重點新聞(0329~0405)
生成式AI Google 效能
生成模型越大未必越好,Google揭露新研究發現
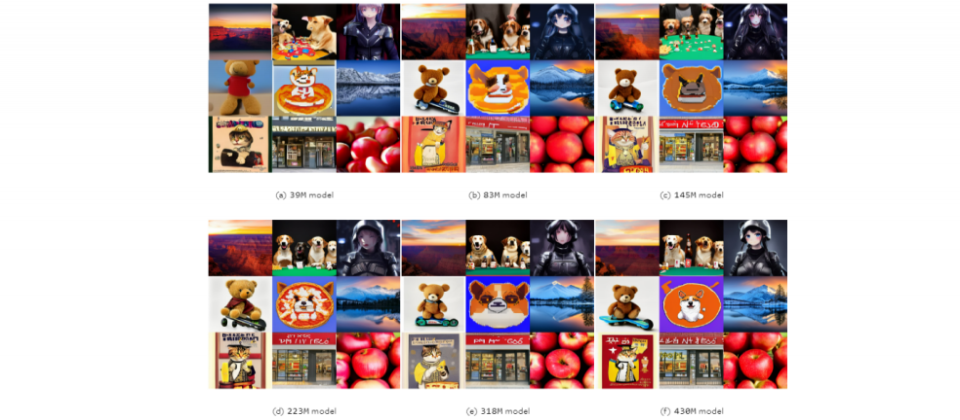
Google聯手約翰霍普金斯大學,針對圖像生成模型做了項擴展性和效率的研究,並發現模型並非越大越好。進一步來說,團隊鎖定潛在擴散模型(LDM)的大小和採樣效率,其中,LDM是圖像生成的常用模型,擅長根據文字描述,生成高品質圖像。
在研究中,團隊訓練了12個文字轉圖像的LDM,這些模型大小不一,從3,900萬到50億個參數不等。接著,團隊用各種任務來評估模型表現,包括文字生成圖像、提高解析度、主題驅動的合成等。他們發現,在給定的有限運算資源下,小模型的表現比大模型要好,能產生更高品質的圖像。而且,小模型的採樣效率在各種擴散採樣器中都是一樣的,就算在蒸餾模型中也是。換句話說,小模型的優勢,不限於特定的取樣技術或模型壓縮方法。
不過,研究也發現,當運算資源沒特別限制時,大模型依然擅長生成顆粒度更細緻的細節。意思是,小模型雖然可能更有效率,但在某些情況下,仍需要大模型。團隊認為,該研究影響深遠,因為了解LDM擴展性、模型大小和效能的狀態後,開發者可在效率和品之間取得平衡,打造所需的AI模型。(詳全文)

生成式AI 國科會 選拔賽
國科會發起GenAI Stars生成式AI百工百業應用選拔
為推動生成式AI應用,國科會宣布舉辦首屆GenAI Stars生成式AI百工百業應用選拔,分為創意創客組、創新創業組兩大類。其中,創意創客組是針對高中職、大專院校和社會人士,可細分為高中職組和大專社會組兩組,參賽者可使用生成式AI工具,來進行創意應用,同時,創意創客組參賽者也能參加企業挑戰題目,也就是由多家知名企業提出的題目,詳細出題內容、解題資源和獎勵預計在4月12日公布。
而創新創業組則針對國內外企業、新創、學研單位、政府機關或自組團隊參加,競賽主題為與生成式AI有關的企業內部解決方案,或是創新產品與服務,評審將優先考量有邊緣運算的應用。特別的是,通過複審、進入決審的20組團隊,可獲得每隊10萬元輔導金、技術資源(如算力、GenAI工具等)、深度輔導資源,最後決審將篩選出的前三名隊伍,可分別獲得150萬元、100萬元和50萬元。GenAI Stars生成式AI百工百業應用選拔即日起開放報名,至5月15日下午3點為止。(詳全文)
文字嵌入 Google Gecko
Google發表強大的文字嵌入模型Gecko
日前,Google團隊發表一款文字嵌入模型Gecko,可將大型語言模型(LLM)提取到檢索器中,來實現強大的檢索效能。進一步來說,文字嵌入模型目的是將自然語言轉換為密集向量,將語義相似的文字放在距離相近的嵌入空間,就像是電腦的翻譯機,將文字轉為電腦可理解的數字。有了文字嵌入,電腦就能用來執行各種下游任務,如文件檢索、分類等。
