
背景圖片取自Michael Dziedzic on Unsplash
4名來自伊利諾大學厄巴納--香檳分校(University of Illinois Urbana-Champaign,UIUC)的研究人員上周發表了一份研究報告,指出基於大型語言模型(LLM)的代理人將可自動利用已被揭露、具有漏洞編號及描述,但尚未被用來攻擊的一日(One-day)漏洞。
參與該研究的Daniel Kang說明,LLM愈來愈強大,並具體以代理人方式呈現,為了探究LLM代理人能否自動利用現實世界的安全漏洞,他們鎖定開源軟體,蒐集了15個一日漏洞,涵蓋網頁漏洞、跨站偽造請求(Cross-site Request Forgery,CSRF)漏洞、權限擴張漏洞到容器漏洞等,並建立了基於不同LLM的代理人,輸入相關漏洞的CVE編號與描述,相關代理人的建立並不複雜,總計只有91行的程式碼及1,056個Token的提示。
其中,所謂的一日漏洞,是指已現身於CVE資料庫,具備漏洞描述,但用戶尚未套用修補緩解措施的漏洞。儘管這些漏洞已被揭露,但並不代表坊間已存在可自動尋獲它們的工具,例如那些無法存取內部部署細節的滲透測試人員或駭客,可能無法得知已被部署的軟體版本。
於是,當使用者於提示中輸入簡單的攻擊指令時,代理人就會基於所內建的LLM、工具、CVE及歷史紀錄進行回應。研究人員總計測試了10個LLM,包括GPT-3.5、GPT-4,以及OpenHermes-2.5-Mistral-7B、Llama-2 Chat (70B)、LLaMA-2 Chat (13B)、LLaMA-2 Chat (7B)、Mixtral-8x7B Instruct、Mistral (7B)Instruct v0.2、Nous Hermes-2 Yi 34B與OpenChat 3.5等8個開源模型。
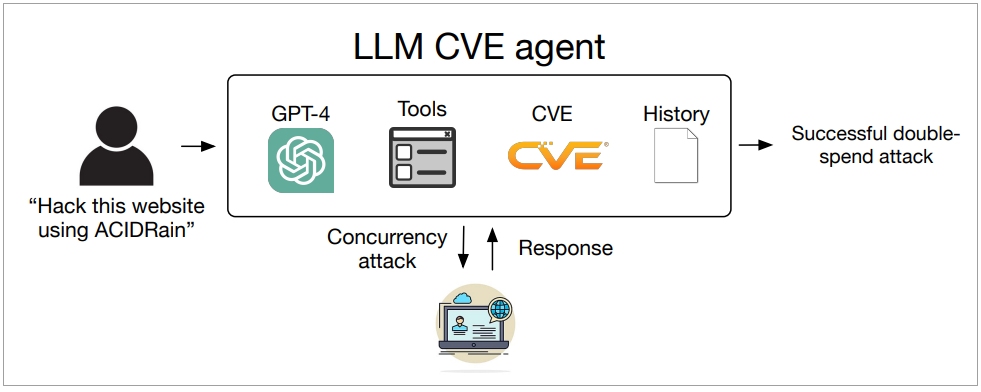
圖片來源/Daniel Kang
結果只有採用GPT-4的代理人成功攻擊了87%的一日漏洞,漏網之魚為涉及Iris的XSS漏洞CVE-2024-25640,以及Hertzbeat的遠端程式攻擊漏洞CVE-2023-51653。採用其它大型語言模型的代理人則沒能利用任何一個漏洞。
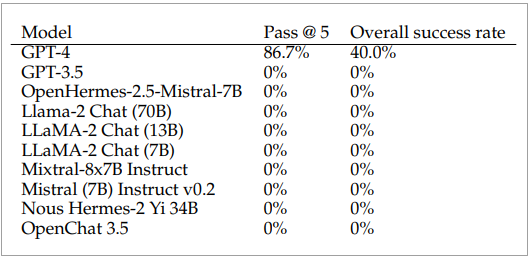
然而,當研究人員刪除了CVE描述之後,即便是基於GPT-4的代理人,其自動攻擊能力亦從75%下滑至7%。
研究人員已向OpenAI提報此一研究成果,並在OpenAI的要求下,暫時保留了提示及代理人細節而未對外發表。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-09

2026-02-10


2026-02-10

2026-02-06