Anthropic公開名為憲法式分類器(Constitutional Classifiers)的新防護機制,專門用來抵禦通用型越獄攻擊(Universal Jailbreaks)。根據最新研究報告,這項技術透過憲法式原則的定義與分類器訓練,可偵測並攔截多數常見越獄手法,同時盡量降低拒絕合法查詢的比例。Anthropic現已開放臨時測試平臺,邀請攻擊測試人員進行實測,以進一步驗證系統的防護能力。
大型語言模型經過嚴格的安全訓練,理論上應該能夠阻擋危險內容的生成,例如拒絕回答涉及化學或生物武器製作的方法。不過,越獄攻擊利用不同的技術手法,例如極長的提示詞、特定的排版方式或變形文字,誘導模型繞過內建的安全機制。
Anthropic先前開發了一個原型版本的憲法式分類器,主要針對涉及化學、生物、放射性及核能相關的知識進行封鎖,並邀請外部專家參與越獄挑戰。最終在為期兩個月、合計超過三千小時的攻防實驗中,無人能以單一通用攻擊方法成功繞過所有限制。
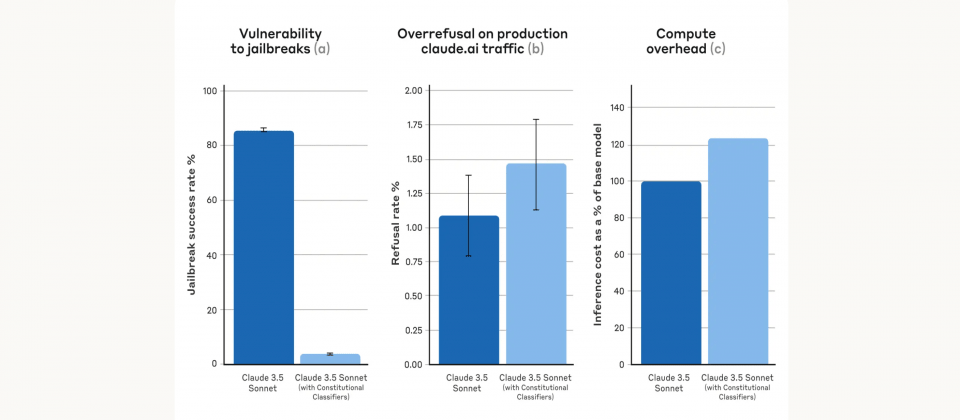
雖然原型系統防禦效果亮眼,但拒絕過多以及運算成本高昂等缺點,成為實際部署的阻礙。Anthropic現在發布的憲法式分類器,便是原型系統改良後的成果,並表示在合成測試(Synthetic Evaluations)時能將越獄成功率從未使用分類器的86%降至4.4%,拒絕率僅略增0.38%,運算成本也僅比基準模型多約23.7%。
憲法式分類器的概念與Anthropic先前提出的Constitutional AI相似,皆是透過一套預先定義的憲法式原則,來決定模型需回應或拒絕的內容,像是例如允許模型回答關於芥末醬的配方,但禁止回應有關芥子毒氣(Mustard Gas)的製作方式。
研究人員先利用大型語言模型如Claude,依照預先訂定的原則,合成大規模合法與不合法對話範例,並做多語言轉換及各種文字風格變形,以形成多元化的訓練集。隨後再以人工篩選的無害樣本進行補充,藉此減少對正常查詢的誤判。最終訓練完成的輸入與輸出分類器能自動偵測潛在的違規或危險內容,阻擋絕大多數嘗試繞過管制的手段。
雖然憲法式分類器在測試中展現優異的防禦能力,但Anthropic仍強調這並非萬無一失的解決方案。目前的防護機制能夠大幅提高攻擊門檻,使越獄變得更困難,但無法完全排除未來可能出現的新型態攻擊,因此建議搭配其他輔助防禦措施,並透過持續更新憲法規則來應對新興的安全挑戰。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-06

2026-02-09

2026-02-09