
Meta新釋出程式碼生成模型Code Llama 70B,是Code Llama系列中最大的模型,以程式碼生成基準測試HumanEval分數67.8%,成為目前效能表現最好的開源模型。新模型與之前的Code Llama模型皆使用相同的Llama 2授權。
Meta在去年8月的時候,運用自家可商用大型語言模型Llama 2為基礎,開發出程式碼編寫專用語言模型Code Llama。Code Llama相較於Llama 2,使用了更多程式碼資料集訓練,具有更強的程式碼編寫能力,能夠根據開發者自然語言提示,生成程式碼或是軟體開發相關的自然語言回應。
Code Llama支援多種開發者常用程式語言,包括Python、C++、Java、PHP、Typescript、C#和Bash,而且針對在人工智慧領域日益重要的Python,微調出Python開發專用Code Llama-Python模型。
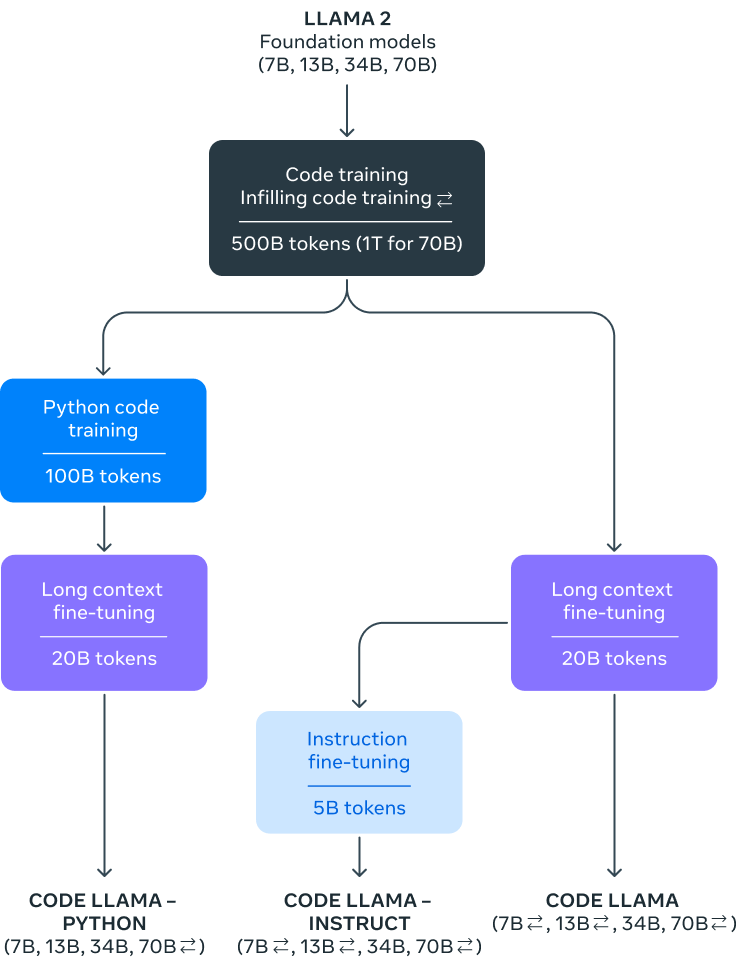
Code Llama現在總共有4種大小,除了先前所發布的有70億、130億和340億參數之外,新釋出的Code Llama 70B模型則有700億參數,使用1兆Token訓練而成,相較於之前較小的模型使用5,000億Token訓練,足足增加了1倍。而Code Llama 70B模型同樣有3種版本,分別是基礎程式碼模型CodeLlama-70B,以及為Python特製的CodeLlama-70B-Python,還有針對自然語言指令微調的Code Llama-70B-Instruct。
