
Google於周二(5/14)舉行的Google I/O開發者大會上,發表了十多項全新或改善的服務與產品,幾乎全都圍繞著人工智慧(AI),包括推出新的文字生成影片模型Veo,第六代的Google Cloud TPU──Trillium,開源視覺語言模型PaliGemma,於Gemini模型家族增添Gemini 1.5 Flash,以及於搜尋中整合AI Overviews,於Google Photo中嵌入Ask Photos with Gemini等。
Trillium TPU峰值運算性能增加了4.7倍,效率提升67%

TPU的全名為張量處理單元(Tensor Processing Unit),是Google專為神經網路機器學習所設計的特殊應用積體電路(ASIC),Google自2015年便開始於內部使用TPU,一直到2018才開始將其授權給第三方使用。
Google積極開發TPU,上一版的Cloud TPU v5p甫於去年12月發表,第六代的Trillium在高頻寬記憶體(HBM)的容量與頻寬都提高了一倍,晶片互連頻寬也提高一倍,同時它配備第三代、專門用來處理高階排序及推薦任務的SparseCore加速器;且其每個核心的峰值運算性能比TPU v5p增加了4.7倍,效率亦比TPU v5p多出了67%。
此外,Trillium在單一的Pod中最多可擴展到256個TPU,並可藉由多層技術(Multislice Technology)及Titanium智慧處理單元拓展至數百個Pod,可造就連結數十萬個晶片的超級電腦架構,以支援高性能運算任務。
想當然爾,Trillium TPU將支撐下一波AI模型的訓練,除了Google DeepMind將用它來訓練與服務未來的Gemini模型之外,也有其它業者已計畫利用Trillium TPU來訓練模型。同時Trillium TPU也會成為Google Cloud AI Hypercomputer超級電腦服務的基礎。
Gemini模型家族加入新成員Gemini 1.5 Flash

