
Meta AI研究院FAIR最近開源9項重要研究成果,包括虛擬人動作控制模型、影片浮水印生成模型、生成框架、LLM社交能力基準測試等。
重點新聞(1213~1219)
Meta 電腦視覺 LLM
從虛擬人到LLM社交智力測試,Meta開源9大研究成果
最近,Meta AI研究院FAIR開源今年度9大重點研究成果,從虛擬人型AI代理的動作控制、AI影片生成浮水印、多模態生成框架,再到LLM社交能力基準測試、大型概念模型(LCM)和另類Transformer視覺模型等,都包括在內。FAIR希望開源這些成果,來推動AI技術進步。開源重點如下:
- Meta Motivo虛擬人行為基礎模型,能控制虛擬人型代理的動作,來完成複雜任務。該模型以非監督增強式學習方法和未標記的大量資料訓練而成,能學習人類行為,但也保有零樣本推論能力。團隊希望該技術能加速元宇宙全身化代理的開發、提高遊戲NPC擬真度,或是加速動畫角色的普及。
- Meta Video Seal影片浮水印生成模型,可在影片中嵌入肉眼看不見的浮水印,就算影片經過模糊化、剪輯或壓縮等編輯,依然能辨識,能用來追溯影片來源。
- Flow Matching生成框架指南和程式碼,可生成多種模態資料,如圖像、影片、音訊、音樂和3D結構(如蛋白質)等。Meta已用這個框架開發內部多款生成應用,如Movie Gen、Meta Audiobox等,業界也用來打造不同模型,如Stable-Diffusion-3、Flux等,取代了傳統擴散模型。
- Meta Explore Theory-of-Mind對抗數據生成框架,能以心智理論(ToM)來強化機器智慧,更能理解和推測人類想法。這個框架可生成資料集,來改善LLM的人際互動表現,還能收集互動資料集,或是作為評估LLM社交智力(Social intelligence)的基準測試。
- Large Concept Model(LCM)大型語言概念模型,是一種新型的模型訓練方法,不像傳統語言模型專門預測下一個字符,而是預測下一個概念或高階想法,並透過多模態和多語言嵌入空間來表示。這個方法讓模型在生成任務中,媲美甚至超越目前最先進的LLM表現。
- Dynamic Byte Latent Transformer是一種Transformer模型,因為不需要任何分詞(Tokenize)預處理,克服了傳統文本分詞帶來的限制,提高模型在長序列訓練和推論的效率。
- Memory Layers at Scale擴展記憶層方法,能提高LLM對複雜概念和語言細節的理解。這個方法還能在不增加運算量的情況下,為模型增加額外的參數,進而提高記憶效率。
- Image Diversity Modeling負責任的圖像生成模型,Meta特別與外部專家合作,請他們用這款模型來進行負責任研究,在模型保持高品質產出的同時,也兼顧安全。
- CLIP 1.2視覺-語言編碼器,可更好地學習、捕捉圖像與語義間的細微關聯。Meta這次開源了CLIP 1.2的演算法、訓練方法和基礎模型。 (詳全文)

應用程式 ChatGPT Notion
ChatGPT整合30多種第三方桌面應用程式
