
Cloudflare
提供內容傳遞網路及安全服務的Cloudflare本周坦承,該公司在11月14日,因為內部系統一連串的臭蟲,在短短5分鐘的錯誤配置中,便遺失了55%的客戶日誌。
Cloudflare的網路是由分布在全球330個城市的系統組成,它們支援多項服務,且系統的每個部分都會產生事件日誌,並將它們傳送給客戶,供客戶執行合規性管理、系統觀察,或是會計。Cloudflare平均每天會處理50兆個客戶事件日誌,但僅有不到10%、約4.5兆個會傳送給客戶。
Cloudflare的日誌處理架構,包括負責從全球伺服器接受並批量轉發日誌的Logfwdr,接收批量日誌並進一步將它們分配至緩衝區的Logreceiver,管理超過100萬個日誌緩衝區的Buftee,以及將日誌推送到客戶指定地點的Logpush。
在11月14日那天,為了支援新的資料集以處理額外的日誌類型,Cloudflare更新了Logpush的配置,配置系統需要將此一配置傳送給Logfwdr,但配置系統傳送給Logfwdr的檔案卻是空白的,因而觸發了Logfwdr內部的「故障開放」(Fail Open)機制。
該機制是一種系統設計策略,在發生故障時,系統預設選擇開放狀態,亦即寧可多做也不要停止服務,在Cloudflare的日誌系統上發生時,它便選擇替所有的客戶發送日誌。
儘管Cloudflare很快就發現此一錯誤,並在5分鐘內恢復了該變更,但Logfwdr已根據Fail Open發送日誌予大量客戶,而Buftee原本有防護機制,卻因配置問題而未被正確啟用,導致Buftee所管理的日誌緩衝區數量,很快就從一百多萬個快速增加到4,000萬個。
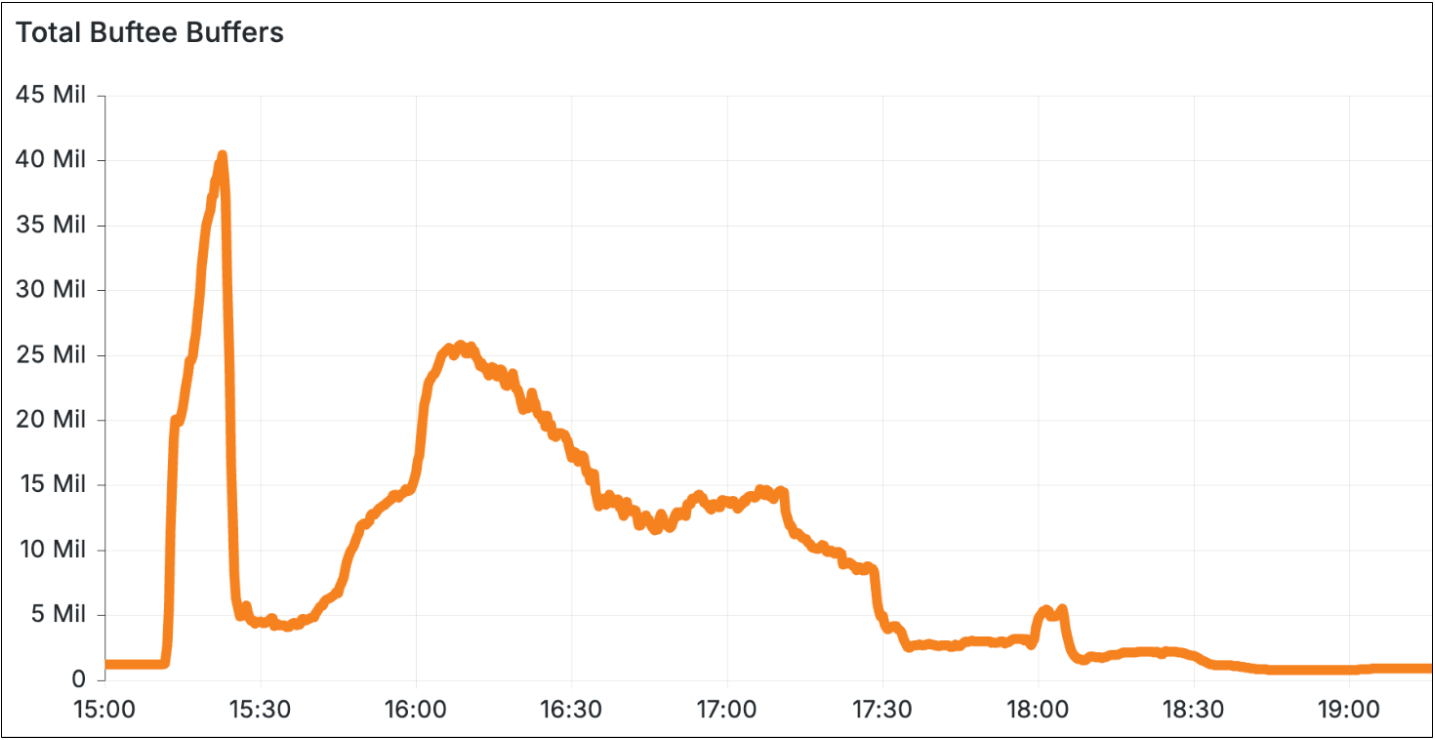
圖片來源/Cloudflare
只有短短5分鐘的錯誤配置便造成了巨大的過載,導致底層系統過載而無法正常運作,需要全面的重置與重新啟動。這起意外從配置系統出錯、Fail Open的設計、Buftee的保護機制未被啟動,一直到復原,總計持續了3.5個小時,造成Cloudflare原本應該發送給客戶的日誌中,有55%並未發送而且完全遺失。
Cloudflare表示,大規模系統中的故障是無可避免的,但子系統必須具備自我保護機制,以防止來自其它部分的故障引發連鎖反應,在此次的事故中,系統某部分的配置錯誤導致了另一部分的過載,而另一部分的系統亦存在著配置問題,如果正確的配置,即可避免日誌遺失。
熱門新聞

2026-02-02

2026-02-03

2026-02-04

2026-02-02

2026-02-04


2026-02-03

2026-02-05