
Nvidia
Nvidia周二(3/17)開源了全新的推論軟體Dynamo,它可大幅提高推論性能,令Llama模型的推論性能及營收提高一倍,也能在執行DeepSeek-R1模型時,讓每個GPU產生的Token數量增加逾30倍。
Nvidia解釋,隨著AI推理(reasoning)成為主流,每個AI模型都會在每次提示時產生數以萬計、用來思考的Token,若能增加推論(inference)效能並持續降低推論成本,將可加速成長並提高服務供應商的收入機會。
隨著模型變得愈來愈大,並且愈來愈融入需要與多個模型互動的AI工作流程中,大規模部署這些模型涉及到將它們分布在多個節點上,也需要跨GPU進行仔細的協調。
Dynamo是Nvidia既有Triton Inference Server的繼任推論軟體,主要利用分解式服務(disaggregated serving)將大型語言模型的處理階段與生成階段,分別部署在不同的GPU上,以提升性能與效率。
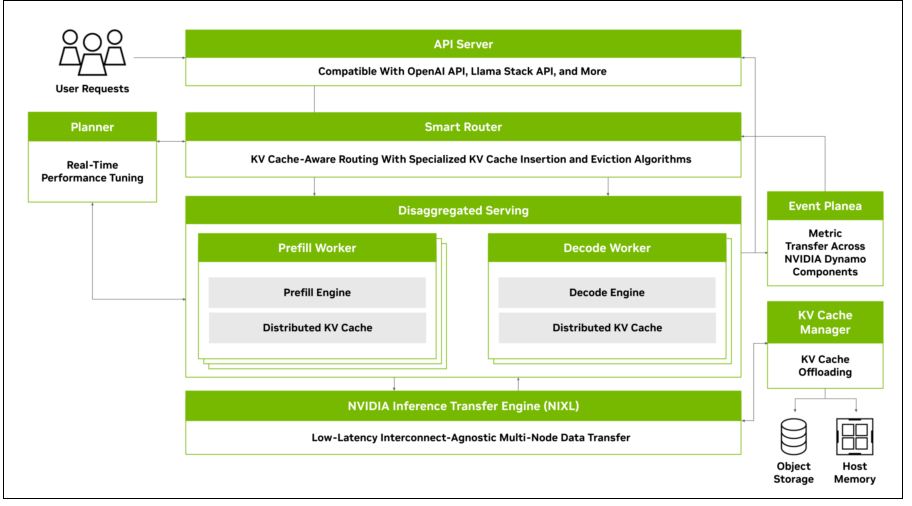
圖片來源/Nvidia
Dynamo的4個關鍵元件分別是GPU資源規畫器、智慧型路由器、低延遲通訊庫,以及KV快取管理器。其中,GPU資源規畫器是個規畫及調度引擎,可依據不斷變化的使用者需求,動態新增或刪除GPU,以避免GPU太多或不足;智慧型路由器則是一個可理解大型語言需求與特性的路由器,能夠在大規模部署的GPU群組中,將請求分配到最適合的GPU上進行處理,並減少對於重複請求的重新運算,讓所釋放的GPU資源得以處理新的請求,節省運算資源。
低延遲通訊庫是個針對推論最佳化的工具集,可支援不同GPU之間、以及不同類型的記憶體及儲存類型的資料傳輸,以提高推論效率。KV快取管理器是個快取卸載引擎,會根據需求將KV快取資料轉移到不同的記憶體儲存層次中,以釋放寶貴的GPU記憶體,同時保持用戶體驗。
根據Nvidia的測試,使用相同數量的GPU,若在Hopper平臺上執行各種Llama模型,Dynamo能使AI工廠的性能和營收翻倍;在 GB200 NVL72機架的大型叢集上執行DeepSeek-R1模型時,Dynamo也能將每個GPU產生的Token數量,提高超過30倍。
熱門新聞

2026-02-06

2026-02-06

2026-02-09

2026-02-09

2026-02-06


2026-02-06
")
2026-02-09