Meta
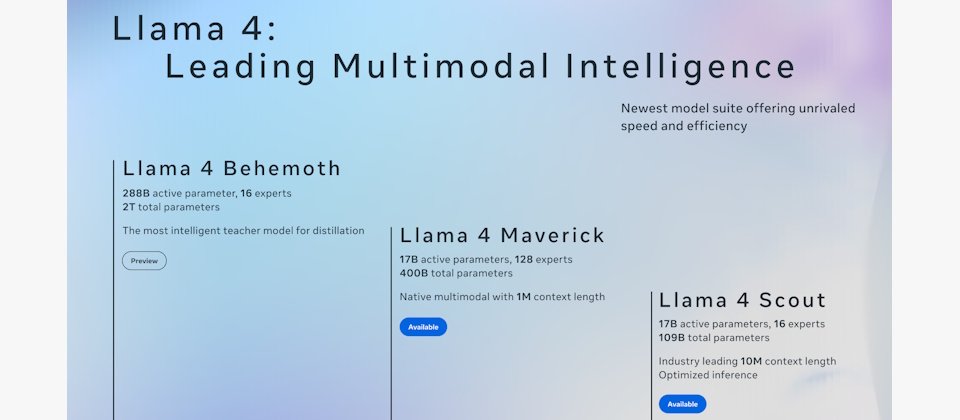
回應新崛起的DeepSeek,Meta上周末公布第一個混合專家(mixture of experts,MoE)模型家族Llama 4,並同時開源4000億參數的Maverick及1090億參數的Scout,此外預覽高達2兆參數量的Behemoth。
Llama 4是Meta第一個以混合專家(mixture of experts,MoE)架構訓練的模型家族。Llama 4訓練資料涵蓋包含大量文字、圖像與影片,涵括200種語言,總字詞(token)數為30兆,是Llama 3的兩倍以上。
今天開源的二個Llama 4模型,Maverick和Scout都有170億活躍參數,其中Maverick的MoE層使用128個專家及一個共享專家,總參數4000億,1M context windows。Scout則有16個專家,總模型參數1090億,10M context windows。Scout適合單一顆H100 GPU平臺。Maverick可快速部署在一臺H100 DGX主機上,或採分散式推論架構提升效率。
二個模型現在已在Llama.com及Hugging Face開放下載。Meta未來幾天內會提供給合作夥伴。
基於混合專家架構,Llama 4單一字詞僅啟動一小部份參數,因此在訓練和推論更省運算效能,在固定運算資源下能提供比密集模型更好的品質。同時Meta使用了新技術訓練。像是運用早期融合(early fusion)手法,可在整合模型骨幹上整合大量無標籤的文字和視覺字詞。Meta也改良視覺編碼器,讓視覺編碼器更適應LLM。Meta並開發了一個新技術MetaP,使參數可以在不同的batch size、模型規模、訓練長度中保持良好遷移性。
藉由MoE架構平行化最佳化配合動態分配GPU資源,提高訓練彈性,打破傳統分散式架構需要全部模型同時載入的限制,如此一來,相較於前一代架構,訓練效率提升約10倍。
後訓練部份包含三階段方法,包括輕量監督微調(lightweight supervised fine-tuning,SFT)、線上強化學習(online reinforcement learning,Online RL)及輕量偏好最佳化(lightweight direct preference optimization,DPO),以提升模型難度的適應能力,同時確保對話語言的品質和智慧平衡。
談及結果,4000億參數的Llama 4 Maverick在跨語言、影像與程式碼能力表現優異,在多數任務上(尤其是影像、推理、多語言、長上下文)優於GPT-4o、Gemini 2.0。而在程式與邏輯推理能力上,與DeepSeek V3.1(更大模型)互有高下。而1090億參數的Scout則將支援的context length由Llama 3的128K擴大到10M字詞,其標竿測試結果也超越Gemma 3、Gemini 2.0 Flash-Lite和Mistral 3.1。
此外,Meta也公布正在訓練中的教師模型Llama 4 Behemoth。整個Llama 4是以FP8精度進行高效率預訓練,而Llama 4 Behemoth則是利用Llama 4 Behemoth FP8精度及3.2萬GPUs上預訓練,達到390 TFLOPs/GPU,它是今天公布最大的MoE架構多模態模型,每字詞使用2880億活躍參數,具16專家模組(Experts),總參數達2兆,是Meta最強、最聰明的模型之一,Llama 4 Maverick正是以Behemoth為教師模型協同蒸餾而成。
Behemoth在理工、科學標竿測試如MATH-500和GPQA Diamond分數,超越GPT-4.5、Claude Sonnet 3.7及Gemini 2.0 Pro。
Llama 4 Maverick及Scout,除了開放給開發人員,消費者現在也可以透過應用程式WhatsApp、Messenger、Instagram Direct或Meta AI網站感受Llama 4。
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09

2026-02-10


2026-02-10

2026-02-10