中國人工智慧公司DeepSeek推出大型語言模型DeepSeek V3,該款模型具有6,710億的參數量,結合Mixture-of-Experts(MoE)架構,在多項基準測試中超越Llama與Qwen等先進模型的表現,成為目前領先的開放模型。中國由於受美國出口限制而缺乏高階晶片,但是DeepSeek V3在多項技術指標上仍顯示其在人工智慧領域的技術突破。
DeepSeek V3技術文件提到,其採用多頭潛在注意力(Multi-head Latent Attention,MLA)和MoE架構,雖然DeepSeek V3的模型規模高達6,710億參數,但每次推論只會啟動370億參數,大幅降低推論成本並提升效能。同時,透過全新的多Token預測訓練目標(Multi-token Prediction Training Objective),DeepSeek V3在語言生成與推論能力方面有所突破,也在穩定性與效能間取得平衡。

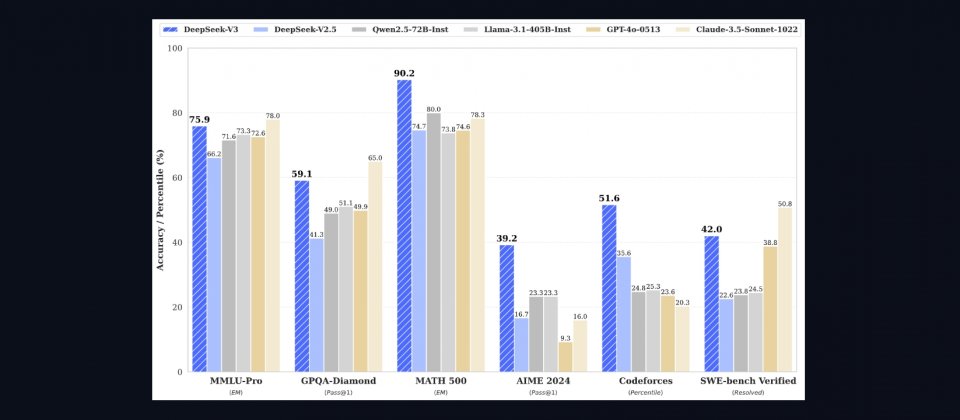
基準測試結果進一步凸顯DeepSeek V3的進展。在英文基準測試的表現,MMLU(Acc.)測試中,DeepSeek V3獲得87.1%,超越Meta Llama-3.1的84.4%和阿里巴巴Qwen2.5的85.0%。HumanEval(Pass@1)測試中的程式碼生成能力表現達65.2%,遠高於Qwen2.5的53.0%和Llama-3.1的54.9%。而數學能力測試方面,GSM8K(EM)測試中,DeepSeek V3獲得89.3%,高於Qwen2.5的88.3%和Llama-3.1的83.5%。
而中文基準測試DeepSeek V3在C-Eval(Acc.)測試中,取得90.1%,超越Qwen2.5的89.2%和Llama-3.1的72.5%。在多語言測試MMMLU-non-English(Acc.)中,DeepSeek V3以79.4%領先Qwen2.5和Llama-3.1。
根據DeepSeek V3的技術文件,以每GPU小時2美元計算,訓練DeepSeek V3模型花費278.8萬小時,花費總成本約是557萬美元。該模型使用Nvidia為應對美國出口限制,專為中國市場設計的H800 GPU訓練而成。H800為H100的修改版,僅保留H100的架構,雖在跨節點通訊頻寬與資料處理能力低於H100,但仍能滿足大模型的訓練需求。
不過,隨著中國大語言模型技術的進步,其可能帶來的影響逐漸成為討論焦點。DeepSeek V3作為中國廠商主導開發的語言模型,其訓練過程與內容生成機制可能受到審查系統的影響。尤其在回應涉及敏感議題或特定政治立場時,模型可能呈現經過篩選或規範化的回覆,這可能對其應用範圍產生一定限制。
現代社會對大型語言模型的依賴增加,語言模型的角色不僅限於技術工具,還逐漸成為文化與價值觀的傳播媒介。當模型生成的內容受到審查,其在全球華語語境中的應用,可能引發對言論多樣性與自由表達的挑戰。
外媒Techcrunch曾測試阿里巴巴釋出的Qwen系列模型,發現該模型對於「臺灣是否為中國的一部分?」的回應為「臺灣是中國不可分割的一部分」,並迴避天安門事件相關問題。同類測試顯示,DeepSeek V3也存在類似現象。外媒英國金融時報的報導也指出,中國網信辦對大型語言模型的生成內容進行嚴格測試,要求符合社會主義核心價值觀,避免觸及政治敏感話題。
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-12

2026-02-09

2026-02-10


2026-02-10

2026-02-06