過往以代理網路與資安產品為主要業務的安創資訊,2017年底將公司英文名稱從先前的VSSecurity,改為Auriga Security,而他們目前銷售的IT產品,主要有SentinelOne的EDR系統、Qlik視覺化資料分析平臺,最近他們也推出了自行開發的大數據收集系統ParseMe,並以此套產品,成為新創加速器SparkLabs Taipei第二屆的重點培訓對象。
ParseMe所要針對的應用需求,主要是資料收集過程當中的第一個階段,於是,安創資訊以「The First Mile Collector」為這套產品定位下了註解。不過,市面上的各種大數據系統、事件資訊管理系統,以及資料倉儲、視覺化分析工具,通常都涵蓋事件記錄的收集與剖析功能,為何還要搭配ParseMe?
首先是,對於資料的剖析與涵蓋範圍,ParseMe沒有特別的限制,具備更高的使用彈性,可涵蓋到各種設備,包含無線網路基地臺的事件記錄,當中也不需強制使用固定的CEF格式來進行轉換或切割。
相較之下,一般的安全資訊事件管理系統(SIEM)剖析資料時,所要整合的設備資料來源,可能需通過SIEM廠商的認證,有時在系統更新之後,會出現無法剖析的狀況。
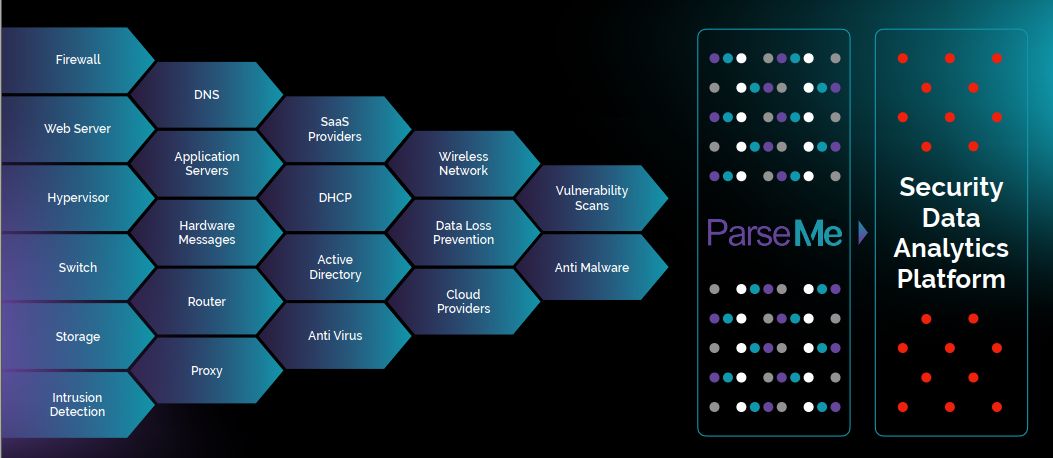
此外,ParseMe能夠協助企業看到更全面的狀況。在企業目前建置的安全維運中心(SOC)的環境,有時會受限於系統的資料處理能力不足與產品使用授權,僅能提供警示或統計報表,或是接收防火牆或IPS的事件記錄,而無法用來找出問題。
