需處理多到難以負荷的誤判,若再引進會產生誤判的技術,恐將導致資安人員崩潰。
第二是長期秉持「古法釀造」的職人精神,我們普遍認為在這領域當中,大師、專家的經驗知識非常重要,須學習三五年之久,才能寫出好的YARA規則,該運用哪些特徵、規則,則由人來決定,他們認為純手工最重要、對於AI這類高科技不感興趣。情境就如同上述習於特徵工程的大部分人員所言,當被問到特定IP位址被列入黑名單時,他們只能表示:「怪怪的」,然而,究竟有何異狀,卻看不出來、說不出口。
第三是知識落差。因為資安人員對於AI的相關發展與知識的了解有限,所以出現「看不懂、跟不上」的困境。舉例來說,包含資安廠商或AI專家在內的很多人,仍認為AI就跟傳統電腦科學帶給大家的觀念一樣,是「Garbage in, garbage out(垃圾進,垃圾出)」,若有這樣的認知,也意味著人們仍停留在特徵工程的階段,因為他們認為資料必須經過標記、機器才能學習,若輸入沒有標記的資料、機器就不能學習。
然而,現在已經不同了,因為在大數據分析、機器學習等技術的近期發展突破中,能做到「Garbage in , gold out」,就像我們能從岩石裡面開採、榨取、提煉石油,因此可將這些資料應用視為新的「淘金術」,而非盲目固守傳統觀念。

面對AI的不斷進步,它已成為勢不可擋的科技,邱銘彰預言AI會是人類不可或缺的夥伴。他說:「未來你的團隊裡,一定有個不是人類的同事,就跟科幻影集《銀河飛龍(Star Trek: The Next Generation)》的百科上校一樣」。他認為未來會有個同事,專門幫你分析資料,我們要擁抱改變、讓流程更快,讓資安的產能更高。

熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09

2026-02-06


2026-02-09

2026-02-09