,並在近期成為主流。(攝影/王若樸)")
Google DeepMind傑出研究科學家Marc Najork日前來臺參加第46屆SIGIR頂級AI學術會議時,分享了自己對生成式IR趨勢的第一手觀察。他表示,封閉型生成式IR是早期許多專家鑽研的領域,但同時,生成式IR還有一種實踐方式,也就是讓LLM結合檢索引擎等外部工具來回答問題。這就是開放型生成式問答系統(如上圖所示),並在近期成為主流。(攝影/王若樸)
從小到大,我們總遇過這樣一種人,不論你問什麼,他都能不假思索給你一個完美答案,就像是行走的百科全書。他不必翻書、不必上網查資料,仿佛所有知識都刻在腦中。
在電腦科學界,也有一群專家想打造這種「大腦」,也就是訓練一套大型語言模型(LLM),來學習大量知識、形成一個知識庫,並用這個知識庫來回答各種問題,不借助任何外部工具。這種模式就是生成式資訊檢索(後簡稱為生成式IR)的一種作法,也稱為「封閉型生成式問答系統,」Google DeepMind傑出科學研究員Marc Najork說道。
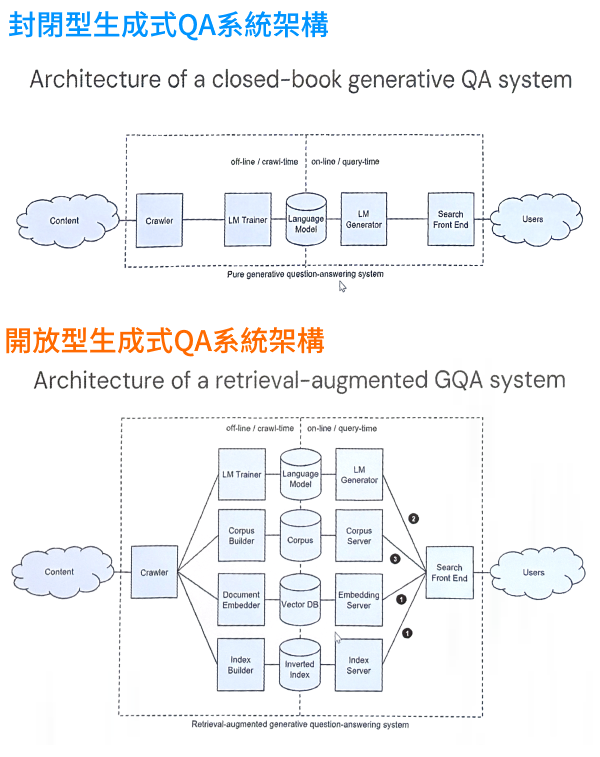
Google DeepMind傑出研究科學家Marc Najork指出,生成式IR主要有2種實踐模式,一是只以大型語言模型作為單一知識來源,稱為封閉型生成式QA系統(圖上)。這種模式的架構單純,容易搭配其他模組,來共同優化資訊檢索和問答。另一種實踐模式是大型語言模型結合外部工具,例如外部搜尋引擎,來回答問題。這種形式稱為開放型生成式QA系統(圖下),這種開放型模式是近期的發展主流,例如將生成式AI結合搜尋引擎來提供更人性化的搜尋結果。(攝影/王若樸)
生成式IR實踐模式1:封閉型生成式QA系統
Marc Najork專攻IR數十年,從個人化社群搜尋、推薦、排名,再到近年興起的生成式AI,都是他鑽研的領域。他日前來臺參加第46屆SIGIR頂級AI學術會議時,分享了自己對生成式IR趨勢的第一手觀察。有別於傳統IR,只按相關性丟出10條藍色字體連結,生成式IR可顛覆搜尋體驗,比如根據問題,快速給出摘要小卡片,附上圖文資訊重點和參考連結。
而封閉型問答系統,就是生成式IR背後的方法之一。這種系統只以LLM為單一知識來源,因此結構單純,很容易搭配其他模組,來共同優化資訊檢索和問答。
不過,也因為只仰賴LLM為單一知識來源,還有許多棘手問題要解決。比如,「如何避免模型產生幻覺(編按:指LLM理直氣壯地給出錯誤答案)?要如何將模型產出的答案,配對到可驗證的資訊來源?要如何擴展這個模型,讓它即便是封閉型,依然能擁有最全面的資訊?」Marc Najork繼續說明:「以及,如何更新模型?」也就是,如何確保模型能累積知識。
為找出答案,Google研究院去年就展開研究,想嘗試打造封閉型生成式問答系統。他們選定一套Transformer模型,將語料庫的所有資訊編碼至模型參數,讓模型盡可能具備大量知識,來符合封閉型系統的單一知識庫條件。同時,研究團隊設計一種新方法,讓模型接收查詢(Query)句子時,能依此預測出相對應的文件ID,給出答案。這等於,他們希望單一個Transformer模型,就能完成傳統資訊檢索工作。
研究團隊將這種架構稱為可微分搜尋索引(DSI),開發完成後也進行評測,來衡量DSI的資訊檢索能力。他們選出主流的IR模型BM25、T5和ScaNN,來與不同配置的DSI比較,並發現,特定配置的DSI,資訊檢索的表現遠勝過主流架構。這證實了封閉型生成式IR的可行性。
換句話說,語言模型有機會作為單一知識來源,甚至有能力做到歸因(Attribute),也就是將回答對應到資訊來源,讓答案有憑有據。
封閉型系統挑戰:學習、遺忘和擴展
不過,「這不是成熟的解決方案,只是封閉型生成式IR的早期研究階段。」Marc Najork點出,這種架構還不少待克服的挑戰,比如,如何將新的資料添加到模型中,讓模型累積新知識。
於是,團隊又展開研究,採用連續學習(Continual learning)方法,來讓DSI學習新文件。但就在DSI學習的同時,竟發生了非常嚴重的災難性遺忘(Catastrophic forgetting)問題,忘記原本已習得的文件知識。
為找出根源,Marc Najork和同事深入研究,發現這種遺忘有2類,一是隱性遺忘,也就是模型在進行批次學習時,會忘記同一批次中已學習的文件知識。另一是顯性遺忘,也就是模型學習新一批文件時,會忘記舊一批的知識。
後來,團隊針對2種狀況採取不同策略,比如針對隱性遺忘,他們不打算消除這個問題,而是透過現成的優化技術,來最小化隱性遺忘的影響。對於顯性遺忘,他們也採用既有的順向遷移方法,來在新一批資料中,混雜舊知識,讓模型一併學習。他們測試發現,這些方法效果非常好,大幅改善模型遺忘。