就性能而言,安創資訊強調,ParseMe在資料吞吐效能上,有更好的表現,就每秒處理的事件數量(EPS)而言,可達到6萬筆,而上述系統可能只有8千到1.2萬,相差了4倍之多。

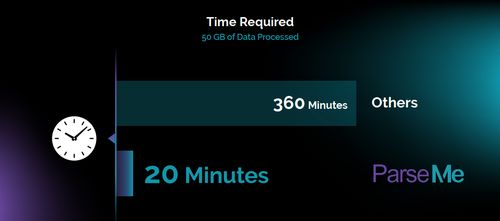
在資料的保存上,ParseMe也導入了加密壓縮的機制,若以每天需儲存3TB資料的狀況來看,經歷3個月的收集之後,一般系統可能就會累積到270 TB,而ParseMe此時僅增長到20 TB。而在資料處理耗費的時間上,若同樣面對50 GB的事件記錄,Parse只需20分鐘就能完成處理,但其他系統可能就要等上6小時之久。

而在資料整合的工作上,ParseMe主要負責的任務,是將各式各樣來源的資料接收起來,然後,經由正規化(Normalization)、過濾(Filtering)、輸出(Output)等的作業流程,再將這些經過前置處理的資料,交由大數據儲存與搜尋系統/資料湖(Data Lake)、安全資訊事件管理系統(SIEM)、商業智慧系統(BI)。
以資料湖而言,ParseMe目前可連接Cloudera、Splunk、elasticsearch;在安全資訊事件管理系統的部份,它能支援QRadar、Alien Vault、ArcSight、Splunk;在商業智慧系統,它可支援Qlik、Tableau、微軟Power BI。
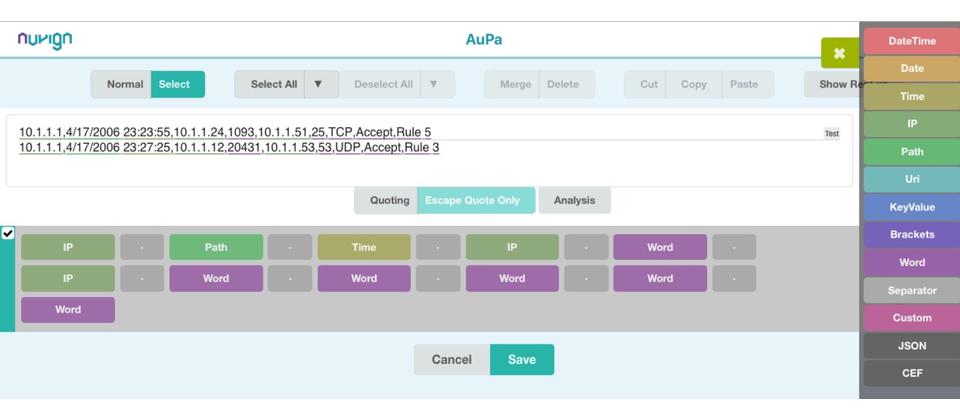
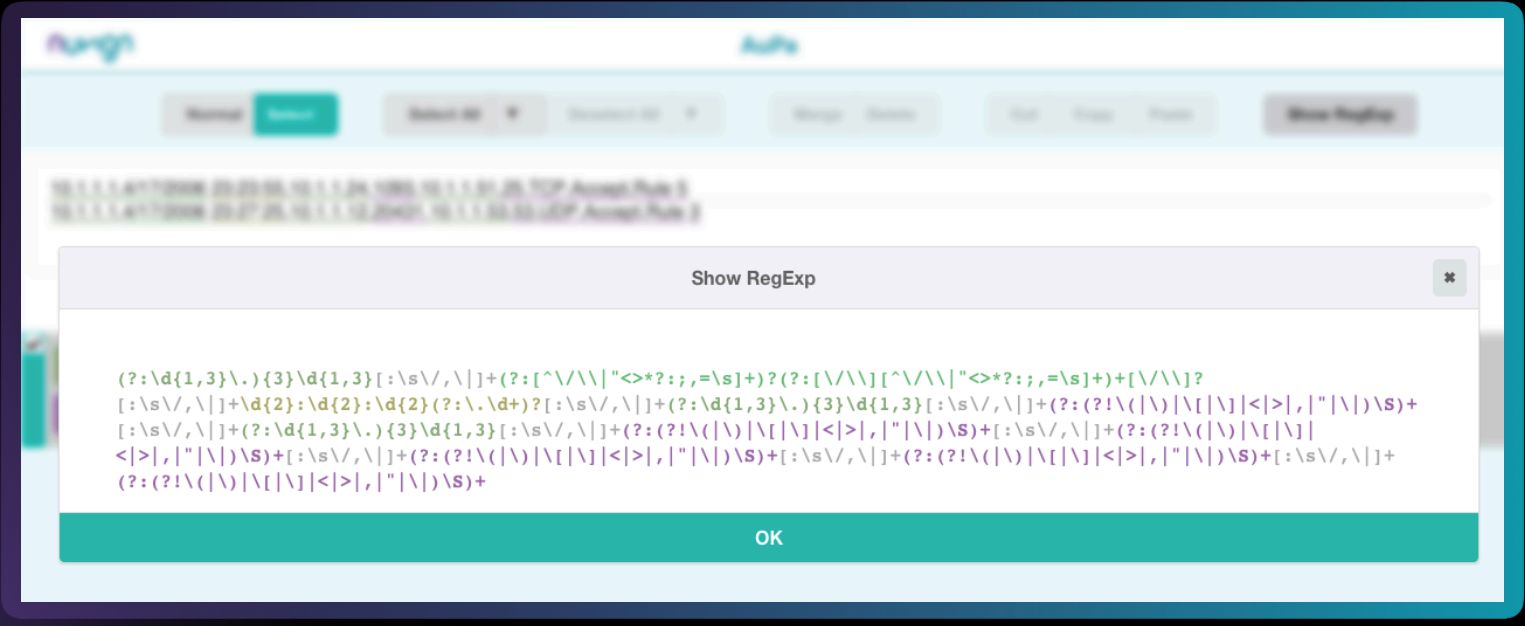
關於正規表示式的運用,是ParseMe能否大幅提升資料剖析處理能力的重大關鍵
