微軟
微軟的AI研究團隊近日發表了一份名為SpreadsheetLLM的研究報告,旨在協助大型語言模型(LLM)更容易理解試算表(Spreadsheet)中的資料,以便正確推論。
試算表由許多儲存格組成,這些儲存格存放著文字、數字、公式或函數,嵌入在許多的行與列當中,形成靈活且複雜的大規模二維結構,同時它還具備了諸如字體、顏色或邊框等各種格式選項,對大型語言模型造成了重大挑戰,於是研究人員開發出SpreadsheetLLM框架,以協助LLM理解並正確推論來自試算表的內容。
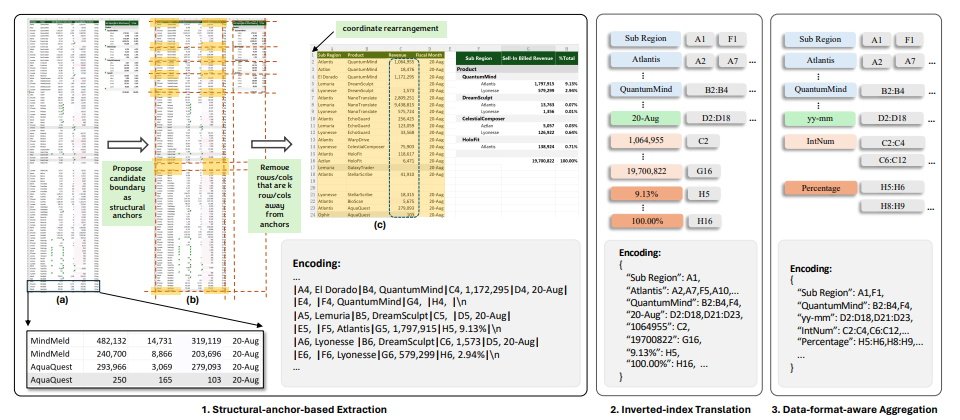
研究人員指出,他們一開始利用一個簡單的序列化方法,結合了儲存格位址、值與格式,但此一方法受到大型語言模型所支援Token數量的限制,在大多數的應用中無用武之地;於是他們進一步開發了可用來編碼及壓縮試算表的SheetCompressor,它包含3個模組,一個用來壓縮試算表結構,一個反向索引翻譯,以及一個可感知資料格式的聚合模組,結果在GPT4的脈絡學習設定中,後者的性能比前者高出了25.6%。
此外,當微調大型語言模型並輔以試算表壓縮比達25倍的SheetCompressor時,其用來測試模型準確度的F1分數達到78.9%,大幅超越了現有最佳模型的12.3%。
之後研究人員再提出了試算表鏈(Chain of Spreadsheet),用以理解試算表的下游任務,並於新的試算表QA任務中進行驗證,證實了SpreadsheetLLM在許多試算表任務中都非常有用。
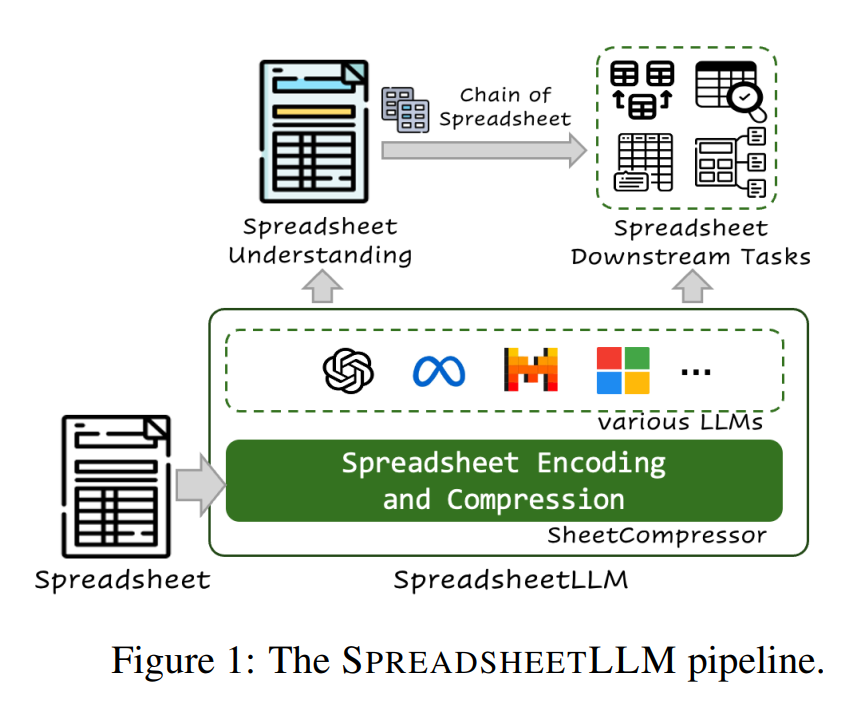
在該研究所描繪的SpreadsheetLLM流程中,是以SheetCompressor結合各種不同的大型語言模型來理解試算表,再針對試算表的各種下游任務進行推論。
研究人員指出,SpreadsheetLLM為處理及理解試算表的重大進步,它有效地解決了尺寸帶來的挑戰,以及試算表固有的多樣與複雜性,可大幅減少所需的Token及運算成本,而能在大型資料集上進行實際的應用,對各種LLM的微調更可進一步提高對試算表的理解能力。至於用來擴充SpreadsheetLLM框架的Chain of Spreadsheet則展現了未來的應用潛力,也將帶來更有效與更聰明的使用者互動性。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-10

2026-02-09

2026-02-10