
鴻海日前在Nvidia GTC大會上揭露自家大型語言模型FoxBrain技術亮點,包括用LLM來進行原始資料的過濾,從語義層面著手挑出高品質資料,並按領域分類。
鴻海
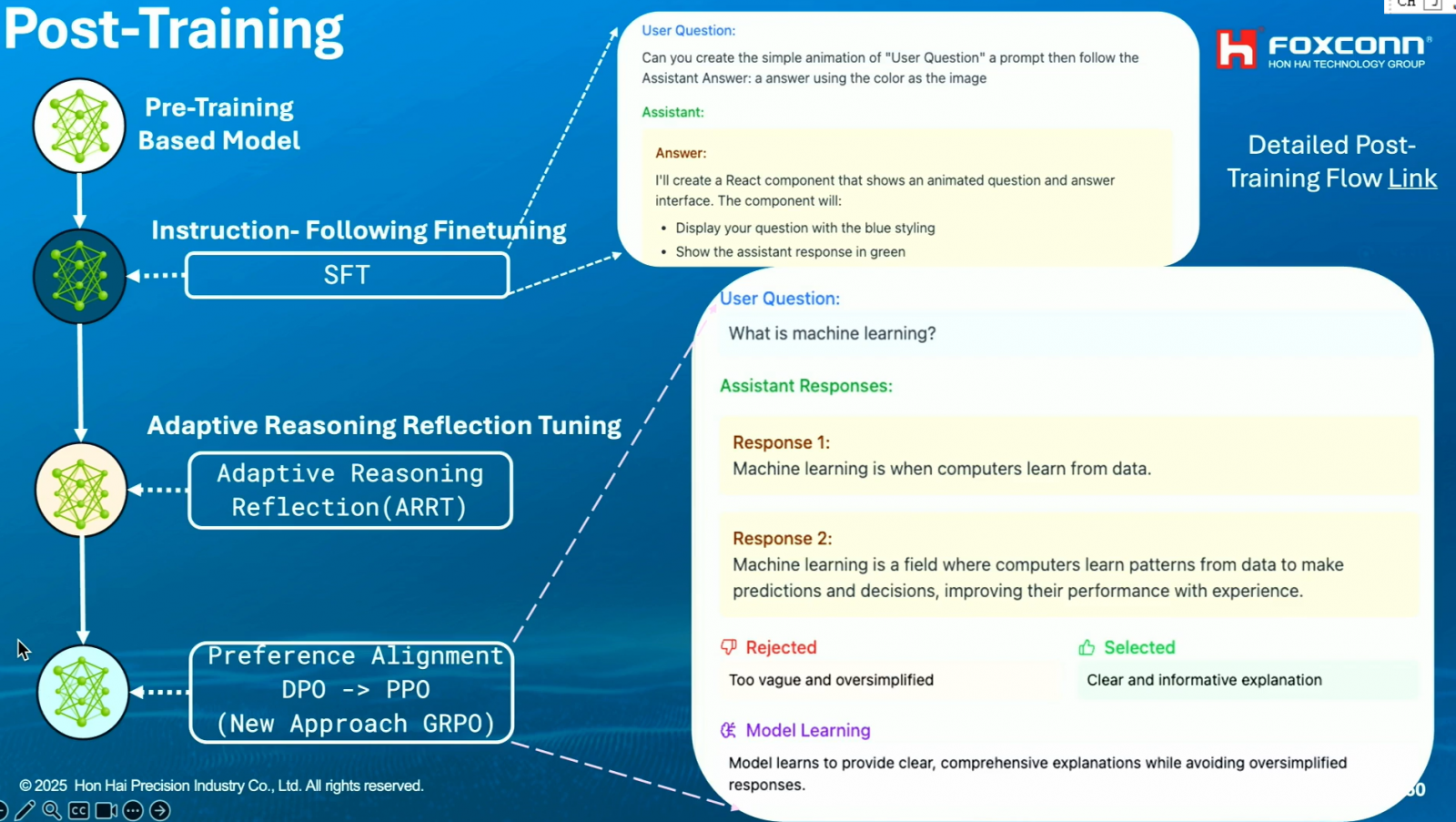
今年3月,鴻海研究院揭露了自家大型語言模型FoxBrain,後來在Nvidia GTC大會中進一步說明技術亮點,包括在預訓練階段用LLM來過濾原始資料並分類、結合LLM和COSTAR框架來產出品質更好的訓練資料,以及在後訓練階段用LLM生成更多訓練資料。甚至,他們也用LLM生成正確的推理過程,來強化FoxBrain推理能力,同時也用AI回饋強化學習(RLAIF)方法,來以AI為裁判,判斷FoxBrain產出的答案品質,用比人工更快的方式教導模型對齊人類價值觀。
亮點1:用LLM過濾原始資料
這個FoxBrain是以Llama 3.1 70B模型為基礎,以120張H100 GPU、花4周訓練而成,不只繁中能力超越Llama-3-Taiwan-70B,還具備良好的數學和邏輯推理能力,可執行數據分析、決策輔助、文書協作和程式碼生成等任務。
FoxBrain的技術亮點之一,是用LLM來過濾原始資料和分類。鴻海研究院技術負責人Van Nhiem Tran在Nvidia GTC大會中指出,FoxBrain模型訓練可分為連續預訓練(Continual pretraining)和後訓練(Post-training)階段,在預訓練階段,模型需要龐大訓練資料,因此團隊從開源資料集、外部資料(如arXiv、PubMed、新聞媒體等)和內部資料來收集訓練資料,同時根據期望模型具備的領域知識,來決定資料範圍,比如中英文數學和程式能力、臺灣和世界金融知識、鴻海知識、高階推理能力等。