OpenAI最近展開12天直播,在第11天,他們揭露了一項新進展,ChatGPT可以支援包含MacOS作業系統的30多個第三方桌面應用程式了,Windows部分則要明年才會正式支援。這代表,使用者可在ChatGPT中,下提示要求分析Notion或Apple Notes等程式的筆記內容,意味著ChatGPT從對話助理開始轉型為代理型工具了。
進一步來說,ChatGPT支援的熱門桌面應用程式有Apple Notes、Notion、Warp、Xcode等30多個。OpenAI團隊還在影片中示範,ChatGPT如何與Notion應用程式配合使用,比如取得文件選定的內容,下提示來要求產出其他相關內容。 這個功能還支援語音模式,ChatGPT可根據使用者語音命令,來與應用程式配合使用。不過,ChatGPT這項支援第三方桌面應用程式的新功能,目前只對ChatGPT Plus、Pro、Team、Enterprise和Edu訂閱者開放,目前還沒透露何時對免費用戶提供。(詳全文)
生成式AI Nvidia 超級電腦
Nvidia推出輕巧實惠的生成式AI超級電腦
最近Nvidia推出體積小巧的生成式AI超級電腦,名為Jetson Orin Nano Super開發者套件,價格從499美元降至249美元,使用者可透過軟體升級,來以更低價格享有更高效能,打造生成式AI邊緣裝置。
這個開發者套件約手掌大小,與前代產品相比,這款套件的生成式AI推論效能提高了1.7倍、運算效能提高70%,達到67 INT8 TOPS,記憶體頻寬還加大50%,達到每秒102 GB,因此足夠執行多種熱門的生成式AI模型,或是Transformer類的電腦視覺模型。
Nvidia表示,這款超級電腦可用來打造檢索增強生成(RAG)的LLM聊天機器人、視覺AI代理,也能部署AI機器人。對於已擁有Jetson Orin Nano開發者套件的使用者來說,也能升級這款Jetson Orin Nano Super軟體更新服務,來提高執行生成式AI的效能。(詳全文)

微軟 Phi-4 小型語言模型
微軟發布140億參數小語言模型Phi-4
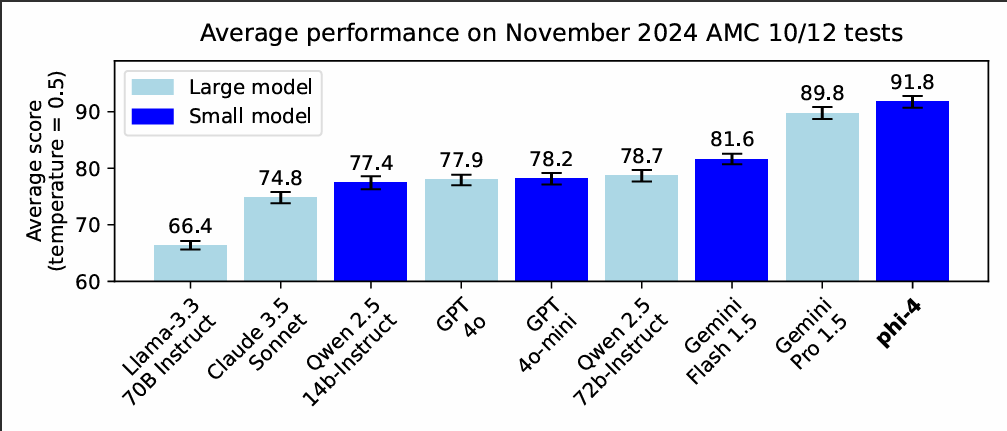
微軟日前發布輕量級語言模型Phi-4,具140億參數,但擁有良好的語言和數學推理能力,尤其在數學推理測試上,效能足以媲美700億參數的Llama等大模型。這意味著,輕量模型也能實現高效能。
微軟解釋,Phi-4之所以在基準測試中達成良好的表現,得益於資料集品質的提升。他們採用高品質合成資料和精心收集的真實資料,再加上創新的後訓練技術,大幅提升了模型推理精準度。Phi-4目前已在微軟Azure AI Foundry平臺上提供,之後將登陸Hugging Face。小型語言模型優勢在於資源效率和應用靈活性,對硬體需求較低,開發者能以更低成本部署,甚至適用於邊緣裝置或行動設備。此外,小型語言模型還很適合需要即時回應的場景。(詳全文)
Veo 2 影像生成 Google DeepMind
Google DeepMind推Veo 2影像生成模型