而Gecko是一款通用的文字嵌入模型,有別於以往只為單個下游任務建立各自的嵌入模型,Gecko由LLM加持,單一個模型就能支援多種下游任務。Gecko的運作方式可分為2步驟,首先是用LLM生成一組組多樣的資料,再來是精煉這些資料品質,也就是為每個查詢,用檢索方式找出一系列的候選文章段落,並用同一個LLM,來對文章段落的正負值重新貼標。
也就是說,在一個大型未標註段落的語料庫中,團隊使用少樣本提示,讓LLM為每個段落生成相關的任務和查詢。接著,他們將預訓練嵌入模型,嵌入一連串的任務和查詢,來獲得最相近的段落,並用LLM對段落重新排序,同時根據LLM評分來得出正負向的段落。這種方法,讓Gecko實現強大的檢索表現,不過該模型尚未開源。(詳全文)

Cloudflare Workers AI Hugging Face
Workers AI正式上線,還支援Hugging Face一鍵部署模型
最近,CDN服務大廠Cloudflare發布推理平臺Workers AI的一系列更新,包括完成公測、正式上線,能提供更高的可靠性和效能,並公開定價,還在目錄中新增更多模型。在效能部分,他們升級了Workers AI內建的負載平衡,另也提供更多城市、更多GPU資源來處理請求,還能靈活將請求分派至可用站點。在正式版本中,Cloudflare也提高了模型速度上限,將原本大型語言模型(LLM)每分鐘只能接收50個請求,提高至每分鐘300個請求,小模型則是每分鐘1,500個至3,000個。
此外,Workers AI還與Hugging Face聯手,新添了可支援的4個模型,包括 Mistral 7B v0.2、Mistral 7B、Google的Gemma 7B和Starling-LM-7B-beta。而且,使用者可在Hugging Face的模型卡頁面,在部署欄位點擊Cloudflare Workers AI,就能利用Cloudflare全球GPU網路資源來直接部署模型。目前,Hugging Face支援的模型共有14個,接下來還會有更多模型加入。
另一方面,Workers AI也發布了10個非測試版的計價器,來提供使用者更划算的用法。與之類似的還有新版儀表板,可顯示跨模型的使用狀況分析,包括神經元計算,可幫助使用者預測價格。Cloudflare也更新了AI試煉場,可讓使用者快速測試和比較不同的模型,並設定提示和參數。(詳全文)
LLM Opera 瀏覽器
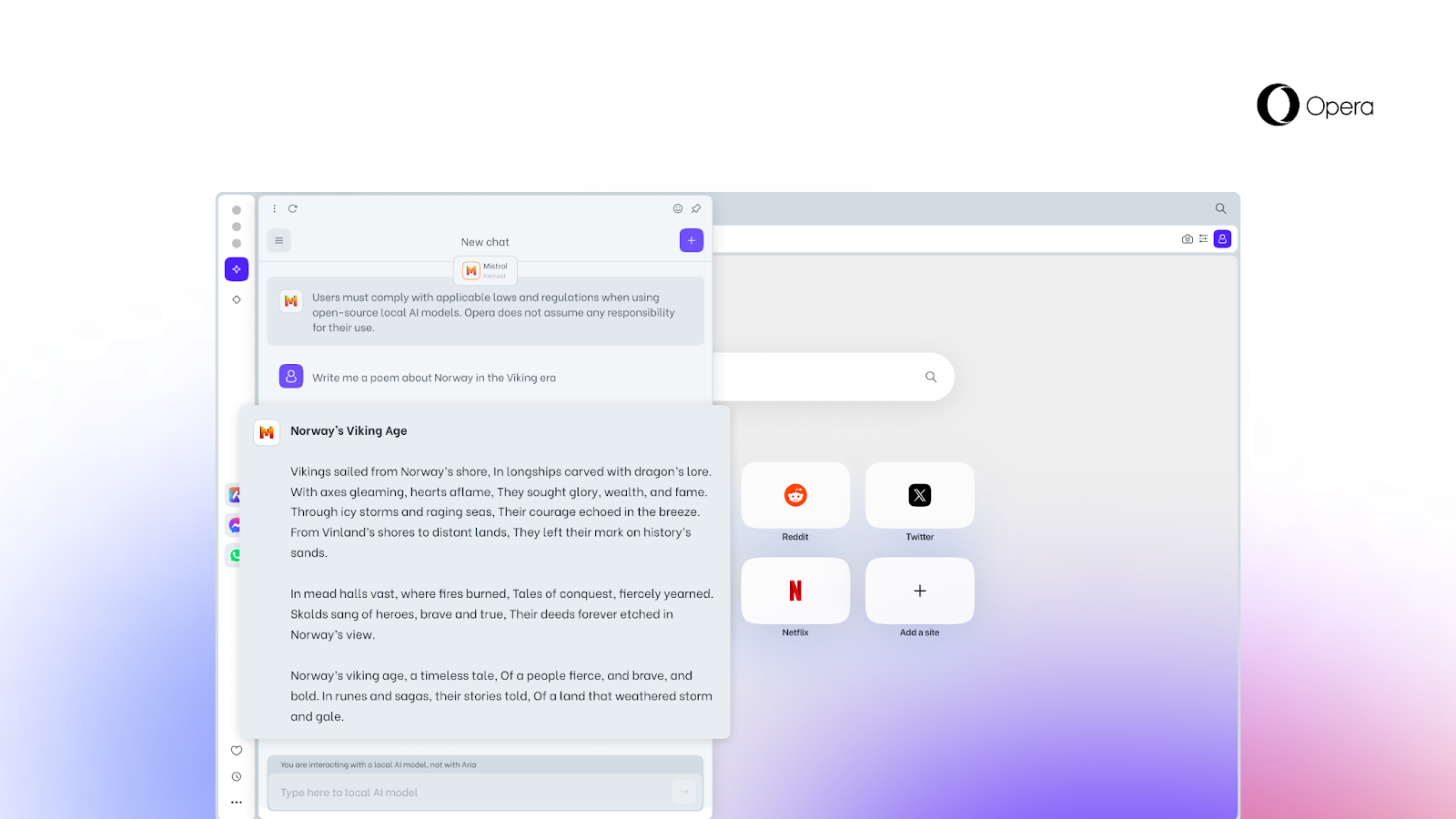
在本機就能執行和測試LLM!Opera瀏覽器推出新功能