收集這些資料後,很重要的一步是資料過濾,篩選出可用的訓練資料並分類。在這個階段,鴻海將收集到的141.13B Token原始資料(即1,413億個Token),先經過一系列正規化初始處理,再透過LLM進行品質過濾、篩掉一部分原始資料,再由另一個LLM進行領域分類,篩除7.33%的重複性資料,最後產出不同子集的訓練資料集,共97.71B Token。(如下圖)
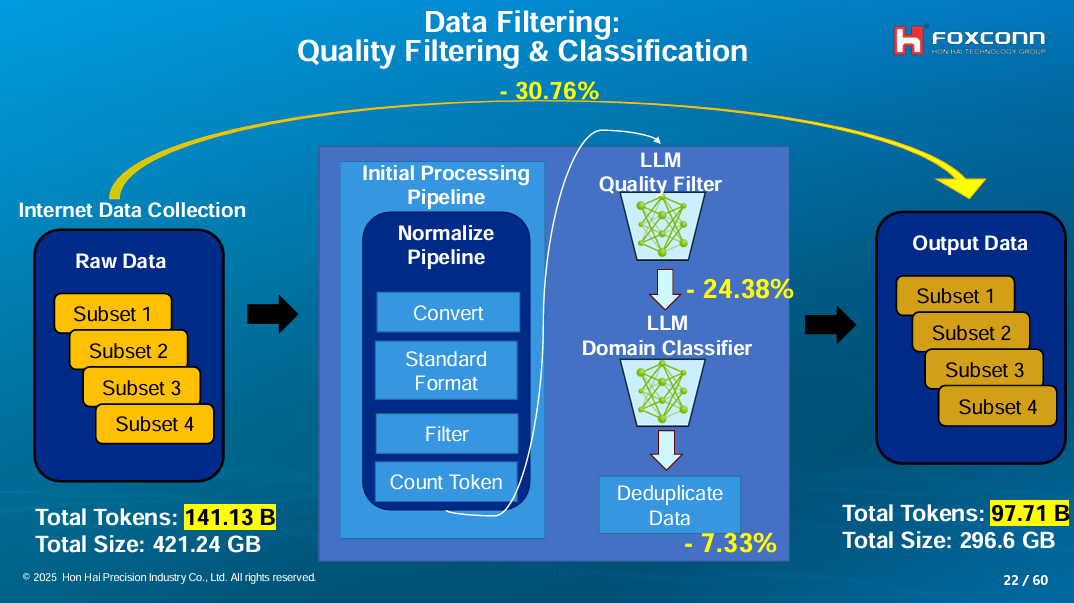
但如何用LLM過濾資料?Van Nhiem Tran解釋,他們設計了資料品質評分標準與一套評分用的提示指令,當LLM接收一筆資料後,會根據這套提示對原始資料評分。一旦超過規定分數,這筆資料就會被保留,再由另一個LLM歸類這筆資料,比如科學、財經等。有別於常見的重複性過濾,這個方法更能理解資料的語義表現,更能篩選出高品質資料。(如下圖)
.png)

亮點2:用LLM強化訓練資料品質
另一個技術亮點是用LLM來進行資料增強。這一步是在資料過濾和分類後,透過LLM來改寫這些資料,讓資料變得更有結構、文意更清楚易懂,且包含更多觀點。
要改寫資料,還需要一套統一的標準。於是,團隊先用COSTAR框架來設計提示,讓LLM根據提示要求,改寫資料(補充說明:COSTAR是常見的提示詞寫作框架,包含背景資訊Context、具體目標Objective、寫作風格Style、語氣Tone、受眾Audience和回覆格式Response,但鴻海團隊將其用來設計改寫提示)。比如,產生一份關於電腦和電子產品的網頁內容(對應C)、給高中生閱讀(對應O)且簡單易懂的版本(對應S)。(如下圖)

