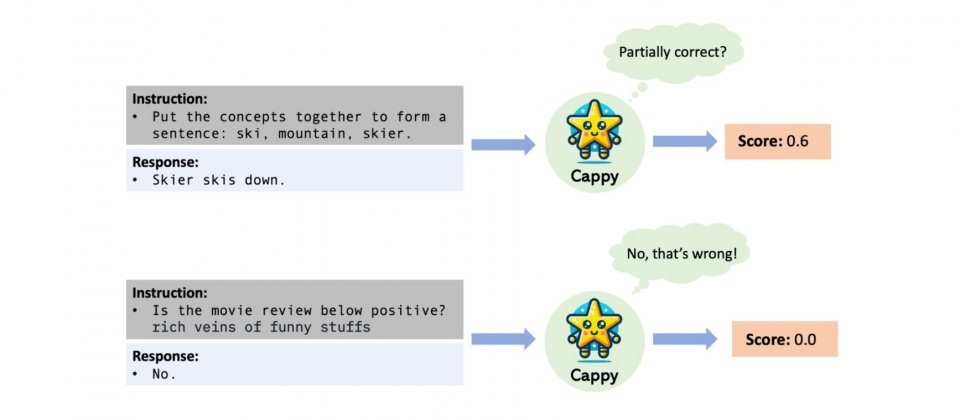
Google開發一個稱為Cappy的評分器,Cappy以RoBERTa語言模型為基礎,使用指令和候選回應作為輸入,並輸出0到1之間的分數,這個分數代表著回應相對於指令的估計正確性。Cappy可獨立執行分類任務,或是作為大型語言模型的輔助元件,有助於提升大型語言模型下游應用的效能。
研究人員指出,大型語言模型的發展出現一種新範式,該範式將各種自然語言任務整合在一個指令遵循框架中。這種方法將不同任務標準化為指令與回應的形式,使得模型能夠理解和執行廣泛的語言任務,進而提高泛化能力,大型語言模型可透過理解和解決全新指令,來處理未見過的任務,這代表一種從特定任務學習,移向多任務和指令驅動學習的轉變。
但是要只用指令來理解和解決各種任務,多任務大型語言模型的參數可能高達千億,要操作這麼龐大的模型,需要大量的運算能力,以及大量的GPU和TPU等加速器的記憶體,這些要求導致大型語言訓練和推理成本高昂效率不彰。而且強大的多任務大型語言模型通常是閉源的,因此也難以被調整並應用於新的任務中。
而事實上,要使用單一多任務大型語言模型管理所有任務仍然非常困難,特別是在處理複雜、個人化,且難以簡潔地用指令定義的任務。研究人員也指出,下游訓練資料的大小,通常不足以良好地訓練模型,也就是説,要讓大型語言模型可以良好地適應特定任務,需要經過足夠的資料訓練,但在下游訓練資料有限的情況下,模型可能無法很好地執行任務。
因此在大型語言的應用上出現一種需求,希望可以不需要大量儲存和記憶體資源,也不需要完全存取模型內部結構,就能夠對大型語言模型進行有效的下游任務訓練或是適應的需求。Cappy便是在這種需求下發展的研究成果,運用輕量級的預訓練評分器來輔助大型語言模型,以達到更好的效能和效率。
研究人員從問答、情感分析和摘要等任務收集一系列資料集,針對個別任務,研究人員將資料集中的每個例子轉換成為指令與回應的資料對,並且對每個指令與回應資料對給予正確性分數,Cappy透過學習這些資料,使其能夠評估指令與回應的適合程度。
Cappy可應用於大型語言模型輸出的候選機制,當有下游任務訓練資料可用於微調Cappy,便具備了適應下游任務的能力。將指令以及一組大型語言模型的候選回應作為輸入,Cappy會對候選回應生成分數,選擇分數最高的回應作為最終輸出,以提高大型語言模型的預測效能。如此經微調的Cappy便能與大型語言模型協調運作,提升大型語言在下游任務上的效能。
與其他大型語言模型調整策略相比,用Cappy適應大型語言模型可減少對裝置記憶體的需求,因為能夠避免對下游任務大型語言模型參數進行反向傳播(Back-Propagation)的需要,而且Cappy也不需要存取語言模型參數,因此能夠與閉源多任務大型語言模型相容,像是僅透過Web API存取的模型。
Google研究人員評估了Cappy,在自然語言提示工具包PromptSource的11項語言理解分類任務中的表現,Cappy雖然僅擁有3.6億參數,效能卻優於規模更大的OPT-175B和OPT-IML-30B模型,且與當前先進的多任務大型語言模型T0-11B和OPT-IML-175B準確度相當。研究人員解釋,評分預訓練策略,使得Cappy的效能與參數效率突出。
熱門新聞

2026-02-09

2026-02-10

2026-02-06

2026-02-09

2026-02-10

2026-02-10

2026-02-09
