
Google本周釋出了Gemma 2,相較於第一代僅提供20億(2B)及70億(7B)參數的版本,第二代提供了9B及27B兩種版本,除了具備更高的性能之外,也能在單個Nvidia H100 Tensor Core GPU或TPU上實現,大幅降低部署成本,開發人員現在已可透過Google AI Studio、Kaggle及Hugging Face Models存取Gemma 2,下個月便會現身於Google雲端機器學習平臺Vertex AI上。
Gemma是個開源且輕量版的AI模型,採用與Gemini同樣的研究及技術而打造,Gemma 2不僅在所有基準測試上都超越Gemma 1,9B版本的Gemma 2在MMLU、BBH及GSM8K測試,也都超越8B版本的Llama 3;27B版本的Gemma 2在MMLU、GSM8K、MATH等測試,則超越擁有314B參數的Grok-1。
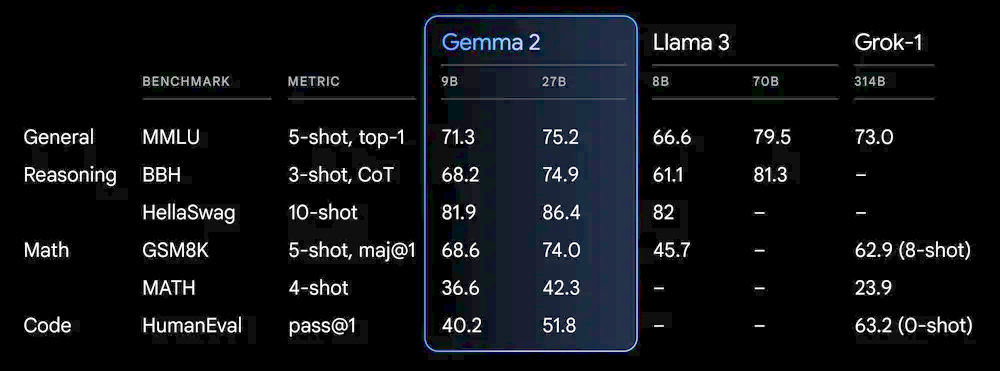
圖片來源/Google
此外,Google表示,27B版本的Gemma 2其設計就是為了要讓它能夠在單個Google Cloud TPU主機,或是單個Nvidia A100 80GB Tensor Core GPU,以及單個Nvidia H100 Tensor Core GPU執行全精度的高效推論,在維持高性能的同時大幅降低成本,讓開發者更容易部署AI。
因此,Gemma 2可在高階遊戲筆電、高階桌上型電腦,以及雲端上執行。Google建議使用者可於Google AI Studio上以最高精度執行,在CPU上透過Gemma.cpp 使用量化版本來解鎖本地端性能;也能透過Hugging Face Transformers,於具備Nvidia RTX或GeForce RTX的家中電腦使用。
相較於第一代,Gemma 2不僅有更高的性能、推論效率,並強化了安全,也更容易整合到使用者的工作流程中,它支援Hugging Face Transformers、JAX、PyTorch及TensorFlow等AI框架,並針對Nvidia的加速基礎設施進行優化,也能作為Nvidia NIM推論服務,之後也會針對Nvidia的自然語言處理解決方案NeMo展開最佳化。
為了打造更安全的AI應用,即日起開發者已可利用Python函式庫對模型及資料進行比較評估,於程式中產生視覺化的結果,此外,Google也正準備替Gemma模型開源文字浮水印技術SynthID。
自Google於今年初開源第一代Gemma後,該模型已被下載超過1,000萬次,其中一個Navarasa專案即利用Gemma來建立一個支援多元化印度語言的微調模型。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-09

2026-02-10


2026-02-10

2026-02-06