Google發表了能夠理解使用者介面和資訊圖表的模型ScreenAI,ScreenAI建立在視覺語言模型PaLI基礎之上,並採用圖片轉文字模型pix2struct的彈性區塊處理策略(Flexible Patching Strategy)強化,再加上以特別製作的資料集和任務組合進行訓練,使得ScreenAI擁有目前最先進的解讀圖表能力。
ScreenAI是一個結合視覺和語言處理能力的模型,用於理解用戶介面和資訊圖表。ScreenAI以PaLI架構為基礎,由多模態編碼器(Multimodal Encoder)和自回歸解碼器(Autoregressive Decoder)組成。PaLI編碼器使用視覺Transformer(ViT)來創建圖像嵌入,並結合文字嵌入,使得模型能夠同時理解圖像和相關文字資訊。
特別的是,ScreenAI採用了pix2struct模型的彈性區塊處理策略,因此ScreenAI更能夠處理不同長寬比的圖像,研究人員解釋,這與傳統固定網格模式不同,彈性區塊處理策略的網格尺寸能保留輸入圖像的原始長寬比,因此可以提升模型對於不同類型圖像的處理能力。
ScreenAI模型的訓練階段分為兩階段,第一是預訓練階段,第二則是微調階段。ScreenAI預訓練階段採用自監督學習自動生成資料標籤,這些標籤被用於訓練ViT和語言模型,而在微調階段時,ViT參數便會被凍結,大部分使用的資料由人工評估員手動標記,以微調模型提高特定任務的表現。
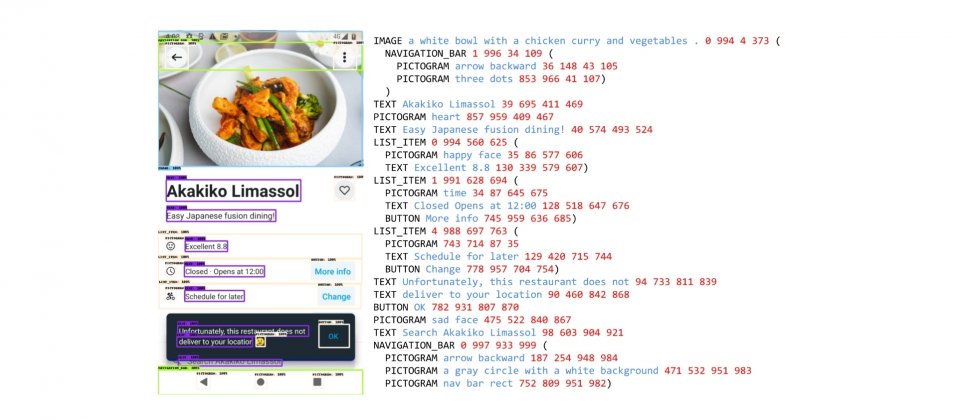
