
大型語言模型服務公司Predibase推出了一個名為LoRA Land的服務,該服務的特點在於集合了25個經微調的大型語言模型,這些模型都是以開源的Mistral-7b模型作為基礎,Predibase針對不同任務對Mistral-7b進行最佳化,使其在不同領域的任務,能夠表現得比原始基礎模型甚至是GPT-4更好,而且更具成本效益。
官方認為,隨著Transformer預訓練模型的參數數量不斷增加,大型語言模型參數高達數十億個,這使得這些模型難以適用於下游任務,尤其是資源和預算有限的環境中。而Predibase採取的作法,是運用參數高效微調(PEFT)和量化低階適應(Quantized Low Rank Adaptation,QLoRA)技術,來減少微調參數數量和記憶體使用量,權衡模型效能與效率。
藉由將這些最佳實踐整合至平臺中,使每個微調模型的GPU成本降低至8美元以下,而且透過Predibase所開發的大型語言模型開源平臺LoRAX,讓用戶可以在單一GPU上執行和部署數百個經過最佳化的大型語言模型,提供無伺服器微調終端,這代表用戶不需要專用GPU資源來執行模型。
官方提到,這項作法的好處是可以大幅降低成本,因為用戶在不需要用到GPU時,便不需要支付費用。而且Predibase提供可擴展的基礎設施,可依據用戶的需求擴展微調模型數量,用戶需要用到GPU時,也不需要等待GPU冷啟動,可以更快地測試和迭代模型。
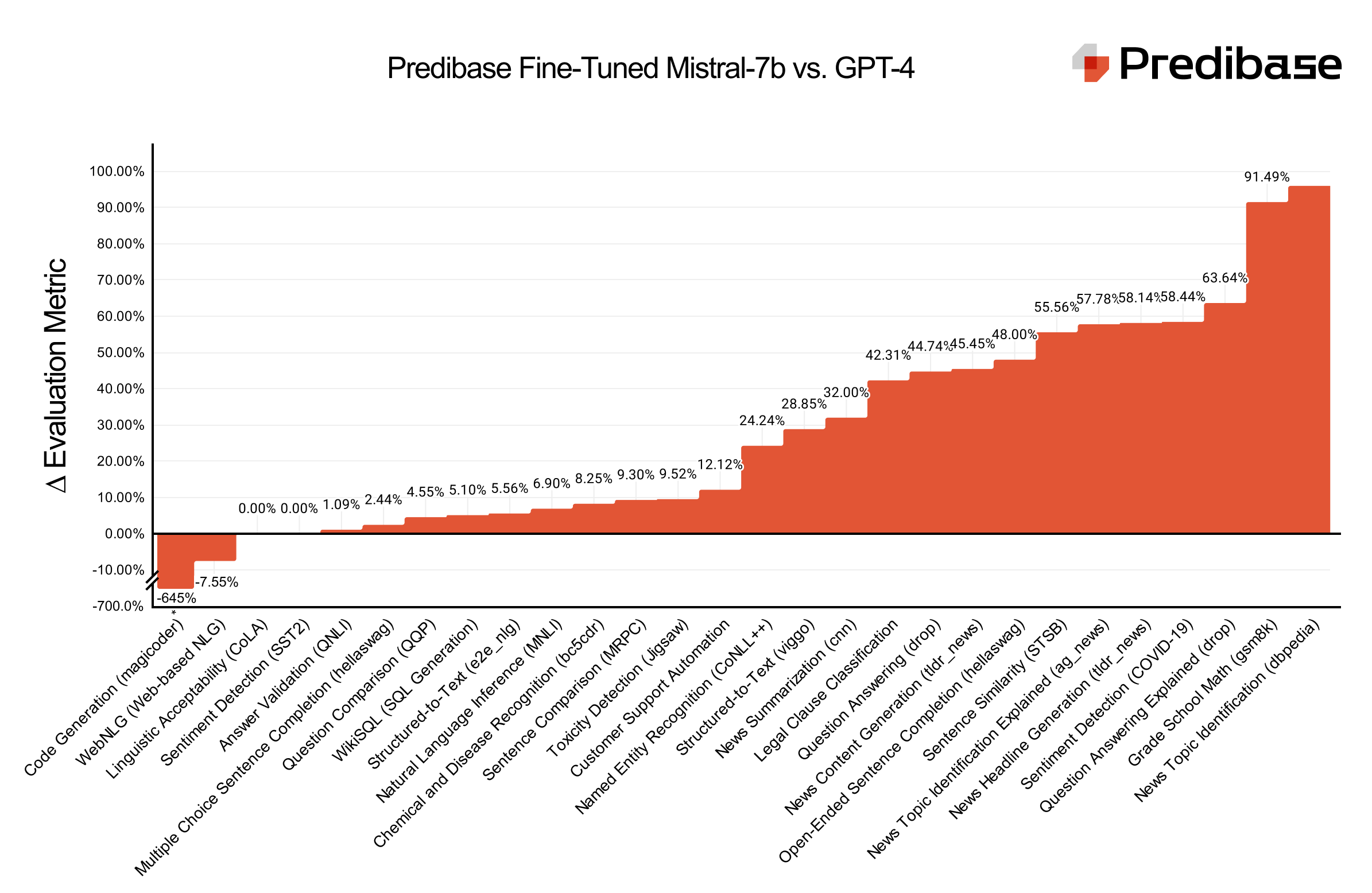
而根據官方所提供的評估指標(下圖),針對25個任務最佳化的模型,可以在大部分的任務中贏過GPT-4和基礎模型。根據任務不同,經微調的模型的效能可比基礎模型高70%,並且贏過GPT-4模型4%到15%,而且這25個可以完全以LoRAX在單一A100 GPU運作,唯有程式碼生成任務微調模型效能明顯低於GPT-4。官方表示,他們建立LoRA Land的目的是要說明,較小且針對特定任務微調的模型,能以更具經濟效益方式,超越商業替代方案。
熱門新聞

2026-02-11

2026-02-12
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-09

2026-02-13


2026-02-10