
Meta
繼於今年4月發表可用來分割圖像物件的Segment Anything Model(SAM)之後,Meta周一(7/29)釋出Segment Anything Model 2(SAM 2),並將分割物件的功能從圖像延伸到影片。
SAM 2可以分割圖像或影片中的任何物件,還能即時於影片中的所有畫面追蹤該物件,既有的其它模型無法實現此一功能,是因為它比分割圖像中的物件還要困難許多。在影片中,物件可以快速移動,外觀可能有所改變,也可能被場景中的其它物件擋住。
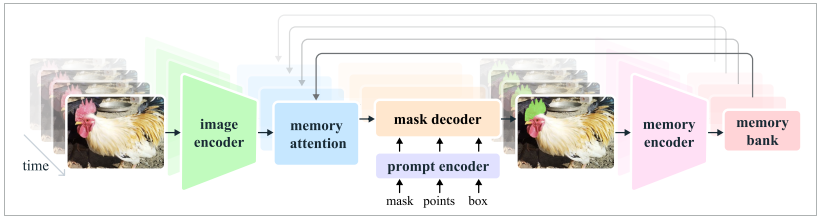
Meta說明,SAM可理解圖像中物件的一般概念,而圖像可被視為只有一個畫面的短影片,Meta即採用此一概念來開發一個統一的模型,得以同時支援圖像與影片的輸入,處理影片的唯一區別是,該模型必須依賴記憶體來回憶之前處理過的影片資訊,以於當前的時間準確分割物件。
圖片來源/Meta
要成功分割影片中的物件,需要了解實體於空間與時間中的位置,相較於圖像中的物件分割,影片中的物件移動、變形、遮擋、照明變化或其它因素,都可能在不同的畫面之間發生重大變化,再加上影片品質通常低於圖像,更增加了難度。於是Meta藉由建立新的影片物件分割資料集(SA-V Dataset)來訓練SAM 2。

圖片來源/Meta
SA-V Dataset包含了5.1萬個真實世界的影片,以及超過60萬個時空掩碼(Masklet),Masklet標註了物件於畫面中出現的時間點與位置。相較於坊間最大的影片分割資料集,SA-V Dataset的影片數量是它的4.5倍,標註數量則是53倍。
自釋出圖像物件分割模型SAM以來,除了Meta的內部應用外,SAM已被應用在海洋科學中以分割聲納圖像或分析珊瑚礁,亦已被應用在救災的衛星圖像分析,以及醫療領域上的細胞圖像分割,並協助檢測皮膚癌。Meta更預期可同時分割影像及影片物件的SAM 2可望被用在自動駕駛系統,追蹤瀕臨絕種的動物,或是應用在醫療領域的腹腔攝影鏡頭上,相信它有更廣泛的可能性。
SAM 2程式碼及權重採用Apache 2.0開源授權,SAM 2評估程式碼則採用BSD-3開源授權,而SA-V Dataset亦透過CC BY 4.0授權與外界共享。使用者可透過SAM 2的展示網站理解它的能力。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-09

2026-02-10


2026-02-10

2026-02-06