ScreenAI的訓練資料集主要來自不同裝置的螢幕截圖,包括了桌面電腦、手機和平板,由於來源豐富,確保了資料集在視覺樣式、布局配置和使用者介面元素的多樣性。研究人員使用基於DETR模型的布局註解工具,辨識並標記出各種使用者介面元素,像是圖像、象形圖(Pictogram)按鈕、文字以及空間關係等。
而象形圖則會再經過一個專門的分類器進一步分析,該分類器能夠區分77種圖標類型,而分類器未涵蓋的資訊圖表和圖像,則使用PaLI圖說模型產生符合上下文資訊的描述性文字。另外,圖片上的文字還會經過OCR引擎辨識,與註解文字相結合,創建出每個螢幕截圖詳細的描述。
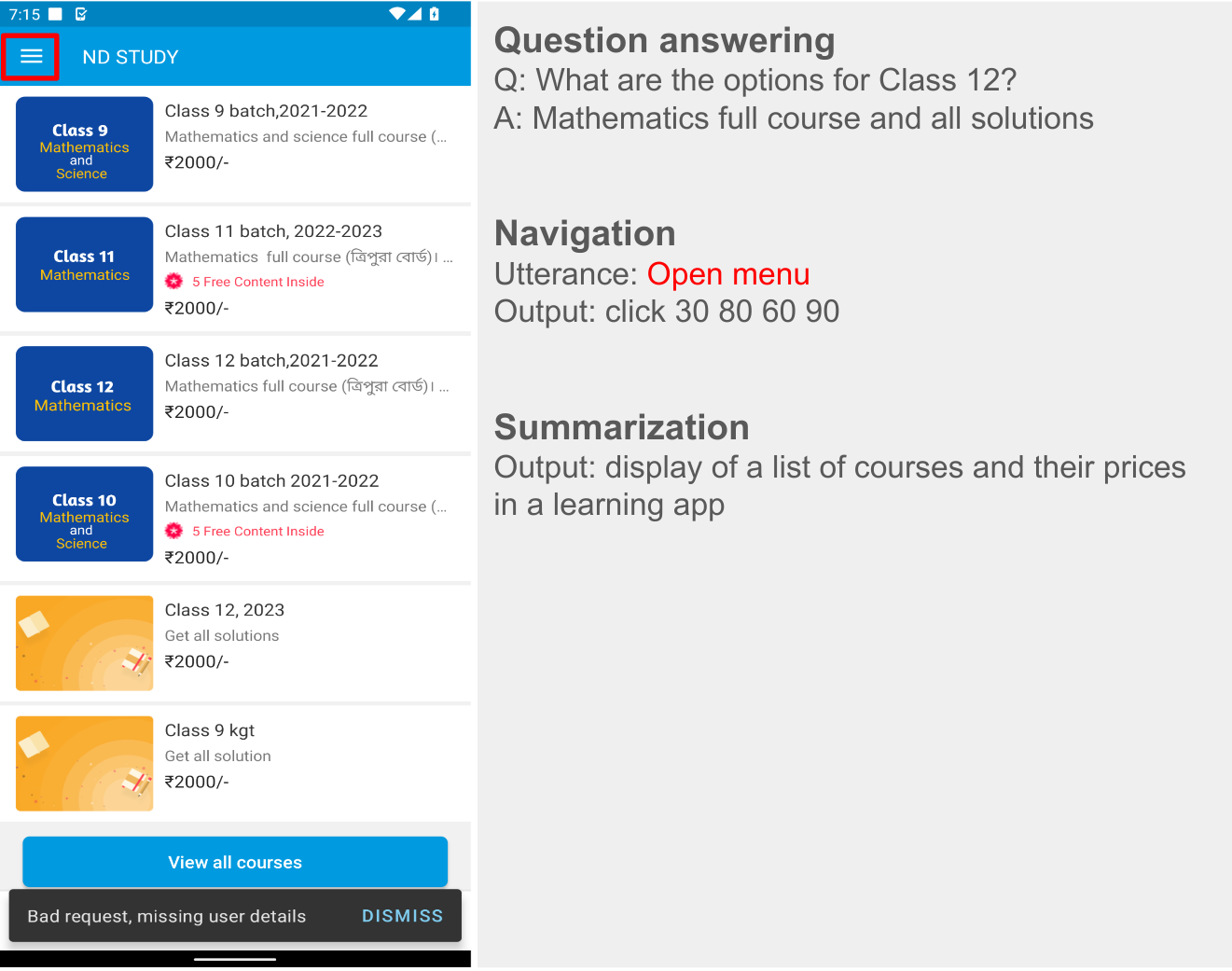
註解工具生成的螢幕描述文字,還需要經過語言模型PaLM 2強化資料的多樣性,才會成為最終的訓練資料集。PaLM 2會根據截圖描述以及問答、螢幕導覽和螢幕總結等任務,生成輸入與輸出資料對,像是根據店家資訊的截圖描述,生成「餐廳何時開門?」的問題和相對應的答案。由於PaLM 2可根據不同類型的任務和互動,創建多樣化和更全面的資料集,使得ScreenAI能夠更好地理解和回應各種用戶的需求和行為。
ScreenAI僅擁有50億參數卻非常高效,在處理用戶介面和資訊圖表相關任務WebSRC和MoTIF,與當前規模相近的先進模型相比,得到最高的分數,而在圖表問答相關的任務Chart QA、DocVQA和InfographicVQA,也是當前同類模型中表現最佳者。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-06

2026-02-09

2026-02-09