
目前大型語言模型應用蓬勃發展,Nvidia針對語言模型釋出一個能夠強化H100 GPU推論能力的函式庫TensorRT-LLM,其涵蓋TensorRT深度學習編譯器和各種工具,供開發者用於定義、最佳化和執行語言模型,適用於生產環境加速模型推論。
Nvidia提到,由於大型語言模型的規模龐大,而且其運作的特殊性,很難以具有成本效益的方式執行。而Nvidia透過與Meta、Grammarly與Databricks等公司合作,開發能夠加速與最佳化大型語言推論的技術,並將這些技術整合到開源TensorRT-LLM函式庫中。
TensorRT-LLM由TensorRT深度學習編譯器組成,包括最佳化核心、預處理和後處理任務,以及多GPU與多節點通訊功能,讓開發者不需要深入了解C++或是CUDA,就能高效能執行語言模型。TensorRT-LLM透過開源模組化Python API提高易用性與可擴展性,讓定義、最佳化和執行大型語言模型更靈活,使用者可以簡單自定義。
由於大型語言模型用途廣泛,同一個模型可以處理聊天機器人的問答,也能夠輸出長程式碼區塊,Nvidia指出,如此高度動態的工作輸出的大小可能相差數個量級,因此很難有效地進行批次或平行處理這些工作。
TensorRT-LLM採用了一種稱為動態批次處理(In-Flight Batching)的最佳化調度技術,來管理這些動態負載,透過將模型文字生成過程切分為多次執行,如此不需要等待整批次完成,就能處理下一組請求,該方法可提高GPU使用效率,在H100 Tensor Core GPU測試中,吞吐量至少增加1倍,有助於降低總成本。
除此之外,TensorRT-LLM還能高效執行大型語言模型。龐大的語言模型像是擁有700億參數的Meta的Llama 2,需要協調多個GPU才能順暢運作,過去開發者必須手動分割模型,才能使模型以最佳效能執行,而TensorRT-LLM利用張量平行性,不需要開發者干預,就可讓模型在多個GPU上高效運作。TensorRT-LLM也包含了許多經最佳化的語言模型,包括Meta Llama 2、OpenAI GPT-2與GPT-3、Falcon、Mosaic MPT以及BLOOM等。
TensorRT-LLM結合H100 GPU,讓用戶可以簡單地將模型轉為FP8格式,官方解釋,這是一種稱為Hopper Transformer Engine的技術,使用時不需要變更模型程式碼。模型推論轉用FP8格式,能夠大幅減少記憶體使用,比INT8或INT4有更高的準確性,但效能更快實作也更簡單。
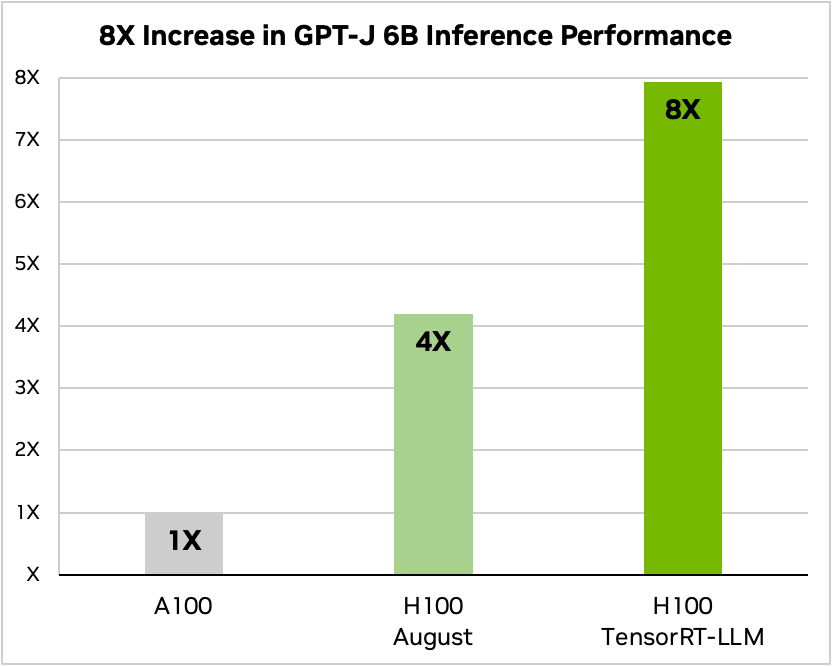
TensorRT-LLM帶來明顯的效能改進,雖然H100 GPU原本吞吐量就是A100的4倍,但是在搭配TensorRT-LLM之後,總吞吐量可以提高到8倍(下圖)。在執行Llama 2模型上,H100 GPU的推論效能原本是A100的2.6倍,但在整合使用TensorRT-LLM之後,推論效率可上升到4.6倍。
圖片來源_Nvidia
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10


2026-02-06

2026-02-10