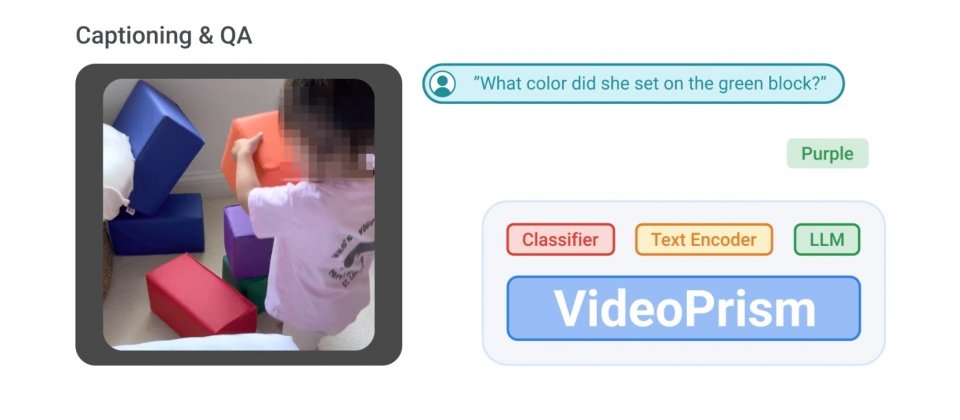
Google開發了一個針對廣泛影片理解任務設計的基礎視覺編碼器VideoPrism,研究人員藉由新的預訓練資料和建模策略,使其可以用於分類、定位(Localization)、檢索、字幕和問答等影片理解任務,並且在多個基準測試中表現優於專門為任務設計的模型。
影片相較於靜態影像擁有更豐富的視覺內容,包括實體間的運動、變化和動態關係等,研究人員提到,要分析這種複雜性,以及處理公開影片資料的巨大多樣性,需要超越傳統影像理解的模型。而過去相關的研究中,通常是針對任務量身訂做模型,而到了最近,影片基礎模型諸如VideoCLIP、InternVideo、VideoCoCa和UMT有了一些進展,但是要用單一模型處理影片資料的多樣性仍是一大挑戰。
Google提出的VideoPrism則是通用影片理解的單一模型,而使其能力更加強大的原因之一,歸功於大量的訓練影片資料。VideoPrism的預訓練資料集,是目前已知最大且最多樣的影片訓練語料庫,由多個公開和私人資料集所組合而成,涵蓋了YT-Temporal-180M、InternVid、VideoCC和WTS-70M等。這個預訓練資料集擁有3,600萬個帶有高品質字幕的精選影片,以及5.82億個存在雜訊文字的影片片段,像是自動生成轉錄字幕的影片等。
而VideoPrism的訓練採用了標準視覺Transformer(ViT)的分解設計,共分為兩階段,第一階段研究人員先用高品質的影片文字資料和帶有雜訊文字的影片資料,以對比學習(Contrastive Learning)技術教導模型將影片和文字描述配對,而這個階段建立了語義語言內容和視覺內容相配對的基礎。
對比學習是一種自監督學習方法,不仰賴傳統的標籤資料訓練模型,其核心思想在於使相似樣本的表示更接近,不相似樣本的表示更遠離,也就是最小化正向影片文字對之間的距離,同時最大化負影片文字對之間的距離。
經過影片文字對的對比訓練之後,進入訓練第二階段,研究人員透過遮罩影片建模框架,來訓練模型預測影片中缺失的部分,而與標準方法不同的地方是,研究人員會要模型同時預測影片的整體特徵,和影片中每一個小部分的特徵,以有效利用第一階段訓練所獲得的知識。在這個階段,研究人員還會隨機打亂預測出來的Token,以防止模型學到一些捷徑,像是模型可能依據固定順序或是模式就能做出預測,而隨機的方式可迫使模型深入理解影片內容,而不只是依賴表面特徵。
實驗證實VideoPrism在多個影片理解任務表現良好,VideoPrism擁有廣泛的應用範圍,能夠處理影片分類、定位、影片文字檢索、影片字幕生成、問答和科學影片理解。而在33個基準測試中,VideoPrism在其中30個達到了目前最好的表現,在影片分類與定位任務方面,VideoPrism超越現有其他先進的基礎模型。
當VideoPrism能夠與大型語言模型結合時,VideoPrism在影片文字檢索、字幕生成和影片問答任務中,更可展現強大的能力,在多數視覺語言基準測試中豎立新標竿。整體而言,VideoPrism為一款強大且多功能的通用影片編碼器,而其有效性和靈活性可被用於廣泛的影片理解任務。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09

2026-02-10


2026-02-10

2026-02-10