專門開發輕量級、專業化生成式人工智慧模型的公司Mistral AI,升級了其程式碼生成模型Codestral,新的Codestral 25.01版本在處理上下文長度,及程式碼完成效率方面表現更好,且該模型上下文長度可達到25.6萬Token,能有效滿足大型專案和複雜程式碼的完成需求。
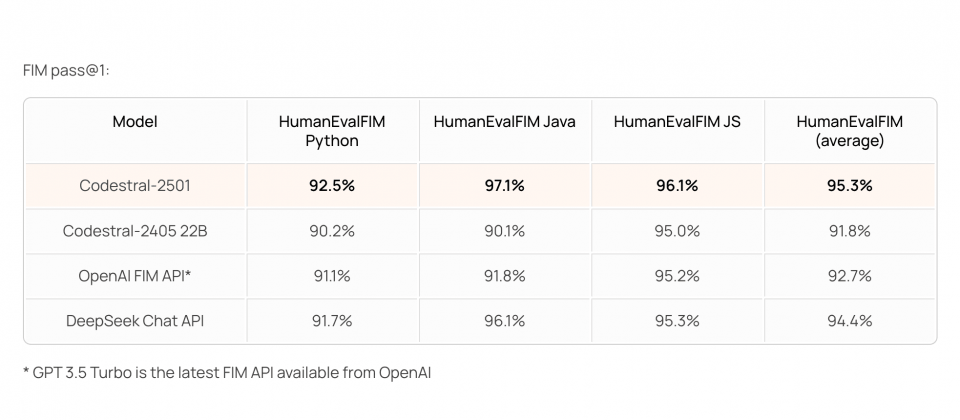
Mistral對少於1,000億參數的程式碼完成模型進行測試,Codestral 25.01在Fill-In-the-Middle(FIM)任務的表現,刷新了多項基準測試紀錄。在HumanEval、MBPP和CruxEval等評估中,該模型在準確率和生成速度方面表現突出,特別是在FIM的Pass@1測試中,平均通過率達95.3%,顯示其在單行程式碼插入和完成的能力。與上一代Codestral 24.05相比,新版的程式碼生成速度約是2倍,同時在多語言支援與程式碼生成的準確性有明顯進步。
與其他模型相比,Codestral 25.01在重要指標表現較佳,像是Meta的Codellama 70B instruct,雖然具通用性與多語言支持,但上下文長度僅有4,000個Token,難以滿足處理大型專案的需求。此外,Codellama在FIM測試中的準確率也低於Codestral。
其他競爭者DeepSeek Coder系列模型,包括DeepSeek Coder 33B instruct和DeepSeek Coder V2 lite,其中後者在上下文長度方面提升至12.8萬個Token,但整體性能落後於Codestral 25.01,像是HumanEval測試結果DeepSeek系列的表現皆不如Codestral。而OpenAI的GPT 3.5 Turbo FIM API雖在FIM測試水準與Codestral相近,但其上下文長度僅為3萬個Token,在大型專案的應用上將受限。
Codestral 25.01的升級重點還有對多語言環境的優化。Codestral 25.01支援超過80種程式語言,涵蓋Python、Java、JavaScript等主流語言,在SQL和Bash等應用案例也有精準的生成能力。測試顯示,該模型在HumanEval各語言測試中的平均準確率達71.4%,在Python等常用語言的表現更是遙遙領先。
在輕量級程式碼完成模型領域中,Codestral 25.01展現良好應用潛力。目前開發者已可透過支援的IDE或雲端平臺試用Codestral 25.01,Mistral也提供Codestral 25.01 API支援,供用戶整合至現有的開發環境中。
熱門新聞

2026-02-06

2026-02-06

2026-02-09

2026-02-09

2026-02-06


2026-02-06
")
2026-02-09