網頁瀏覽器Opera最近發布一項新功能,用戶可將大型語言模型(LLM)下載到本機端執行或測試,不必再連上伺服器端,意味著資料不須離開電腦。在這項新功能中,Opera支援近50個系列、共150款本機端LLM,包括Meta的Llama、Vicuna、Google的Gemma和Mistral AI的Mixtral等,允許用戶透過瀏覽器下載。
新功能目前以測試版發布給Opera One開發人員。Opera One是去年6月推出的AI瀏覽器,整合原生AI技術的瀏覽器,目前也整合Opera自家的AI助理Aria Chat。目前,開發者可下載Opera One開發者版測試,在本機上使用所支援的LLM和Opera實驗性AI功能。(詳全文)
天氣 Google 生成式AI
Google打造生成式AI天氣預報模型
最近,Google發表最新天氣預報研究,採用機率擴散模型生成式AI,開發出SEEDS天氣預報模型,可有效、大規模產生天氣預報系集,成本還遠低於傳統物理預報模型。機率擴散模型是一種機器學習生成式AI技術,實作上可分為2步驟,一是添加雜訊,從原始資料逐步增加隨機雜訊,直到資料完全變成隨機雜訊。這個過程稱為前向擴散,就像是在一張清晰的圖片逐漸添加雜訊點,直到圖片上滿是隨機雜訊。再來是移除雜訊,由機率擴散模型反向擴散,將充滿雜訊的資料移除雜訊,最終恢復接近原始資料的新資料。
機率擴散模型中的機率性,就是在去雜訊的過程,每一步都考慮多種去雜訊的可能路徑,這種作法,能生成多種且高品質的資料樣本。這個能力,在天氣預報的應用中,能生成一系列可能的天氣狀況,也就是系集預報,來反應未來天氣的不確定性和多樣性。最重要的是,與需要超級電腦耗費數小時運算的傳統天氣預測相比,SEEDS模型的計算成本幾乎可忽略,在Google雲端TPUv3-32執行個體上,每3分鐘就能產生256個系集成員。(詳全文)

Azure AI 微軟 提示注入
微軟推出Azure AI安全工具,防止惡意提示和AI幻覺
為防止Azure AI服務和模型,遭輸入惡意指令產出有害內容、洩露個資等問題,微軟最近發布多項工具,可偵測和防範惡意提示,也能防範AI幻覺、模型濫用等問題,目前已提供部份功能測試。
進一步來說,這些工具包括提示防護罩及AI模型幻覺偵測、系統範本、越獄評估工具和風險與安全監控。其中,提示防護罩能即時偵測、阻斷基礎模型接收到的惡意提示,另一個是真實性(Groundedness)偵測工具,能偵測文字結果的不真實內容,防範AI模型幻覺問題。另外,微軟也將在Azure AI Studio和Azure OpenAI Service加入安全的系統訊息範本,讓AI應用開發者能建立安全的系統訊息,導引模型使用訓練資料和正確的行為。
