
酷澎
年收6千億元的電商巨頭酷澎,11月在臺灣啟用了第二座物流中心,再過半年又會很快的再啟用第三座。這家進軍臺灣來勢洶洶的海外電商,近年以驚人成長勢態在韓國電商市場獲得領導地位。他們更與全球電商龍頭亞馬遜有許多相似之處,使他們常被互相比較。
這些相似處不只是市場地位、同時販售自有品牌和第三方賣家商品的模式,也提供付費會員制度等,最具代表性的相似處是,酷澎也靠著高超物流管理能力,來快速履行訂單。酷澎全韓國99%訂單於一天內送達,甚至在都會區,半夜下的訂單,清晨上班時間前便會送達,這正是酷澎最知名的競爭力。
要做到超高速物流,背後技術關鍵就是數據分析和應用能力。酷澎企業文化十分重視數據驅動決策,數據科學家和數據工程師遍布於企業內不同部門,舉凡設計、行銷、產品、採購、業務、物流部門,都有能力和意願利用進階數據分析技術來支持決策。
酷澎對數據執著到什麼程度?打開酷澎App,圖示形狀和大小、每一步介面操作流程、每一個推薦商品和購物功能、每一則廣告,全部都需要進行A/B測試,驗證哪一項設計更利於消費者轉換,才能上線,他們稱自己是無情的優化主義者(Ruthless Prioritization),不靠經驗或喜好,凡事講究數據決策來決定優先順序。
顧客一送出訂單,物流中心的揀貨AGV就開始根據訂單,計算出行動路徑,穿梭於貨架間,就算訂單上有上百項商品,都能在2分鐘能蒐齊,交給包貨人員。貨架上的每一個商品,都利用機器學習模型的訂單預測結果來決定擺放位置,才能實現超高效率的撿貨能力。

