
在微軟、Meta、Google等相繼公布AI模型後,蘋果終於發聲,宣布並開源可在蘋果裝置端執行的AI模型OpenELM家族以及訓練及推論框架,最小版本僅2.7億參數。
OpenELM全名為開源高效語言模型(Open-source Efficient Language Model),蘋果已在Hugging Face公開了4種參數規模的模型,涵括2.7億、4.5億、11億及30億,但每個規模又分成預訓練及指令調校版本,因此OpenELM提供了8種版本。蘋果的開源提供完整訓練和評估框架,也提供將模型轉換成MLX函式庫的程式碼,以便開發人員在蘋果裝置上推論和微調。

在訓練方面,OpenELM模型是以CoreNet函式庫作為訓練框架,其預訓練資料集包含了RefinedWeb、去除重覆資料的PILE、RedPajama和Dolma v1.6各一個子資料集,共1.8兆token。蘋果說明,OpenELM融合了分層擴展策略,能將模型參數有效分配到transformer模型各層,以提升準確率。舉例而言,11億參數版本的OpenELM準確率較(12億參數版本的)OLMo準確率高出2.36%,但預訓練資料token僅其一半。
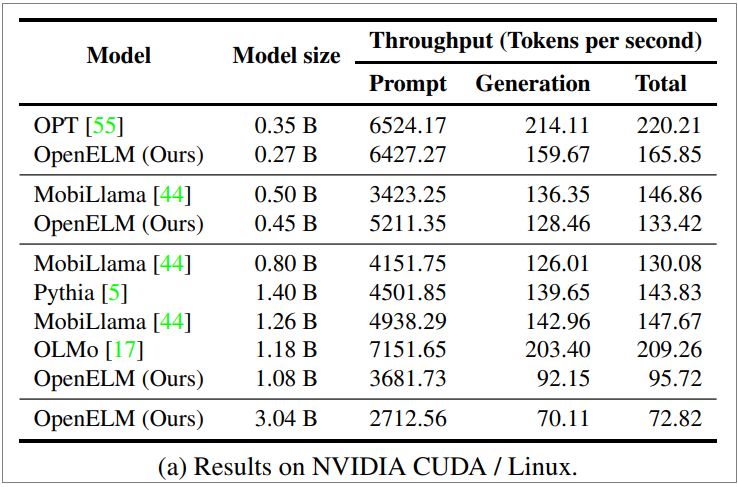
蘋果也列出在一臺Nvidia GPU/Ubuntu筆電上進行提示執行及程式碼生成二個任務上,和其他開源模型的效能比較(如下圖)。數據顯示OpenELM 4.5億參數版本在提示執行效能已超過MobiLama,2.7億參數版本比起OPT也相差不遠,但在程式碼生成任務上,各個版本都還有待加強。蘋果也列出了在Apple Silicon-based MacBook Pro上各版本OpenELM的執行數據。
這是蘋果繼去年十月悄悄開源多模語言模型Ferret及3月的MM1之後,再度公布的AI研發成果。但這次更為特別的是,OpenELM是可在蘋果裝置上執行的語言模型。本周稍早微軟也釋出了可在筆電上執行的小語言模型(SLM)Phi-3系列,最小版本為38億參數。微軟強調Phi-3在語言理解、推理、數學及寫程式等能力上,比更多參數的模型如GPT-3.5 Turbo、Mistral還強大
蘋果與其他晶片業者包括英特爾、AMD、高通等,都可望在今年推出為AI模型執行設計的第一代或新一代晶片。最新Apple Silicon為M4,預計今年稍後問世,並在年底推出搭載M4晶片的Mac產品。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-09

2026-02-10


2026-02-10

2026-02-06