原本Google的Gemini模型家族有3種版本,分別是可於手機上運作的Gemini Nano、通用版的Gemini Pro,以及最強大的Gemini Ultra,但本周添了新血Gemini Flash,由於它奠基在Gemini 1.5上,目前稱為Gemini 1.5 Flash。
根據Google的解釋,Gemini 1.5 Flash是利用Gemini 1.5 Pro蒸餾而成,屬於Gemini 1.5 Pro的精簡版,它將大模型的基本知識與技能轉移到更小卻更高效的模型中。它們同樣支援100萬個Token的脈絡,但Gemini 1.5 Flash特別針對大規模容量及大規模的高頻率任務進行了最佳化,它是速度最快的Gemini API版本。
儘管它僅是輕量級的Gemini 1.5 Pro,但Google強調它對於大量資訊有強大的多模態推理能力,擅長摘要、聊天應用程式、圖像、影像字幕、從大量文字及表格中汲取資料等。
Gemini 1.5 Flash每100萬個Token的輸入費用為0.35美元,每100萬個Token的輸出費用則是0.53美元,比Gemini 1.5 Pro分別是3.5美元及1.75美元的價格便宜許多。
影片生成模型Veo報到
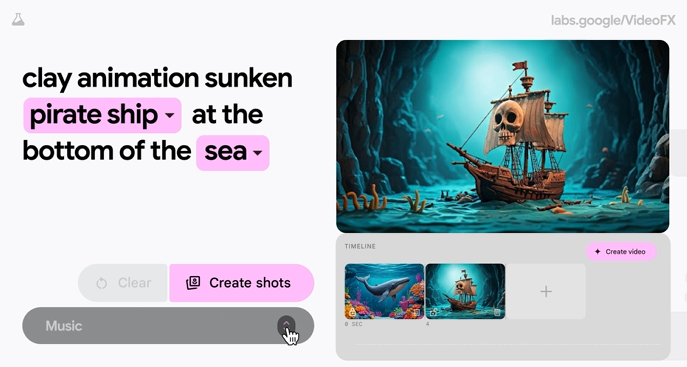
在推出了圖像生成模型Imagen及音樂生成模型Lyria之後,由Google所開發的影片生成模型Veo也在本周出爐。
根據DeepMind的說明,Veo可用來生成1080p且可超過1分鐘的高解析度影片,並支援不同電影與視覺風格。它可準確捕捉使用者所輸入文字的細微差別及語氣,還能理解各種電影效果的提示,例如延遲攝影或空拍。
Veo將使每個人都能製作影片,不管是經驗豐富的製作人、企圖分享知識的教育家,或只是充滿抱負的創作者。
Veo的部分功能將在未來幾周透過Google實驗室中的新工具VideoFX,遞送給部分創作者,目前屬封閉預覽階段,得先提出申請。
視覺語言模型PaliGemma可將視覺資訊轉為文字
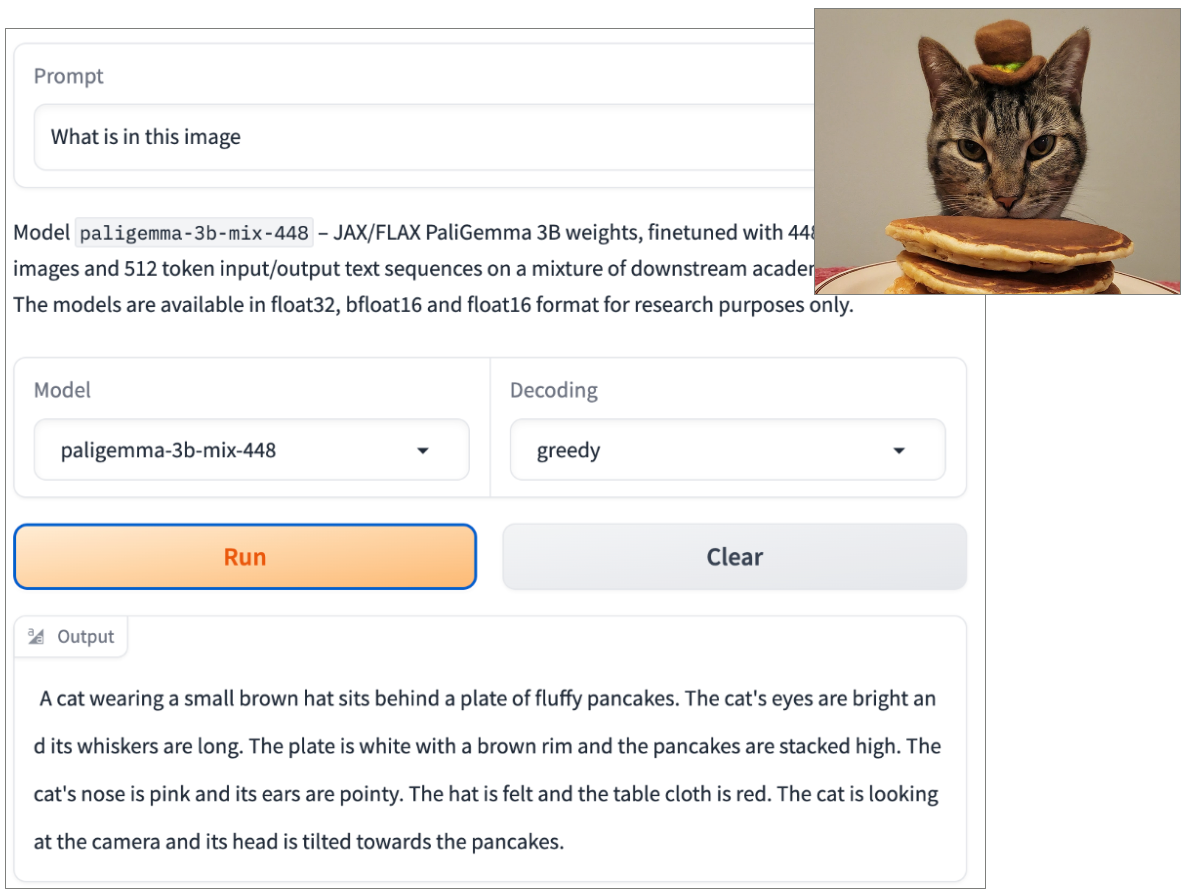
本周開源的視覺語言模型(Vision-Language Model,VLM)PaliGemma則是奠基在Google的開源語言模型Gemma及視覺模型SigLIP之上,它是個多模態模型,可輸入圖像或文字,並生成文字,支援多種視覺語言任務,例如圖像的字幕、短影片的字幕、視覺問答、閱讀文字、檢測物件,或是物件分割等。