有了提示標準,團隊再來要找出各類別最適合改寫的LLM,而非用一套LLM改寫所有類別的資料。因此,他們根據資料過濾和分類後產生的類別,分別找出各類別代表性資料,再用幾個小型LLM來改寫這些資料。接著,他們用一套LLM作為評審,來評估這些改寫後的資料分數,進而找出哪個LLM最適合改寫哪個類別。(如下圖)
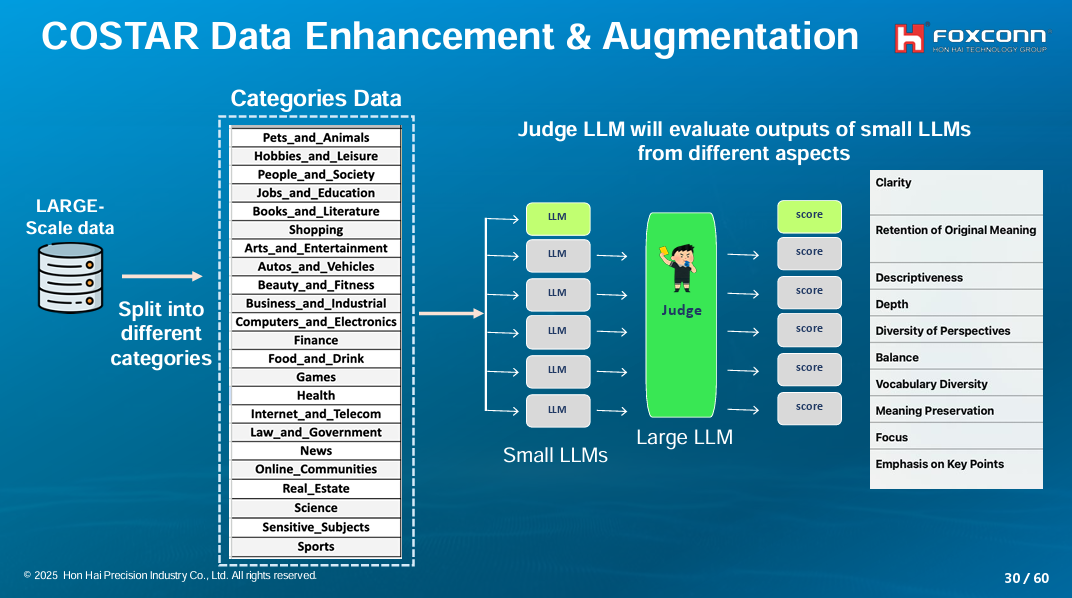
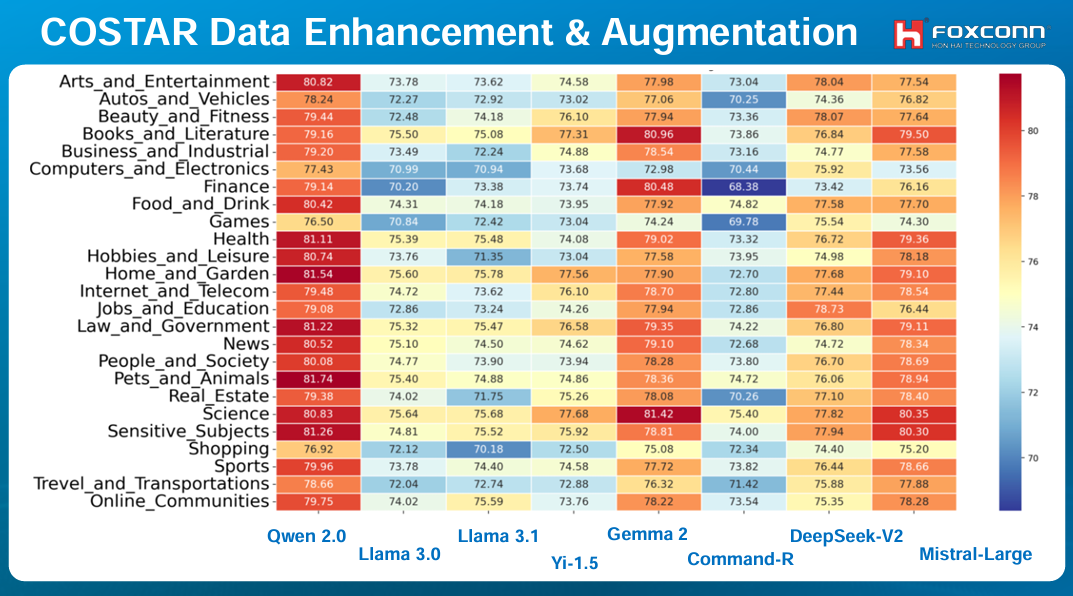
他們評估小型LLM表現的指標有幾個,比如文意清晰度、原意保留度、深度、描述性、觀點多元性等等。他們評估的模型有Qwen 2.0、Llama 3.0與3.1、Gemma 2和DeepSeek-V2等,也成功找出各類別最適合用來改寫/增強的模型,比如Gemma 2最適合用來強化科學類資料。(如下圖)
有了這些資訊,他們就建置一套工作流程,來根據篩選後的資料類別,以最擅長該類別的LLM來改寫,進而提高訓練資料品質。
亮點3:用LLM生成更多訓練資料
上述的資料過濾分類和資料增強,都是為預訓練資料的準備。預訓練之後是後訓練階段,有別於預訓練需要大量資料,後訓練聚焦模型特定領域能力,透過相對少量的資料來微調。
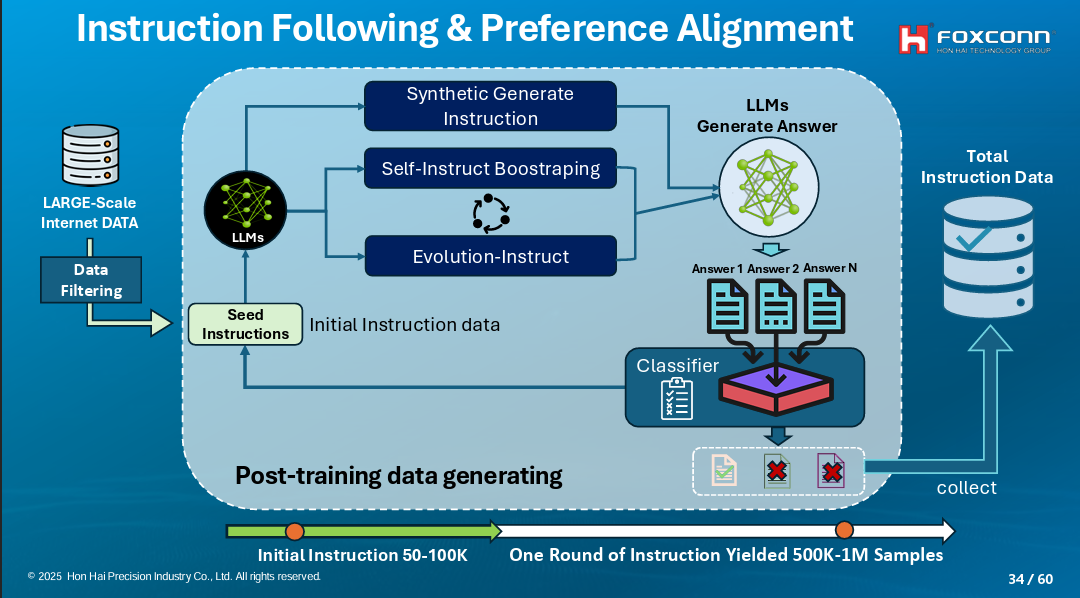
在這個階段,團隊也用不少AI輔助方法,其一是用LLM生成資料。他們先用模型生成問題,再用其他LLM來回答問題,產出各自的答案。這時,還會有套LLM根據規則來評分這些答案並分類,最後,這些問題-答案組就會納入後訓練資料集。(如下圖)