在12月初測試影像生成模型Veo後,Google DeepMind最近發布Veo 2版,要挑戰Meta和OpenAI Sora模型。Google指出,Veo 2理解力更強了,可以判斷實體世界物理作用、人類運動和表情的細微差異,來強化影片的細節和真實性。它也理解電影攝影的獨特語言,用戶可以指定鏡頭和想要的影像效果,例如要求從場景中間以低角度平移追蹤。
Veo 2最高可以生成一部4K(4096 x 2160)解析度畫質、長2分鐘的影片。這個能力是OpenAI Sora影片最高解析度的4倍,長度則超過6倍。Google還提供千名使用者評估,Veo 2和其他模型如Meta MovieGen、Sora Turbo相比,Veo 2在整體偏好及提示遵從度,都超過其他模型。Google表示,Veo 2雖然有幻覺問題,但頻率大為降低。Veo 2已在Vertex AI上線,Google也在新推的Google Labs影像生成服務VideoFX和實驗專案Whisk上,線逐步開放給創作者使用,但僅支援720p和8秒影片生成。(詳全文)
 Claude Clio 使用分析
Claude Clio 使用分析
Anthropic推出Claude使用分析系統Clio
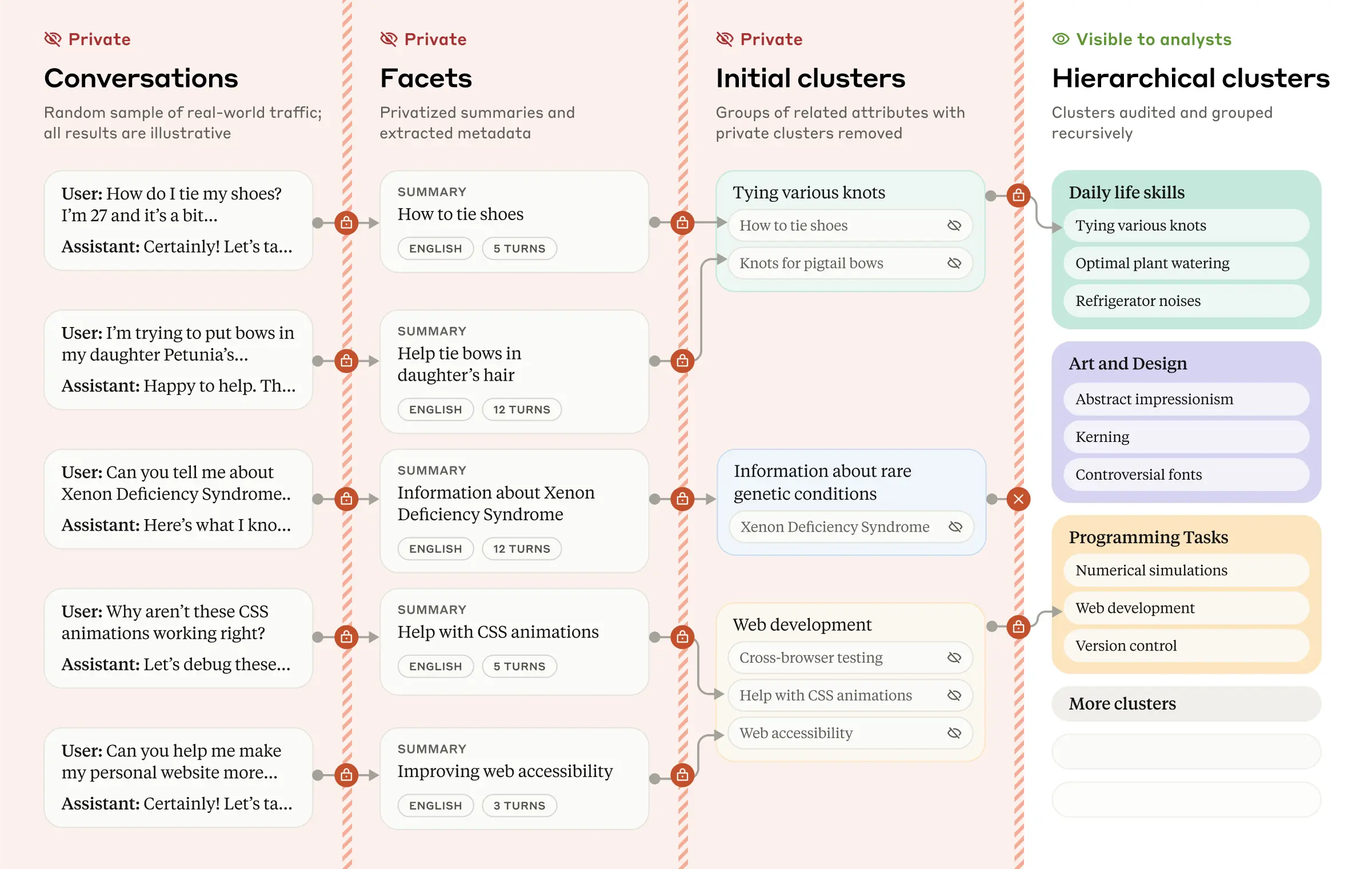
日前,Anthropic公開一項Claude使用分析系統,名為Clio,結合了隱私保護和安全分析功能,企業用戶可用來了解大型語言模型的實際應用情境。Anthropic表示,Clio設計的初衷是為了要解決兩大挑戰,首先是Claude等大型語言模型的應用場景廣泛且多元,要全面偵測和理解其使用方式非常困難,再來還得兼顧用戶資料隱私。
為兼顧分析和隱私,Anthropic開發這套自動化分析系統,能以匿名和資料聚合技術,將大量對話資料轉化成為抽象的主題叢集,供使用者得以分析結果,且不涉及個人資訊。這個分析流程可分為4階段,首先是擷取每段對話的主題和語言等多種屬性,進行語義分群,接著是針對每個叢集,生成簡潔的標題與摘要,最後是建置多層結構來分析。這些步驟由Claude系統自動執行,不需人工介入。
Anthropic已用Clio探索數百萬筆對話資料,發現Claude主要用於程式開發、教育學習和商業策略等領域,其中程式相關的使用情境占超過10%,像是程式碼除錯和版本控制工具的解釋等。除此之外,Clio也發現Claude常用於解夢、災害準備和桌上角色扮演遊戲策略建議等小眾用途。(詳全文)
ChatGPT 多模態 統一管理
OpenAI ChatGPT看得見了
在OpenAI展開的12天直播中,揭露兩款新功能Advanced Voice Mode with Vision和Projects,分別讓ChatGPT看得見,還能同時儲存專案檔案和對話了。進一步來說,Advanced Voice Mode是以GPT-4o等多模態模型為基礎,賦予ChatGPT聽力,能更流暢、更快速和用戶交談。在第6天的新功能發布中,OpenAI為這個功能加入了影片、螢幕共享和圖片上傳的支援能力,用戶可將手機對準電視播放的影片,問ChatGPT問題,或是和ChatGPT視訊對話,讓ChatGPT一步步教用戶完成手沖咖啡。該功能目前開放給ChatGPT Plus、Pro 方案用戶以手機App存取。