PaliGemma是個小型語言模型,意謂著它不需要大量的記憶體或處理能力即可執行,適用於個人電腦、智慧型手機或物聯網裝置等資源受限的設備,可用來啟用更多的搜尋能力,或是幫助視障人士理解周圍的世界。
將AI整合至搜尋的AI Overviews與Ask Photos with Gemini
AI技術的發展最終還是要回歸到應用上。即日起,Google將在美國市場全面推出AI Overviews,這是Google在去年5月發表AI搜尋測試平臺Search Labs時所實驗的服務之一,如今將它正名為AI Overviews。
AI Overviews奠基在Gemini模型上,由於還在發展中,目前並沒有精確的定義,大抵是利用AI來協助搜尋用戶找到更完整、更有組織的答案。例如當使用者搜尋「閃電與打雷的連結」時,AI Overviews就會跳出一篇完整的答案,使用者可選擇簡化該答案,或是要求它更細緻地說明解答。
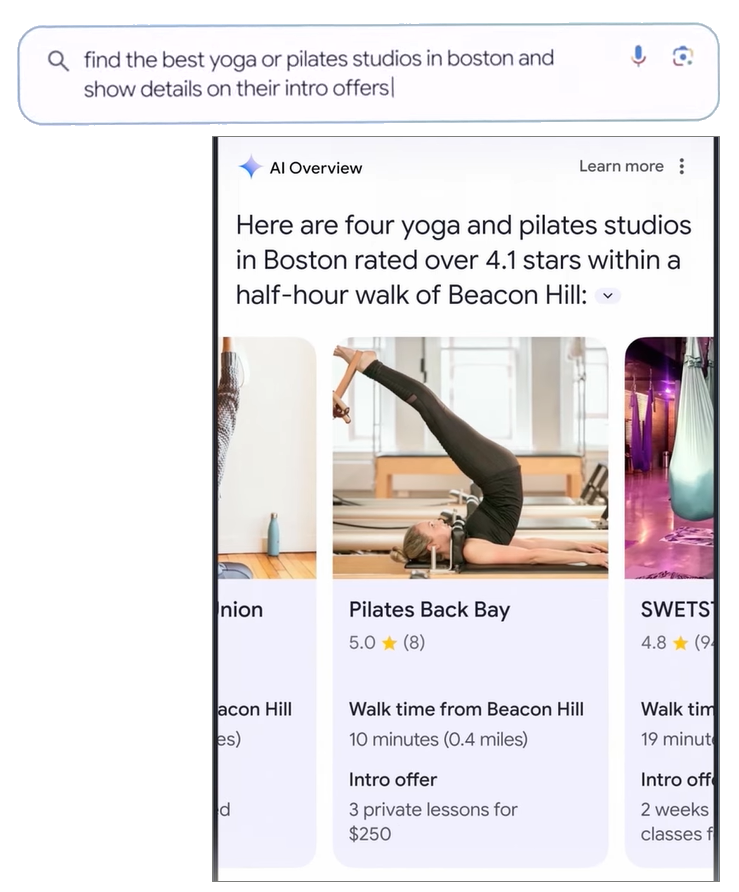
此外,Google也打算進一步強化AI Overviews的能力,藉由Gemini模型的多步驟推論功能,協助解答使用者的複雜問題,認為與其將問題分成不同的搜尋,不如一次就提出複雜的問題,例如要找一家熱門、位置好、交通方便而且有折扣的瑜珈教室,只要交給AI Overviews就能直接找出答案。該功能隨後將透過Search Labs開放預覽。
Ask Photos with Gemini則是將多模態模型應用在Google Photos的AI服務,亦即幫使用者於Google Photos中找到所需的照片,簡單的像是「秀出我去過的國家公園的最佳照片。」還能進一步詢問「我去年在哪裡露營?」或是「我的禮券何時會過期?」
Google計畫近日就會開始部署Ask Photos with Gemini,這是項實驗性功能,不確定能否成為正式功能。
圖片來源/Google
熱門新聞

2026-02-09

2026-02-10

2026-02-06

2026-02-09

2026-02-10

2026-02-10

2026-02-09
