
US Foods是一間有250,000間餐飲客戶的美國大型食品經銷商。旗下3,000名業務人員,不只要負責推銷公司產品,還得扮演餐飲及開店顧問。每當餐廳提出諮詢需求,業務人員就得花上3至4小時,彙整餐廳提供資料,再查找自家內部資料作為參考,才能開始製作顧問提案。平均,一名業務要負責50至70間餐廳。不只工作時間,連下班和假日,都被這些數據整理作業佔滿。
直到今年,US Foods ML工程部門打造了一套生成式AI知識管理助手,來支援業務人員的數據彙整作業,成功將原本3至4小時費時,大幅縮短到半小時以內,帶來超過6倍效率。這個KM助手前端是一個用React做的Web App,後端串接一系列數據處理模組及多模態LLM,來處理餐廳資料、比對US Foods內部資料,並提供業務人員製作顧問提案的建議。
US Foods ML工程部門副總David Falck揭露此KM助手的開發及維運細節。他強調,這個KM助手能達到如此成效,關鍵是不畏懼GAI準確度低,早早將雛形投入大規模真人試用。
不必過度在意準確度,實用性才是首要目標
如何降低生成式AI產生幻覺或回答不精確的機率,是企業應用此技術到實際業務流程中,一個常見品質控管環節。不過,David Falck表示:「我們打造KM助手學到的最大心得,就是不要太擔心準確度。應該聚焦實用性,盡早讓實際使用者告訴我們,工具好不好用。」
早在ML工程部門從GAI專案發想階段,就開始注重實用性。
生成式AI爆紅時,他們便決定大展身手,要從頭建置一套只有US Foods IT能打造的GAI應用,來解決專屬US Foods的業務痛點。他們開始四處訪談,尋找不同部門中,有哪些最麻煩的作業,適合用生成式AI解決。
David Falck表示,他們最後鎖定業務人員餐飲顧問來打造GAI應用,是因為業務整理資料的流程枯燥費時、高度人工化,且需要處理手寫紙條、食物圖片、菜單等紙本非結構化資料。這便是生成式AI技術適合應對,且能發揮實用價值的好案例。
到了第一次大型驗收,開發中的KM助手還遠遠不夠成熟,回答準確率只有5至6成,連介面都非常陽春。不過,當業務主管們看到這個工具雛形,還是愛不釋手。David Falck觀察,對業務們來說,就算GAI工具回答精確度不高,還是能協助他們整理數據,發揮節省時間的實用價值。
這次經驗,也使ML工程部門更放心的讓更多第一線使用者試用這套KM助手。之後開發期間,他們逐步讓更多市場及地區的業務人員試用。「準確率遲早會提升,使用者回饋要趁早蒐集。」David Falck表示,這個做法使他們能盡快測試和發揮實際工具成效,更能根據大量第一線使用者的誠實回饋,鎖定優化方向。正式上線時,KM助手已經可以將3至4小時的資料整理時間,減少到20至30分鐘。
持續優化和維運企業級應用的技術決策
David Falck說,ML工程團隊的技術決策,有助於快速分析試用結果和使用者回饋,並彈性調整系統。KM助手正式上線後,這些決策則使他們能在3,000名使用者同時使用的情況下,持續迭代、維運系統,並控管公有雲支出。
貫穿許多技術做法的兩大原則是模組化與文件化。David Falck進一步說明,模組化不只是將不同功能串起來,更要妥善把不同功能和環節切割成獨立模組。