另一個新工具則是自動化越獄評估,可偵測AI應用被越獄攻擊、產出暴力、自殘、色情、仇恨、歧視內容的可能性,也會以自然語言解釋評估結果。最後,微軟也提供AI應用風險與安全監控工具,能針對黑名單所封鎖的產出內容,提供數量、嚴重性和內容類別,也能分析被標示為有害的用戶輸入訊息,並根據上下文訊號判斷用戶是否濫用。(詳全文)
xAI Grok-1.5 X
xAI發表Grok-1.5
繼於3月17日開源大型語言模型Grok-1後,xAI再於3月28日發表Grok-1.5,新版本將支援16倍的脈絡長度,預計近期釋出,並成為X上Grok聊天機器人的底層模型。xAI說明,Grok-1.5是在基於JAX、Rust和Kubernetes的客製化分散式訓練框架上建置,能讓團隊輕鬆測試原型,同時大規模訓練新架。這款客製化的訓練協調器,可自動偵測有問題的節點,並從訓練任務中剔除。為降低故障時的停機事件,團隊也優化了檢查點、資料載入和訓練任務的重新啟動機制。
與第一代相比,Grok-1.5有不少進展,在許多基準測試上直追或超越Claude 3 Sonnet和Claude 2,比如Grok-1.5在MMLU(大規模多工語言理解)基準測試的成績為81.3%,超越Claude 2的75%與Claude 3 Sonnet的79%。此外,Grok-1.5也支援128K個Token的脈絡,記憶能力為第一版的16倍,更擅長處理長文件。(詳全文)
Nvidia MLPerf 生成式AI
Nvidia在MLPerf基準測試拿下2個最快
日前,MLCommons發布MLPerf Inference v4基準測試套件的最新結果,Nvidia一次拿下2個模型最快的冠軍,包括資料中心類別的文生圖模型Stable Diffusion XL和開源語言模型Llama 2 70B。這兩個模型,都是這次測試新納入的模型。
MLPerf Inference基準測試套件可分為資料中心和邊緣系統兩個類別,目的是要衡量硬體系統,在各種場景中執行AI模型的速度。就這次新添的模型來說,Llama 2 70B比MLPerf Inference v3.1所納入的GPT-J模型,大了一個量級,是測試高階系統的良好基準。而Stable Diffusion XL則有26億參數,透過生成大量圖像,能透過計算硬體系統的延遲和吞吐量等指標,來了解整體效能。而在邊緣系統類別中,新增的Stable Diffusion XL模型測試則由Wiwynn系統拿下冠軍。(詳全文)
圖片來源/Google、國科會、Opera
AI近期新聞
1. 微軟研究團隊發表AllHands,一種LLM大規模回饋分析框架
2. OpenAI將在東京開設新分部
資料來源:iThome整理,2024年4月
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10