圖片來源_酷澎
不只物流士送貨路經最佳化,物流管理者送貨區域的範圍和形狀,也能天天依據訂單彈性調整劃分,甚至可以細分到幾棟建築物一區。分貨機器人從流水線上掃瞄出包裹送貨地點後,會自動將包裹分配給當天每一區的物流士。物流士上路後,送貨和回收環保包材的行車路徑也依據地理和最新交通分析結果,規畫最佳送貨路徑。
2010~2016年:從關聯式資料庫到大數據技術
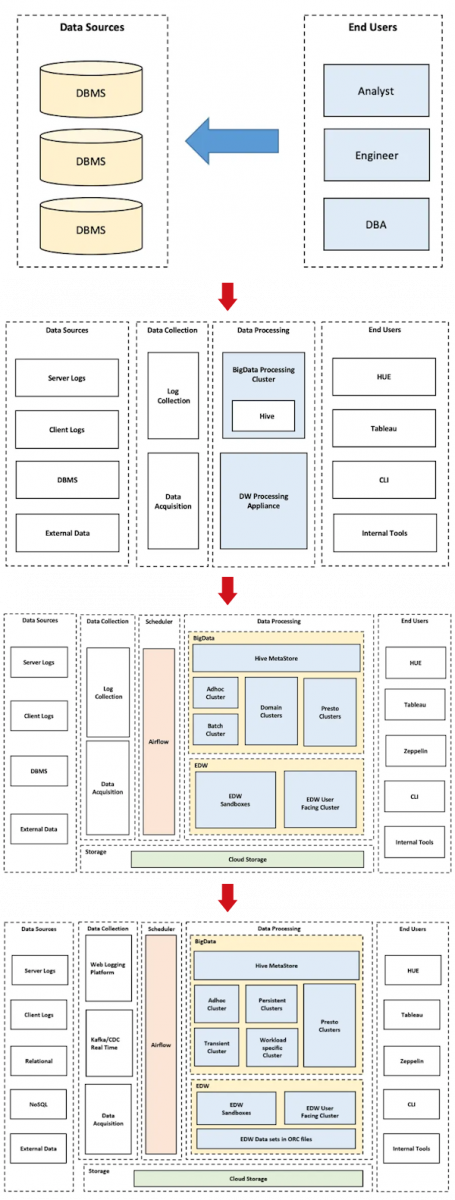
從行動商務起家的酷澎,自2010年新創階段以來就相當重視數據對於強化營運決策的價值,隨著規模擴大,也多次翻新數據基礎架構。
2010年到2013年間,酷澎用MySQL和Oracle等關聯式資料庫來進行數據儲存、處理和取用。他們內部數據架構相當簡單,分析師、工程師和DBA都能直接存取這些資料庫。
早在這個時期,他們便成立了數據科學與平臺團隊,大規模進行數據分析,來支援商業決策。數據使用需求大幅提升,更推進酷澎數據基礎建設演化至下一個階段。
2014年到2016年間,隨著數據使用需求提升,傳統關聯式資料庫開始不夠用,酷澎便開始投資Hadoop、大規模平行處理(MPP)資料庫、Hive等技術,以進行巨量數據處理。此時酷澎數據架構由數據源、數據蒐集、數據處理、和終端使用者組成,已經有未來數據平臺的雛形。
也在這段期間,酷澎設立了專職的日誌蒐集(Log collection)團隊。隨著酷澎大數據平臺處理的數據來源數量逐漸增加,這個團隊陸續打造了許多關鍵的數據擷取機制。
2016~2017年:基礎架構搬遷上雲,重構多處數據基礎建設
2016年,隨著業務規模提升,酷澎數據基礎建設無法隨著暴增的數據使用需求擴充。許多數據處理作業只能趁著上班時間前後的晨間或晚上進行,否則容易產生延遲或錯誤。
於是,酷澎花了1年時間,將大數據平臺從地端環境遷移上雲,重構和新增不少數據基礎建設。這包括使用多種容器化大數據工具來增加數據處理能力及可擴充性、打造行動App跟網站上互動資料的蒐集和追蹤框架,以及重新設計企業數據倉儲架構。
此時期酷澎數據倉儲設計成星狀架構的大規模平行處理系統,分為三大類數據倉儲叢集:數據擷取平臺、報告叢集,以及實驗沙盒叢集。
數據擷取平臺主要儲存原始數據;報告叢集會儲存清洗過後的數據;沙盒則是根據企業內部需求製作客製化數據表或數據集,來進行分析的環境。酷澎不同團隊會根據需求存取不同叢集,或要求工程團隊打造專屬沙盒的叢集來進行分析。
2017~2019年:發展Big Data as a Service模式
前一個階段的數據基礎架構下,酷澎遇到了2大挑戰。其一,每個團隊都想要有自己的Hadoop叢集,導致建置和管理成本過高。其二,數據擷取機制是用多個商用軟體疊床架屋出來的成果,隨著數據工作流程更多更雜,數據品質開始降低,進而影響後續決策品質。
為了因應這些挑戰,酷澎開始以Big Data as a Service的概念來改造數據基礎建設,做法包括標準化關鍵環節,以減少重工、維持數據處理品質、優化管理策略,以提升資源使用效率,支援更大量數據使用需求,以及新增各式自動化工具,在不需大量人工干涉的情況下維護數據品質。
第一個重要做法是重構數據擷取機制。他們捨棄過往疊床架屋的擷取機制,打造網路日誌蒐集(Web logging)平臺,用標準化方法來擷取數據。為了解決缺漏等數據品質問題,此平臺還設計了一個元數據服務,會驗證日誌數據格式正確且沒有遺漏,還提供網頁介面供內部查詢每一筆日誌的數據品質。元數據服務的檢查程序不會干擾日誌數據的擷取、儲存和轉換程序,但會在發現異常時通報相關使用者。
日誌蒐集平臺不僅使酷澎用來輔助決策的數據品質提升,後來,酷澎更持續發展此平臺,成為今日酷澎數據基礎建設兩大平臺之一,也就是數據擷取平臺。
第二個他們著手改善的環節是Hadoop叢集建立及管理。由於許多團隊都要求工程團隊建立專屬叢集,他們預先準備了不同用途的虛擬機器映像檔,減少叢集建立時間超過60%。管理政策上,他們一方面更加嚴格控管每個叢集的生命周期長度,以避免運算資源浪費,另一方面開始根據資源用量峰值分析結果來提前擴充雲端資源用量,來確保叢集執行穩定度。
這些做法使酷澎當下能用Hadoop支援更多數據使用需求。不過,隨著Hadoop使用需求再次暴增,他們後續又進行了更多優化,具體做法會以另一篇專文來介紹現代數據平臺。
第三個更新是企業數據倉儲主數據(Master data)的儲存模式。酷澎捨棄過往MPP資料庫,改用ORC文件格式儲存主數據,一方面增加儲存效率、降低規模化成本,另一方面使他們可以用Hive和Presto等可以高速處理大量數據的技術來存取企業數據倉儲。
他們還打造了一個企業數據倉儲管理系統,支援自動數據擷取、自動化產生Airflow DAG、數據監控、數據回填(Backfill)、下游數據依賴性管理、以及早期SLA出問題時的通報機制。
這些更新,使企業數據倉儲能支援更多數據處理技術,也有更多新增自動化數據處理與管理機制的選項,進而因應酷澎更多元、更大量的數據使用需求。
除了這些重大更新外,他們還新增了許多做法來完善大數據基礎建設,包括多種數據品質檢測框架、數據流程異常自動化通報機制、大數據平臺SLA監測機制、數據探勘工具等。
以進軍多國市場為前提的數據基礎建設設計
時至今日,酷澎數據基礎建設仍持續演化,這個PB級數據平臺一天執行超過5,000個任務,使用超過70個來源的數據,且從中衍生出了送貨管理系統、多種自動化供應鏈管理及訂單履行機制,以及支援同時進行上千個獨立A/B測試的實驗平臺等,使他們能持續用數據優化營運環節。這些系統都會於後續文章詳細介紹。
成熟的數據基礎建設及凡事數據驅動的文化,使酷澎快物流等許多業務面關鍵競爭力變得可能,也成為他們發展外送平臺等多角化經營業務的技術支柱,更有可能成為他們進軍多國市場的利器。
數據基礎建設中,有許多系統是以適用多國市場為前提來設計。例如,他們地圖系統從定位能力和數據管理政策上,就已經設計成容易支援全球物流規畫,而非只適用於韓國。用來執行一天破千個A/B測試的實驗平臺,也有許多為了支援全球市場A/B測試而設,包括分散式運算優化策略及可擴充式設計等。
固然,光靠這些做法,酷澎未必能百分之百將韓國的成功做法移植到國際市場,不過從技術面瞄準全球化架構的龐大設計,可以看出酷澎想要善用高超數據應用能力,來強化國際競爭力的企圖心。
酷澎數據基礎建設架構沿革
酷澎數據基礎架構從簡單的關聯式資料庫開始,逐步導入大數據相關技術,後經歷了上雲和多個系統重構。接著,他們開始打造許多標準化數據工作流程、管理策略和檢測框架,以期在支援大量數據使用需求同時,仍能維持品質數據、控管成本,並保有進一步擴充的彈性。圖片來源/酷澎

熱門新聞

2026-02-13

2026-02-13

2026-02-13

2026-02-13


2026-02-13


2026-02-13