
GitHub
資料暨AI業者Databricks周三(3/27)開源了通用大型語言模型(LLM)DBRX,宣稱DBRX在各式標準的基準測試上超越了坊間所有的開源模型,也在大多數的基準測試上擊敗GPT 3.5。
DBRX是個基於Transformer解碼器的大型語言模型,採用細粒度的混合專家(Mixture of Experts,MoE)架構,具備1,320億個參數,當中有360億個經常處於活動狀態,於12T Token的文字與程式碼資料上進行預訓練。
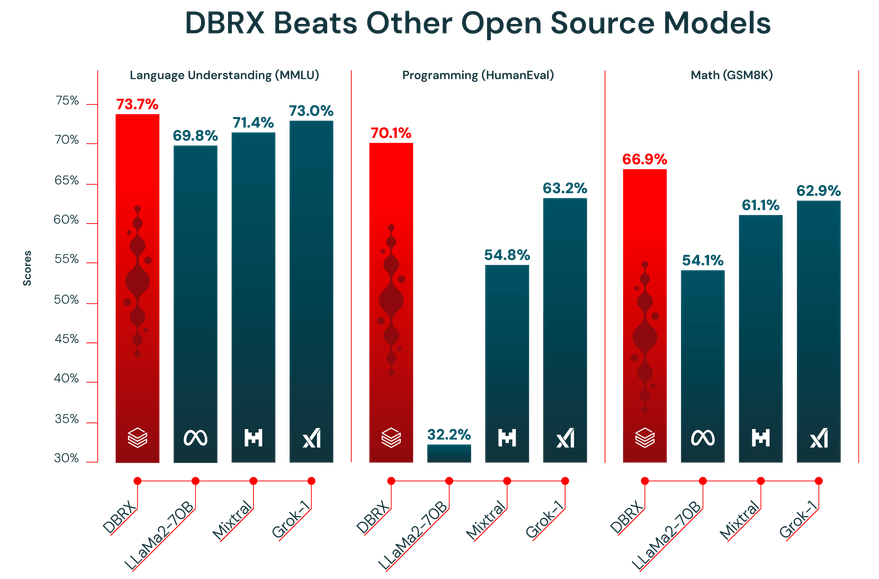
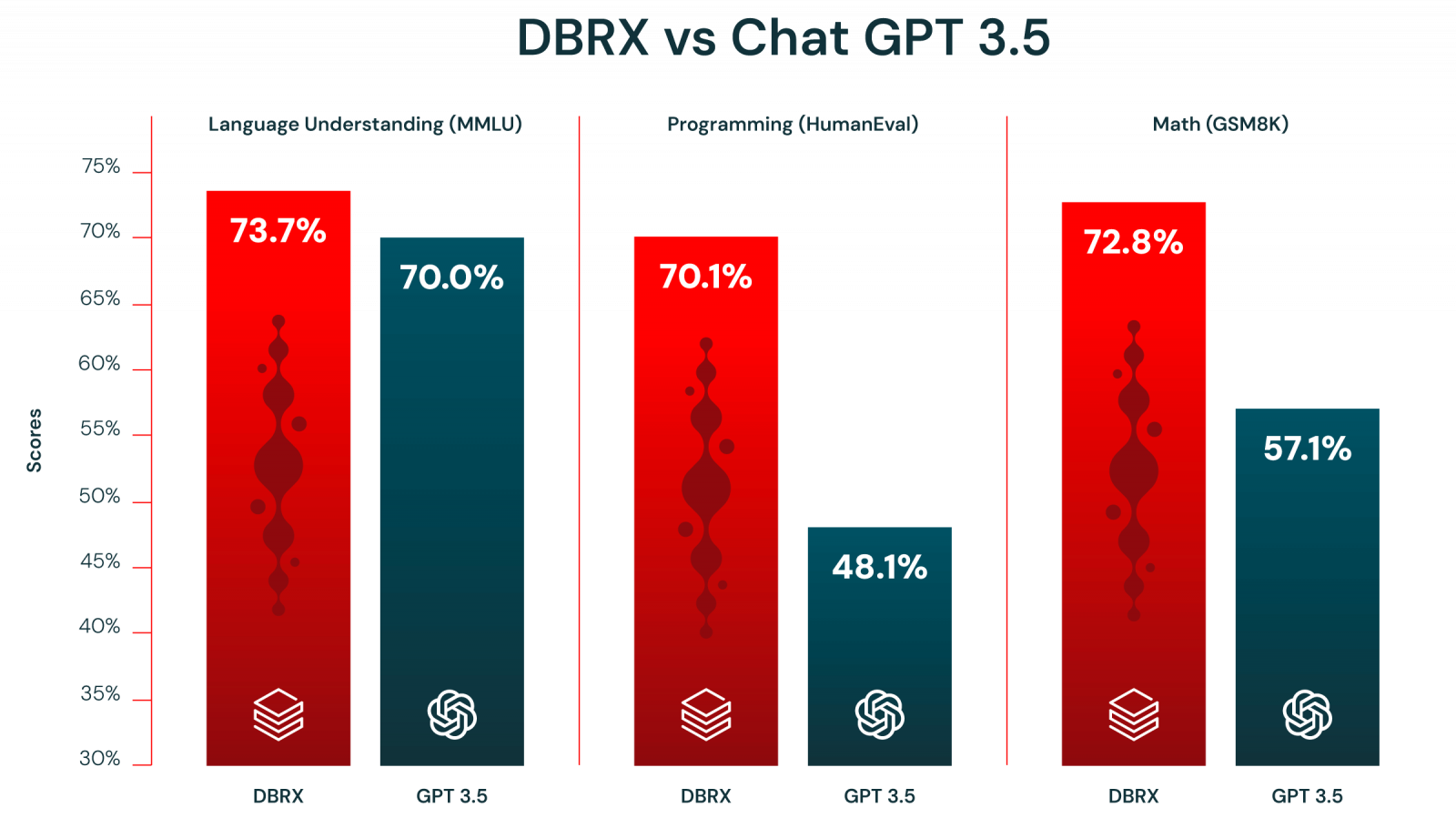
相較於市場上既有的LLaMA2-70B、Mixtral和Grok-1等開源模型,DBRX在語言理解(MMLU)、程式設計(HumanEval)及數學邏輯(GSM8K)等基準測試上的表現明顯勝出。此外,DBRX在上述3項基準測試中亦凌駕OpenAI的GPT 3.5。
若比較更高階的GPT 4、Claude 3及Gemini 1.0 Pro,那麼DBRX在語言理解上贏過Gemini 1.0 Pro,在程式設計上贏過GPT 4與Gemini 1.0 Pro。
Databricks亦強調,DBRX是個採用MegaBlocks研究與開源專案的混合專家(MoE)模型,得以實現快速的Token處理能力,也相信未來將有更多的開源模型採用MoE架構,因為MoE可用來訓練更大的模型,並以更快的吞吐量來提供服務。
Databricks生成式AI副總裁Naveen Rao 向《TechCrunch》透露,該公司花了兩個月及1,000萬美元的成本來訓練DBRX,而經過訓練的DBRX可提供各種主題,現已針對英文進行優化,但也支援法文、西班牙文與德文。
不過,《TechCrunch》也指出,一般人並不容易使用DBRX,因為要執行DBRX至少必須配備4個Nvidia H100 GPU或其它GPU,且光一個H100的成本就高達數萬美元,對許多開發者或個人企業家而言是遙不可及的。
熱門新聞

2026-02-06

2026-02-06

2026-02-06

2026-02-06
")
")
2026-02-09
")
2026-02-09

2026-02-09