安創資訊發展ParseMe之前,最早是從代理大數據系統軟體Cloudera開始,主推Hadoop大數據,後來開始代理商業智慧系統Qlik,引進資料視覺化技術,不過,Qlik當時無法處理串流資料(Stream Data),因為某次專案的需求,他們特別開發出名為JAICAS的引擎來輔助處理。在這之後,他們決定將這項技術搭配其他模組,於是造就了現在的ParseMe。
經歷了上述的過程,安創資訊發現資料剖析與處理的關鍵,其實是正規表示式(Regular Expression,RegEx),於是決定朝這個方向去發展,而現在的ParseMe,採用類似Hadoop的資料架構,本身是基於人工智慧的模型,添加使用者操作介面,能夠做好收資料、存資料、吐資料的工作。
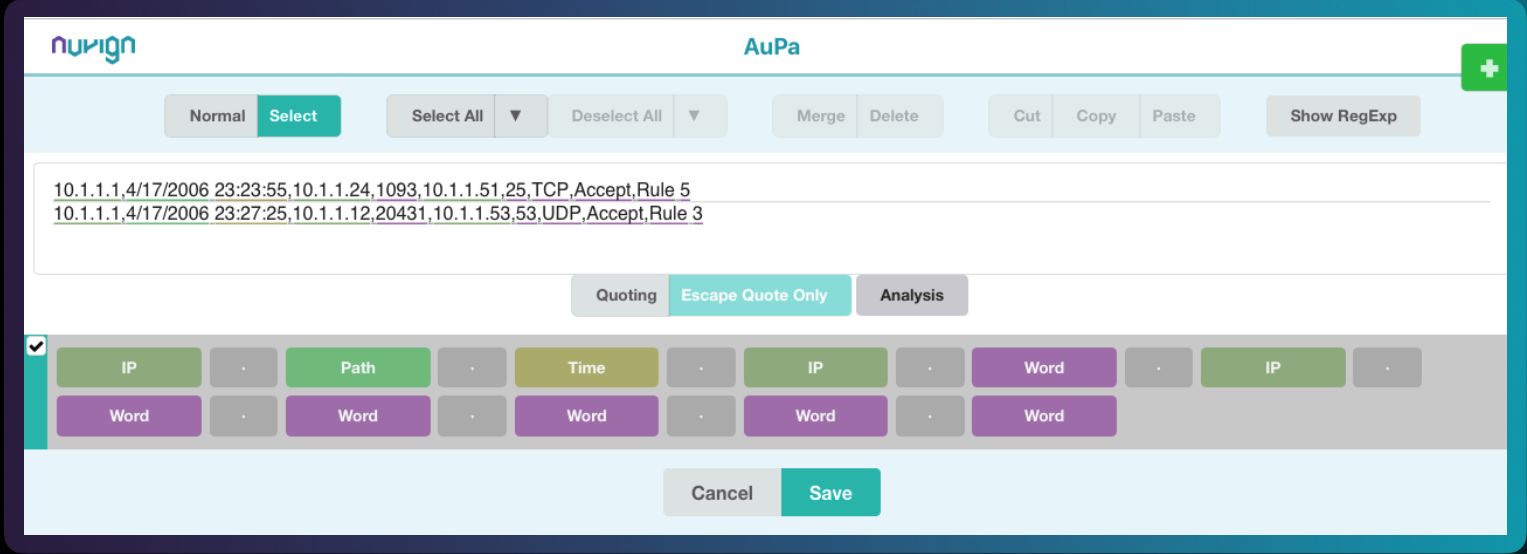
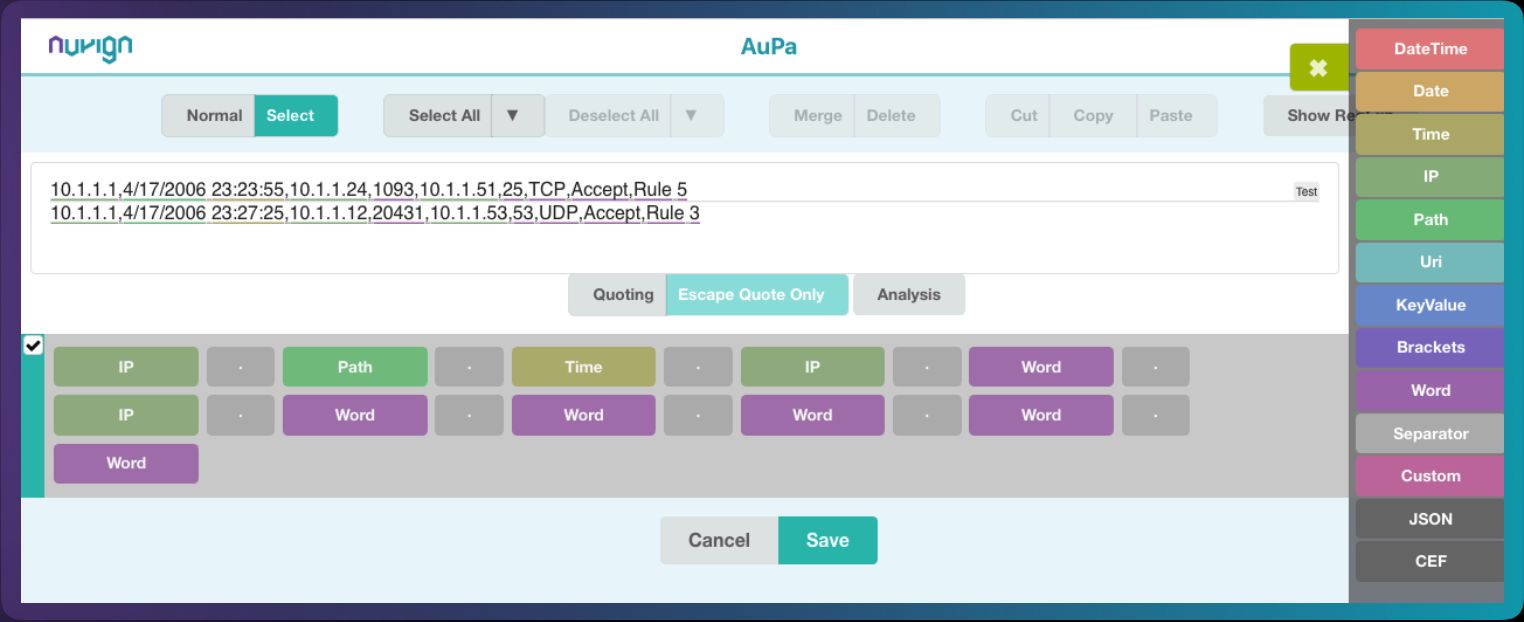
關於資料剖析的方式,ParseMe是透過機器學習的技術去找出通用的部分(辨識出共通資料),然後再標記出標籤。他們的系統還可以同時處理鍵值配對(Key Value Pairing)──正規表示式無法處理這部份作業。此外,用戶不需要預先制訂資料剖析規則,即可讓ParseMe進行處理,若要自定規則,可能只需5分鐘就能完成,不需耗費很多時間──但現行的系統可能需要花上兩週才能寫好一支Parser。
在產品定位上,安創資訊認為ParseMe是一種大數據收集器,目前可處理文字型的資料(text-based data),未來希望可以涵蓋到雙位元資料(binary data)。
