蘋果
繼12月開始,蘋果陸續公布其AI開發及研發成果。蘋果上周再公布多模態大型語言模型(multimodal large language model,MLLM)Ferret及相關標竿測試工具與資料集。
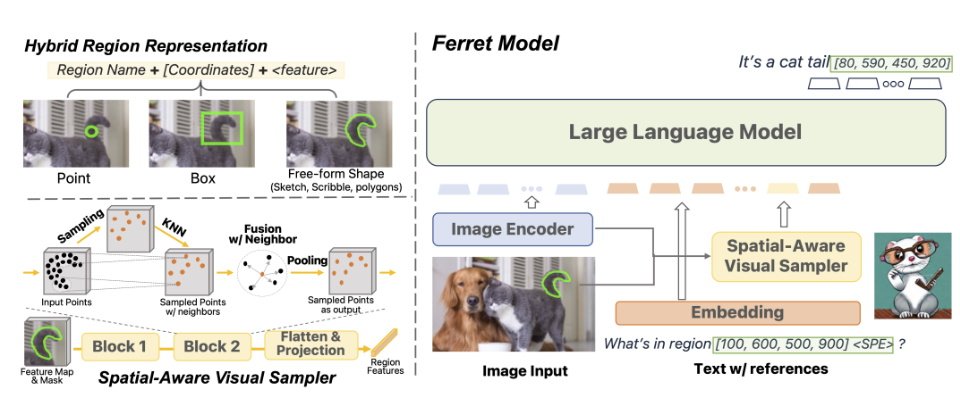
多模態意謂Ferret能接受文字、聲音、影像或數據的輸入。根據蘋果10月公布Ferret的研究論文說明,Ferret能理解任何形狀或任何圖片顆粒(granularity),且能準確定位(ground)開放字彙的描述。要將引用(refer)及定位能力整合到LLM中,Ferret採用新式的混合區域表徵(hybrid region representation)技術,可整合個別方位和連續性的特徵,以表示圖片中的某一區域。為提取出區域中的連續特徵,蘋果研究人員提出一種空間感知的視覺採樣器,它能處理不同形狀多種稀疏性。這使得Ferret可以接受多樣化區域輸入,像是點、bounding boxes、自由形式的形狀。為提升Ferret的能力,蘋果團隊使用了GRIT資料集(Ground-and-Refer Instruction-Tuning),後者為是一個廣大的refer-and-ground指令微調資料集,包含110萬個樣本,內有豐富的階層化空間知識,以及9.5萬個負樣本,以便提升模型的判斷力。

最後蘋果得到的模型Ferret-13B,和Kosmos-2、GPT4-ROI、LLaVA、Shikra等MLLM比較,在傳統引用及定位任務具有優異效能,此外,在區域為基礎、需要本地化的多模態對話、細節描述,以及複雜推理等任務,都優於其他MLLM。在視覺化比較任務,蘋果說它的模型展現優異的空間理解及常識推理能力。此外,蘋果宣稱其物件幻覺也較Shikra、InstructBLIP、MiniGPT4、LLaVA、MM-GPT及 mPLUG-Owl等知名MLLM少很多。
蘋果公布了Ferret7B、130B二模型的程式碼、GRIT資料集、標竿測試工具Ferret-Bench,上周也公布了Ferret 70B及130B檢核點(checkpoint)。
這是蘋果公布最新AI研發成果。12月初蘋果公布Apple Silicon平臺專用AI框架MLX、以及能在裝置端執行LLM的方法,後者能在邊緣裝置執行DRAM兩倍大的LLM,可節省執行LLM所需的運算資源,也更能確保隱私。
熱門新聞

2026-02-11

2026-02-09
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10