開發過程中,US Foods團隊深刻體會了,妥善切割功能模組的重要性。KM助手的其中一段後端資訊流是,利用Textract OCR模組,來將餐廳提供資訊的圖文轉化成文字,再拋轉給LLM解析。David Falck回憶,某次他們嘗試用多模態LLM的圖文處理能力,來一口氣將餐廳提供資訊的圖文轉化成文字、比對內部數據、產出建議。結果,但KM助手最終生成結果不如預期時,他們無法判別,究竟是餐廳資訊轉化環節出錯,提示工程有誤,還是LLM解析資訊能力不足。最終,團隊回歸原本做法,將不同環節的功能獨立成不同模組,不僅方便排錯,也確保LLM更新時,不會一口氣影響到太多數據處理環節。
連輸入KM助手的提示詞,他們都採取模組化做法。David Falck解釋,採用模組化且簡短的提示詞,能提升模型推論結果的一致性與準確性,避免業務天南地北的詢問,既造成額外支出又降低工具使用效率。「當未來代理型AI工具更加成熟,管理提示詞的經驗和工具也派得上用場。」
David Falck口中的文件化做法,則包括製作技術文件、為重要系統活動留存易分析的紀錄,以及為使用者撰寫系統功能說明書。
模組化提示詞做法,也是ML工程團隊文件化做法的一環。他們會記錄和分析,KM工具使用接收不同提示詞模板後,各自生成內容精確度和使用者滿意度。這有助於他們持續優化提示詞設計。
另一個做法是設置專門儲存AI推論內容的資料庫。David Falck解釋,有許多業務詢問AI的問題,答案不會隨著時間而改變。類似問題只要有問過一次,之後都可從此資料庫找到答案,不需呼叫模型API。如此可以降低成本、加速系統回答效率。紀錄過往推論內容,更能讓ML團隊進一步比較不同AI模型版本間的問答內容,或研究AI回答不精確的原因。
他們還為KM助手的功能撰寫詳細功能說明書,讓使用者能根據需求快速找到最適合功能,進而鼓勵他們重複使用每一個功能組件。
除了上述KM助手的技術做法,David Falck強調,US Foods之所以能順利打造實用的生成式AI應用,平時基本功做足更是先決條件。這包括維持企業數據高可用性、隨時注重數據隱私及法遵措施、慣於控管雲端支出,以及重複使用模組化數據處理功能。「生成式AI只是你軟體開發百寶箱裡的另一個技術,平時該注重的最佳IT實踐方法,做GAI應用時也要做好。」他說。
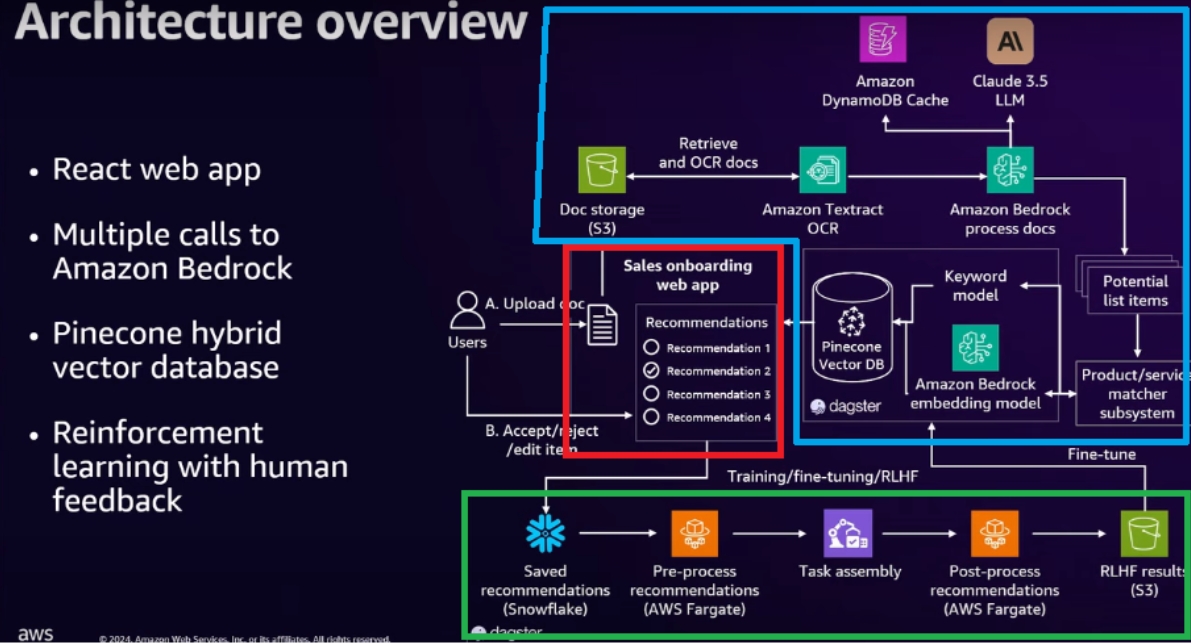
US Foods生成式AI業務助手的系統架構圖。紅色框是前端App,業務輸入客戶文件及需求(A動作)後,資料走到後端的推論流程(藍色框),經過OCR模組、LLM模組、企業數據匹配模組等模組,產出推薦內容。業務會選擇接受、不接受、或調整建議(B動作)。業務的選擇,則會進入後端的真人回饋流程(綠色框),自動化、系統化的蒐集真人回饋,用來微調AI模型,提升回答品質。
此工具後端有兩個重要資料庫,分別提升生成速度及生成準確度。推論結果資料庫會儲存過往AI推論結果,後續類似問答不須模型重新推論,而是從資料庫中提取,提升速度。混合向量資料庫則支援混合式搜尋(Hybrid Search),使系統能更好的匹配企業客戶提供的資料與所需企業內部數據,進一步提升生成精準度。
熱門新聞

2026-02-06
")
")
2026-02-09

2026-02-06
")
2026-02-09

2026-02-06

2026-02-06

2026-02-09