為何正規表示式是事件處理的關鍵?安創資訊提出了下列說明。一般設備產生的資料,稱為原始事件記錄(Raw Log),需要經過一定的處理程序,後續才能分析使用。常用的方式就是使用正規表示式(進行正規化處理)後,再分析資料。
對於市面上常見的資安資訊與事件管理系統(SIEM)而言,它們通常會透過本身提供的代理程式預先設定,來處理原始資料,此時,會用到廠商預先寫好的正規表示式來處理。如此一來,會有幾個問題:首先,如果SIEM面對的是剛推出的網路或資安設備,或是用戶自行開發的應用程式,廠商若無相關支援,SIEM就無法處理;第二種情況是廠商設定有誤,就會有資料剖析失敗的結果;最後,廠商如果提供工具,用戶端可能就要人為介入,須自行撰寫正規表示式來處理。
而許多應用系統、設備與SIEM所支援的通用事件格式(CEF),其實也跟正規表示式有關,因為系統是透過正規表示式,將原始資料轉成CEF格式的檔案。
那麼,ParseMe的作法有何不同?安創資訊表示,系統會根據所收集到的原始範例資料,自動產生正規表示式,而能同時產生不同的標籤將資料內容區隔開來,最終再儲存成JSON等格式,後續用戶可選擇輸出CEF等多種格式。
簡而言之,安創資訊認為,ParseMe是一種資料自動解析器(AutoParser),能夠收納與處理文字型態的檔案格式與Syslog,製作成正規表示式,之後可直接套用到其他臺同類型設備的資料整理作業上,並且可以搭配SIEM、大數據/資料湖、商業智慧系統。
由於它的強項是能把這些不同格式的資料轉換成結構化資料、予以儲存,以便用戶進行後續分析,因此,這套系統可以廣泛支援各種資料科學的應用,而不僅止於資訊安全領域。
