圖片來源:
Hugging Face
繼4月份公布可在裝置上執行的小語言模型OpenELM後,蘋果本周又公布了14億及70億參數的DCLM模型,號稱效能不輸競爭模型如Llama 3、Gemma或Mistral,或是更節省訓練運算資源。
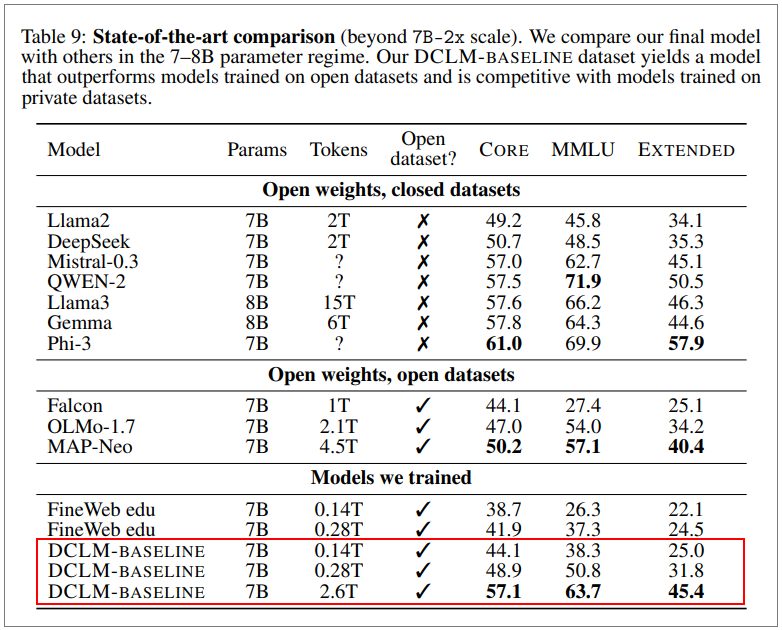
這二款模型是由蘋果DataComp for Language Models(DCLM)團隊開發,並在Hugging Face平臺上公布。Venturebeat報導,DataComp專案成員來自蘋果、華盛頓大學、以色列台拉維夫大學及豐田研究院。第一款為DCLM-7B,是69億參數的模型,以2.6兆字符(token)資料訓練而成。蘋果指出,和State of the Art(SoTA)模型如Mistral、Llama 3、Gemma、阿里巴巴Qwen-2、微軟Phi-3及開源模型MAP-Neo相比,DCLM-7B在多語理解測試MMLU中,最後的成果和Map-Neo相較效能相同,但運算資源耗損少40%。和私有模型相較,DCLM-7B準確性得分(64%)和Mistral-7B-v0.3(63%)及Google Gemma(64%)相比差不多,比起Llama 3-8B(66%)略低,但蘋果說,其模型耗能低了6.6倍。
第二款DCLM-1B模型參數量為14億。蘋果宣稱,在Alpaca bench測試中,效能優於Hugging Face上周公布的小模型SmolLM。
蘋果最後將DCLM模型框架、高品質訓練資料集DCLM-BASELINE以及預訓練方法,都開源公布在https://datacomp.ai/dclm專案網站。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-09

2026-02-09

2026-02-06
Advertisement