另一項新功能Projects則提供對話和檔案統一管理的新方法,來簡化需要大量交談的工作。Projects可將對話內容、檔案和自訂指令儲存於單一個地方,以便管理。它還支援OpenAI的現有功能,包括Canvas文件編輯、進階資料分析、DALL-E和搜尋等。該功能將陸續推向所有ChatGPT 付費用戶,包括Teams、Plus、Pro方案,但ChatGPT Enterprise及Edu方案用戶要等到明年初。(詳全文)
Gemini 2.0 Flash AI代理 瀏覽器
Google揭露最新模型Gemini 2.0,還推出4款AI代理
12月11日,Google發布專為代理型AI(Agentic AI)打造的多模態語言模型Gemini 2.0,並開放Gemini 2.0 Flash實驗版,還揭露了4款AI代理。Google執行長Sundar Pichai指出,最新的Gemini 2.0是Google歷來最強大的多模態模型,可處理音訊、圖片、影片和文字,還能與Google搜尋和地圖整合。Gemini 2.0一樣是系列模型,目前亮相的第一款模型為Gemini 2.0 Flash,在理解、數學、推理、事實貼近、圖像辨識、語音辨識及影像分析等多個基準測試中,大幅超越前一代Flash模型和1.5 Pro模型。Gemini 2.0 Flash目前還是實驗版,但開發者可透過Google AI Studio和Vertex AI的API,來打造AI應用程式。
與此同時,Google還發表了4款以Gemini 2.0 Flash為基礎的AI代理,這些代理可以使用工具、呼叫函數,還能即時回應API。第一個AI代理是Project Astra,是一款手機助理,可以即時辨識影片、文字、圖像和音訊,還與Google服務整合,能協助管理日曆、發送郵件和搜尋查詢。再來是Project Mariner,是專門用於瀏覽器的AI代理,能理解像素、文字、程式碼、圖片及表格等Web元素,還能透過一款Chrome外掛來執行任務,像是讀取網頁、比較產品價格、買票和安排時程表等。
第三個代理是Deep Research,是一款多模態研究助理,能分析資料集、文章摘要、編譯報告等。它是為學術和專業研究設計,Gemini Advanced訂閱者可以使用。第四個則是Jules,可整合到GitHub工作流程的AI代理,能處理程式開發問題、建立規畫並執行。(詳全文)
圖片來源/Meta、OpenAI、Nvidia、微軟、Google、Anthropic
AI近期新聞
1. Google開始測試有推理能力的Gemini 2.0 Flash模型
2. Salesforce升級Agentforce 2.0,新技能庫要助企業打造高效智慧代理
3. GitHub Copilot推出免費版本
4. Google發表3D場景生成模型Genie 2
資料來源:iThome整理,2024年12月
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-12

2026-02-10


2026-02-06