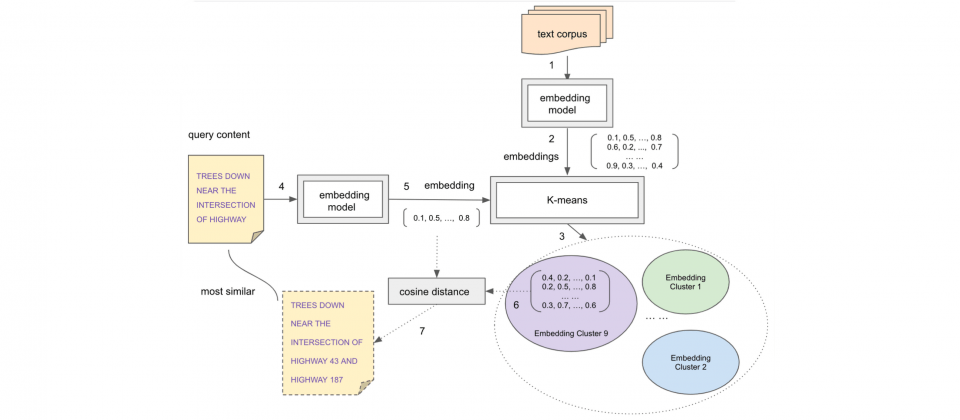
Google雲端資料倉儲服務BigQuery加入文字嵌入(Text Embedding)生成功能,開發者將可以透過熟悉的SQL指令擷取文字嵌入,並將其應用到下游應用程式中。目前BigQuery所支援的文字嵌入,可由textembedding-gecko、BERT、NNLM以及SWIVEL模型所生成。
這項新功能的使用流程,由註冊需要的模型成為遠端模型開始,接著用戶就可以使用生成文字嵌入函式來生成嵌入,而這些操作都僅使用BigQuery SQL就可以完成。文字嵌入是一個由文字轉化而來的向量,可用來尋找相似的項目,像是語義搜尋、分類、分群、異常偵測和或是對話式介面等應用。
BigQuery新支援的4種模型嵌入,其中textembedding-gecko是運用Google語言模型PaLM生成嵌入,其他三個模型BERT、NNLM以及SWIVEL,則都可以從TensorFlow Hub選用。BERT是Transformer架構的深度預訓練網路,可針對自然語言生成密集的向量表示,NNLM與SWIVEL則是以英文Google新聞語料庫訓練而成。
同時,官方也宣布開始支援array<numeric>特徵類型結構,使這些生成出來的嵌入,可被其他BigQuery支援的機器學習模型所使用,並根據向量空間的鄰近度與距離進行資料分析。
熱門新聞

2026-02-11

2026-02-12
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-09

2026-02-13


2026-02-10
Advertisement