亮點4:用AI輔助模型訓練
同樣是在後訓練階段,團隊還有些特別的技術,來微調模型。
其中一種方法是Adaptive Reasoning Reflection(ARRT),來讓模型學習自主推理。鴻海研究所AI所長栗永徽說明,這個方法需要團隊準備許多問題及相對應的答案,而且,這些答案不只有最後的解答,還有中間的推理過程。為節省推理過程資料收集的時間,鴻海團隊用AI大模型,來針對各種問題,產出正確的推理過程。(如下圖)

同時,為確保模型不會一直無限制推理、消耗太多Token,鴻海團隊還設計一種方法,來讓模型學習,如何根據題目難易度來自動決定推理所需的Token量,以此作為限制條件,也就是Adaptive的意思。
栗永徽點出,經ARRT訓練的FoxBrain模型變得聰明許多,與DeepSeek相比,有些簡單問題, DeepSeek可能會一直思考才給答案,但FoxBrain對難的問題會多思考,對簡單的問題則思考快一些,在適當的時間內產出正確答案。
除了ARRT,團隊還用了AI回饋的強化學習方法(RLAIF)來進行後訓練,也就是以AI作為裁判,來在模型產出回答後,判斷回答好不好,進而教導模型對齊人類偏好的答案,大幅提高效率。(如下圖)
最後,為了讓FoxBrain更貼近實用情境、能在運算資源有限的裝置上執行,鴻海團隊還使用壓縮技術,比如剪枝、參數或權重稀疏(Sparsity)、量化等方法,來減少模型所需的記憶體和運算資源,兼顧速度和模型表現。
以上圖片來源/鴻海研究院
熱門新聞

2026-02-11

2026-02-09
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10