
Stability AI新模型Stable Video Diffusion是一個可接收使用者文字指令,生成影片和圖像的擴散模型。目前官方釋出預覽版供研究使用,程式碼已經在GitHub上公開,而執行模型所需要的權重,官方也公布在Hugging Face上。
Stable Video Diffusion是第一個以Stable Diffusion模型作為基礎的影片生成模型,官方在其研究論文提到,近來研究人員在原本用於2D圖像生成的潛在擴散模型(Latent Diffusion Model,LDM),加入時間層,並且使用小型、高品質的影片資料集加以訓練,試圖將其改造成影片生成模型。
而Stability AI這個最新的研究,則進一步定義出訓練影片LDM的三個階段,分別是文字到圖像的預訓練、影片預訓練,最後則是高品質影片的微調。研究人員強調,經過良好整理的預訓練資料集,對於產生高品質影片非常重要,甚至還提出一套包括標題製作和過濾策略的系統性整理流程。
研究人員也展示了在高品質資料上微調基礎模型的影響,並訓練出能夠和閉源影片生成模型相匹敵的文字轉影片模型。Stable Video Diffusion還可用於圖像轉影片的生成任務,並且展現出強大的動作表示能力,且適用特定相機運動的LoRA模塊。
目前Stability AI釋出兩個Stable Video Diffusion版本,分別是能夠生成14影格以及25影格的模型,用戶可以自訂每秒影格數在3到30之間。雖然高影格數的影片看起來更順暢,但是在目前的模型限制下,如要產生每秒達30影格數的影片,則兩個模型產生的影片長度皆會少於1秒鐘。
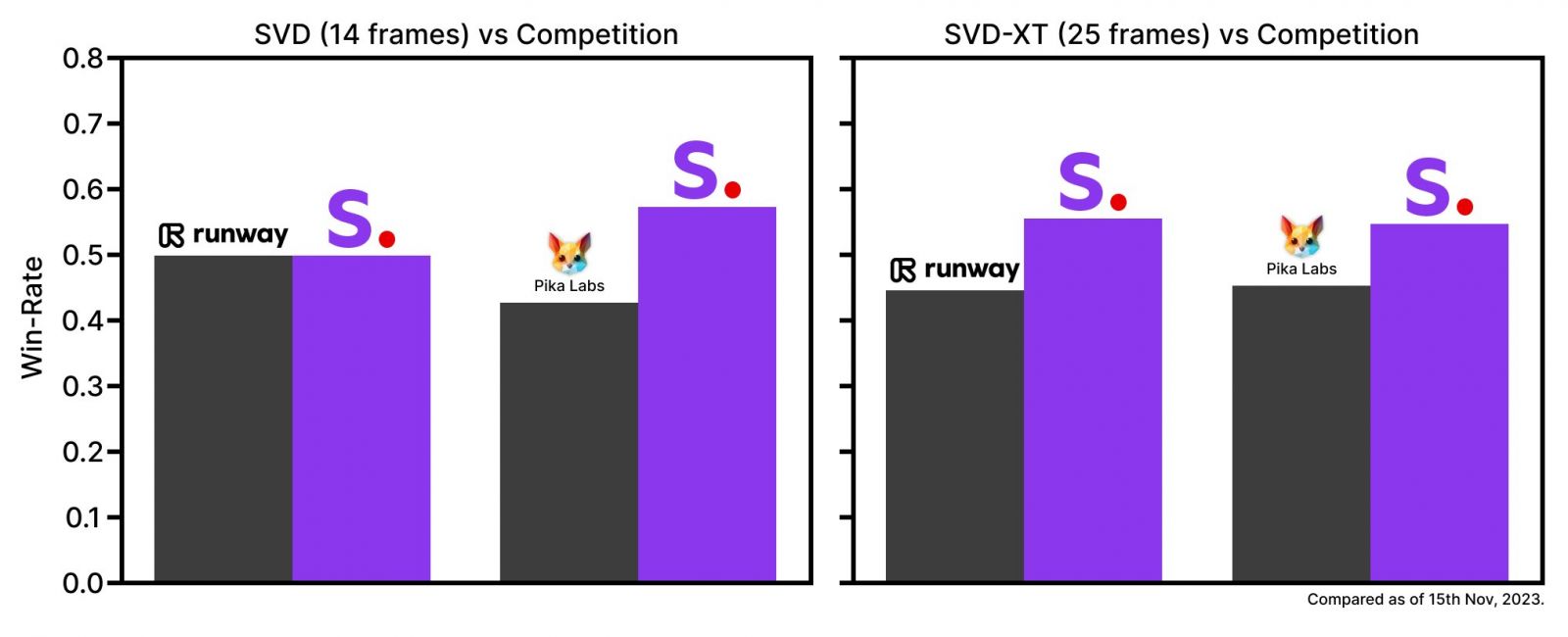
不過,官方將這些基礎模型與其他閉源產品相比較,在用戶的偏好研究中,Stable Video Diffusion的表現都較目前市面上的產品還要好。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-10

2026-02-09


2026-02-10

2026-02-13