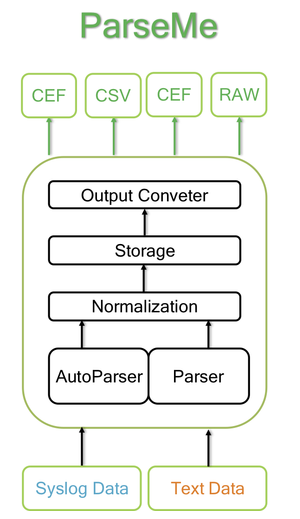
涵蓋資料的接收、剖析、儲存、匯出
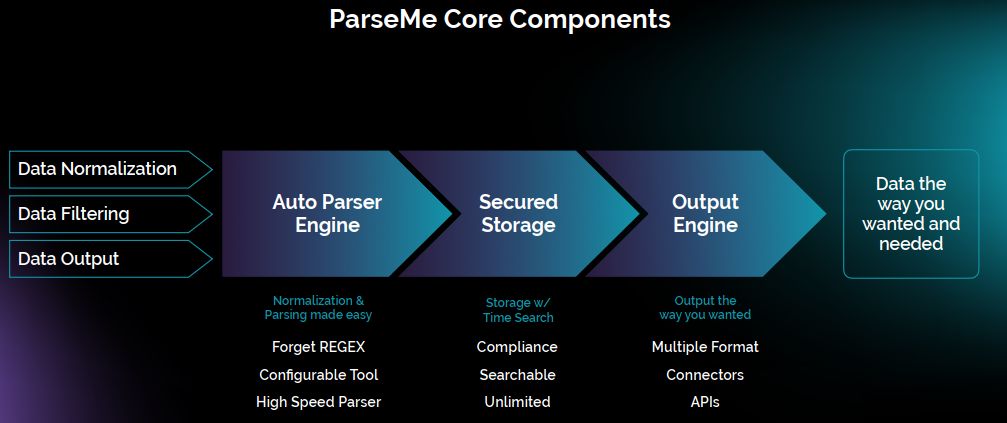
基於這樣的功能需求,安創資訊將ParseMe區分為三大核心元件:自動剖析引擎(Auto Parser Engine)、受保護的儲存區(Secured Storage),以及輸出引擎(Output Engine)。
以其中的自動剖析引擎來看,ParseMe提供了簡易操作的正規化與剖析功能,用戶不需設法撰寫正規表示式,可透過系統提供的設定工具介面來進行處理,而且剖析資料的速度極快。
資料儲存的部份,ParseMe可存放大量的原始資料,因應法規遵循的相關要求。這裡面會運用到兩三種加密演算法,以及壓縮技術,資料加密壓縮的比例可達到10:1。
ParseMe可搭配外部儲存設備來擴充儲存容量,同時,由於系統底層採用的是分散式資料儲存系統,因此,也可運用串連更多臺伺服器節點的方式,擴充儲存空間;若要尋找特定的資料內容,這裡也提供搜尋的機制,以便支援稽核、提交證據的工作。
而在最終輸出資料時,ParseMe也支援多種資料格式的轉換,像是SIEM系統常見的通用事件格式(CEF),或是一般系統都支援的逗點分隔值格式(CSV),並提供連結器(Connector)與API的整合方式。
關於系統的建置,安創資訊表示,ParseMe只需三臺電腦,即可因應資料接收的處理──ParseMe的系統需求並不高,他們開出的規格是4核心處理器、8GB記憶體、256GB固態硬碟(存放系統)、1TB傳統硬碟(存放資料),而在安創資訊設立的測試環境當中,僅用NUC迷你電腦,一樣能提供相關的功能。未來,ParseMe預計會支援上雲的部署方式。
產品資訊
安創ParseMe
●原廠:安創資訊
●建議售價:廠商未提供,授權分為兩種模式:無上限收容、按容量規模計價
●核心元件:Auto Parser Engine、Secured Storage、Output Engine
●資料擷取階段:接收記錄、剖析記錄、儲存記錄
●可連結的資料分析平臺:資料湖(Cloudera、Splunk、elasticsearch)、安全資訊事件管理系統(QRadar、Alien Vault、ArcSight、Splunk)、商業智慧系統(Qlik、Tableau、微軟Power BI)
●資料處理效能:每臺節點最高可達6萬EPS
●伺服器版硬體需求:4核心處理器、8GB記憶體、256GB SSD(存放系統)、1TB硬碟(存放資料)
【註:規格與價格由廠商提供,因時有異動,正確資訊請洽廠商】
熱門新聞

2026-02-11
</a> on <a href=\"https://unsplash.com/photos/blue-and-black-digital-wallpaper-uDO6NuH7WFU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash\">Unsplash</a>")
2026-02-11

2026-02-09

2026-02-10

2026-02-10

2026-02-06

2026-02-10

2026-02-10