接下來,就剩一個挑戰要解決:如何擴展模型知識量。Google照例進行了研究,雖有其他新發現,但「我們仍不知道如何將模型知識庫,從上億文件擴展到數十億或數千億。」Marc Najork坦言,將模型知識庫,大規模擴展到網路等級,仍是未解之題,「未來還有很多研究要做。」
很顯然,封閉型系統要落地,還有漫漫長路要走。
生成式IR實踐模式2:開放型生成式QA系統
封閉型生成式IR是早期許多專家鑽研的領域,但同時,生成式IR還有一種實踐方式,也就是讓LLM結合檢索引擎等外部工具,來回答問題。這就是開放型生成式問答系統,可搭配額外的工具,來執行資訊檢索和問答,而非只靠LLM作為單一知識來源。這種做法,在近期成為主流。舉例來說,Google在3年前發表的開放型問答系統REALM,不只有語言模型,還有一套維基百科語料庫檢索器,可根據輸入的問題,來檢索維基百科知識、產出回答。這麼做,給出的答案更有憑有據,而且在開放領域問答測試上,表現還不錯。
Meta AI打造的RAG系統,也是以檢索器來強化生成式模型。RAG和REALM很像,但不同的是,REALM是對整個文件進行索引(Index),RAG則提前將文件切分為好幾個段落,並對這些段落索引,再根據問題,來從資料庫找出最相關的訊息,最後交由生成式模型產出答案。可以說,他們改良了REALM的方法,是一種更細緻準確的檢索和回答模式。
而DeepMind一年半前開發的RETRO,更是這類系統的分水嶺。因為,有別於REALM和RAG,RETRO不但合併了學習模組和檢索模組,所使用的語料庫還高達上兆個Token,等於可用的知識更完善了。尤其,RETRO採取一種特別的訓練機制,讓模型在檢索資料時,更容易追溯到語料庫中的來源,還能在生成回答時,整合多種資料來源,產出更有依據的嚴謹答案。這對生成式IR的搜尋應用,非常有幫助。
開放型系統特色:工具增強
不過,Marc Najork指出,這種開放型系統還是有些問題,比如很難處理以前沒記住的知識,尤其是「數學推理。」面對這個痛點,Marc Najork的同事們想出一個辦法,若將計算機當作一個工具,整合至語言模型,是否就具備算數能力了?
為找出答案,他們訓練BERT模型,來學習抽取文件中的數值數量,並學習如何根據給定的問題,來找出計算機正確的運算方式。也就是說,在一個問題中提到2個量的差異,模型這時就會知道要用減法,也知道要從語料庫中抽取到適當的運算元,來產出答案。完成開發後,團隊用DROP資料集來評估模型數學推理能力,發現效果非常好,比SOTA進階模型高出50%的分數。
這證明了,語言模型可藉由添加工具,來改善數學不好的弱點。但,這種用添加工具來補強弱點的方法,是否也能泛化,適用於更廣泛的領域?
答案是肯定的。因為,Google一群專家研究發現,將Transformer這樣的語言模型與不可微分的工具相結合,並用類似自我對弈的方式不斷迭代,可讓模型學會如何正確使用工具,來解決問題。他們將這種架構稱為工具增強語言模型(TALM),且評測也證實,TALM在知識密集型的問答任務和數學推理任務上,表現都遠勝於沒有工具增強的語言模型。
挑戰與嘗試:WebGPT
即使能用工具來補強,開放型系統還有些挑戰要克服,比如如何確保答案忠於來源、如何更準確將答案歸因到資料來源等,種種保障答案品質的挑戰。
面對這些難題,早在2021年,就有專家嘗試提出解法。這就是OpenAI打造的WebGPT,它採用GPT-3預訓練語言模型,是一款打開瀏覽器就能用的長篇問答系統。由於模型搭配檢索器來強化回答的生成,因此使用Bing API,來讓檢索器搜尋網路資訊。
為確保模型的回答品質,OpenAI還在模型微調階段,採用人類指導方法,來讓模型學習人類經驗。這就是後來廣為人知的「從人類回饋中學習」(RLHF)方法。不只如此,為保證回答有憑有據,WebGPT產出的答案,也設計成要附上參考來源。這個WebGPT,正是ChatGPT的前身。
這些特色綜合起來,是不是有點眼熟?沒錯,這就是現在搜尋引擎巨頭正在打造的生成式搜尋體驗,要透過開放型問答系統的驅動,在使用者輸入指令後,系統快速從海量資料中,撈出最相關資訊,並整理成一個圖文並茂的摘要小卡片,來給使用者參考。這個情境,也是IR發展70餘年來,可望實現的重要里程碑。

熱門新聞

2026-02-09

2026-02-10

2026-02-06

2026-02-09

2026-02-10

2026-02-10

2026-02-10

2026-02-09