
Photo by Steve Johnson on Unsplash
微軟亞洲研究院、北京大學、西安交通大學研究人員提出名為從錯誤中學習(Learning from Mistake,LeMA)的AI訓練方法,模仿人類學習知識的過程,來改進AI推理能力。
現今大型語言模型在自然語言處理(NLP)任務,特別是解決需要複雜思維鏈(chain-of-thought,CoT)推理的數學難題任務,例如OpenAI GPT-4和Google PaLM-2在一些數學題目資料集如GSM8K及MATH都有不錯表現。但開源LLM如LLaMA-2及Baichuan-2等則有待加強。為了提升開源LLM的CoT推理能力,研究團隊提出LeMA方法。這種方法是模仿人類,像是學生解決數學習題的過程:他們使用的是回溯式學習,即從錯誤中學習,以改進其推理能力。
因此,研究人員的方法是生成一對包含錯誤與修正版資料的資料對(稱為修正資料),再以此資料來微調LLM。為取得修正資料,研究人員蒐集了5個不同LLM(包括LLaMA及GPT系列)的錯誤答案和推理途徑,再以GPT-4為「訂正者」提供修正。修正包含三類資訊,分別是辨識出原有推理的錯誤步驟、解釋推理為什麼錯,最後修正錯誤、以及說明如何修正原方法以獲得最後正確答案。之後由人類評估夠好的修正答案再用以微調LLM。
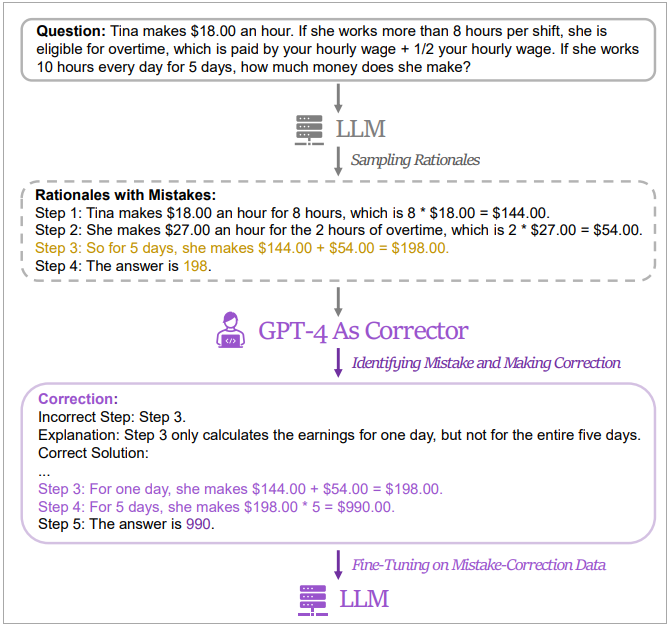
研究人員以2種問題資料集(GSM8K及MATH)實驗LeMa方法對5個開源LLM的效果,並比較只以CoT資料集來微調LLM的效果。結果顯示,以LLaMA-2-70B為例,它在兩種方法下,在GSM8K的準確率分別為83.5%及81.4%,在MATH則分別為25.0%及23.6%。此外,他們也實驗了WizardMath及MetaMath二種專門領域LLM的準確率,在GSM8K資料集測試中,獲致84.2%及85.4% pass@1 準確率,而MATH資料集則達27.1%及26.9%,這個成績超越非執行(non-execution)開源模型在同樣任務中的表現。
此外,他們發現,在同樣資料量的訓練集下,LeMA方法也比純CoT微調來得好。此外,整合CoT資料及修正資料,微調效果更優於單一資料來源的微調結果。
研究人員已將LeMA的程式碼、模型、資料公開在GitHub上。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09

2026-02-10

2026-02-10


2026-02-10