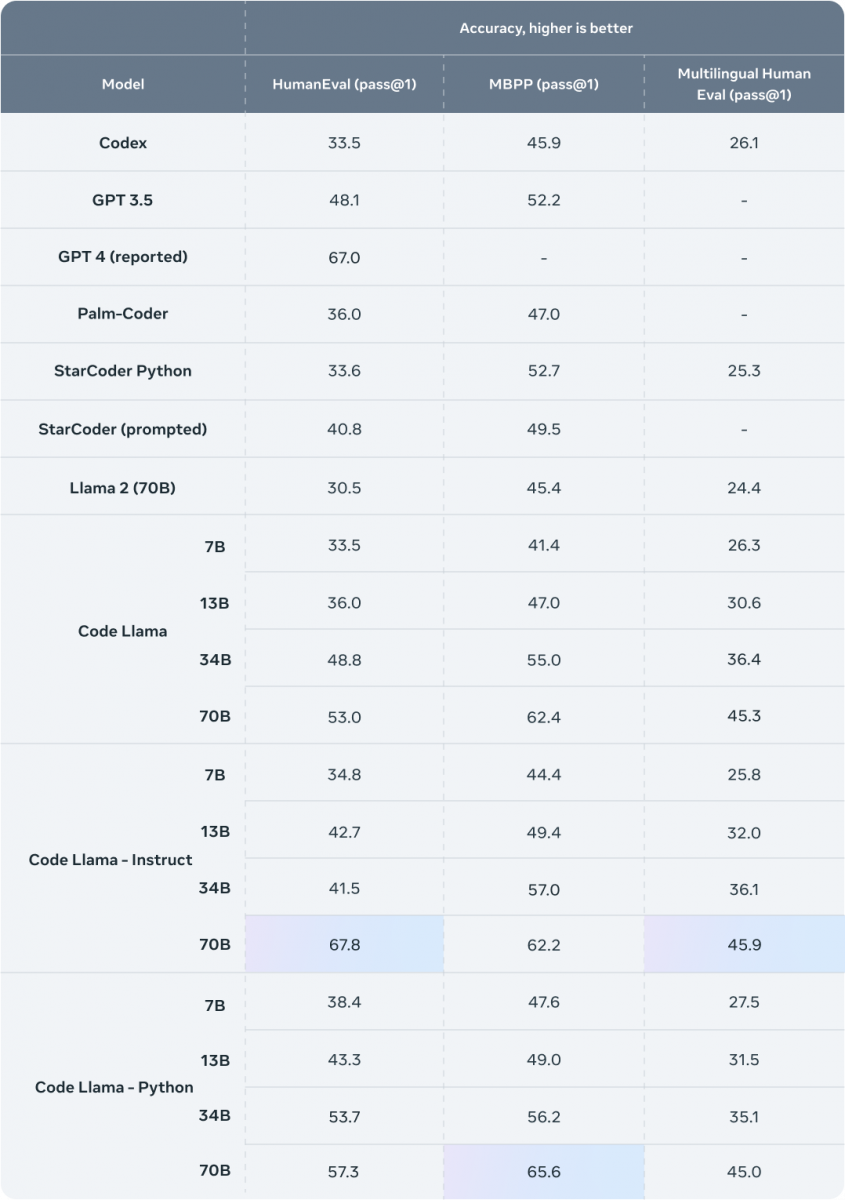
根據Meta所更新的HumanEval Pass@1指標分數,Code Llama-70B-Instruct分數為67.8%,不只遠超過之前Code Llama-34B-Instruct的41.5%,也是目前開源模型中的最佳表現,甚至超過當初GPT-4的67.0%。
HumanEval Pass@1是專門用於評估程式碼生成模型的效能,而Pass@1是指在模型不進行任何重試的情況下,第一次嘗試就成功解決問題的機率。在對程式碼生成模型進行測試時,研究人員會提供一系列程式開發問題給模型,針對每個問題,模型只有一次機會生成解決方案,而模型所生成的解決方案,會經過一連串單元測試確認其正確性。因此Pass@1是一個重要指標,代表模型沒有多次嘗試或是人工干預的情況下解決問題的能力。
針對Code Llama 70B模型的發布,Mark Zuckerberg也特地發文並提到,撰寫和編輯程式碼已經成為人工智慧模型重要的用途之一,而且編寫程式碼的能力,也對於人工智慧模型能更嚴謹且更有邏輯地處理其他領域資訊有著重要的影響。
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
")
2026-02-09
")
2026-02-09

2026-02-09