
關於Nvidia發展的GPU架構Ampere,以及率先導入此架構的資料中心GPU產品A100,上市時間距今已超過兩年之久,後續也推出相當多款採用Ampere架構的GPU產品,範圍涵蓋了資料中心、專業繪圖、家用娛樂、邊緣運算等應用領域。而在今年3月舉行的GTC春季大會,他們終於宣布推出新一代GPU架構Hopper,以及第一款採用此架構的資料中心GPU產品H100。
這款GPU加速器內建了Transformer Engine運算加速引擎,並配備最新的第4代NVLink互連技術,能夠支撐巨型的AI語言模型、深層的推薦系統、基因體學運算,以及複雜的數位雙生(digital twins)。
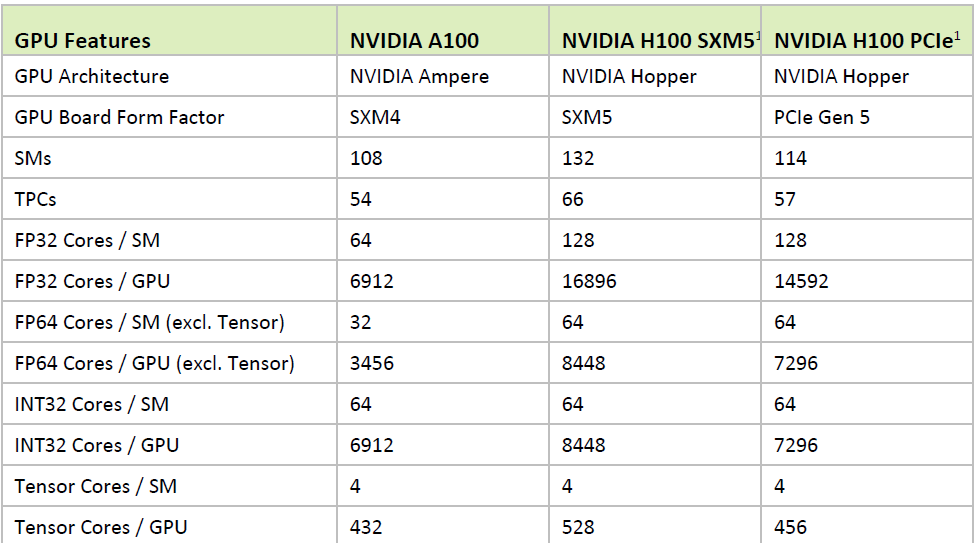
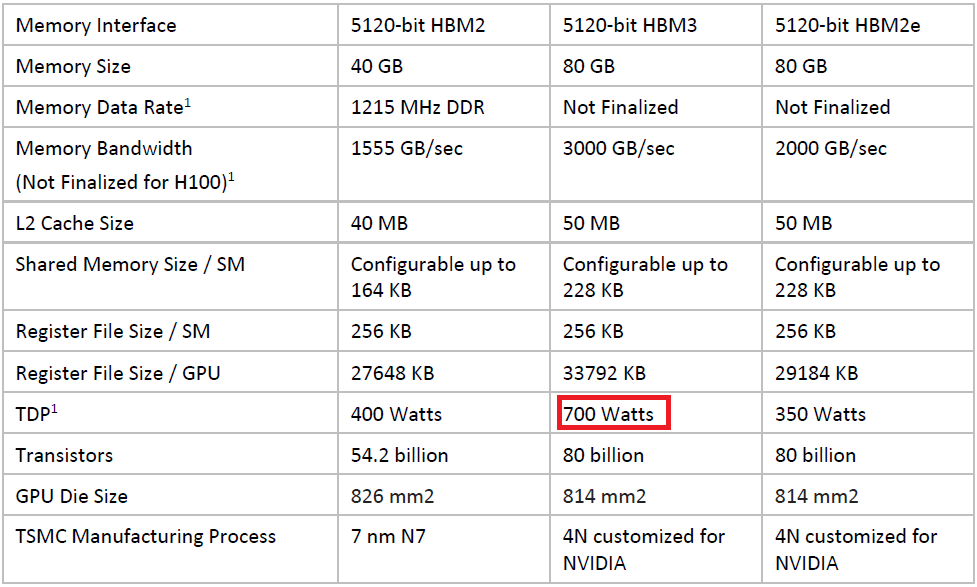
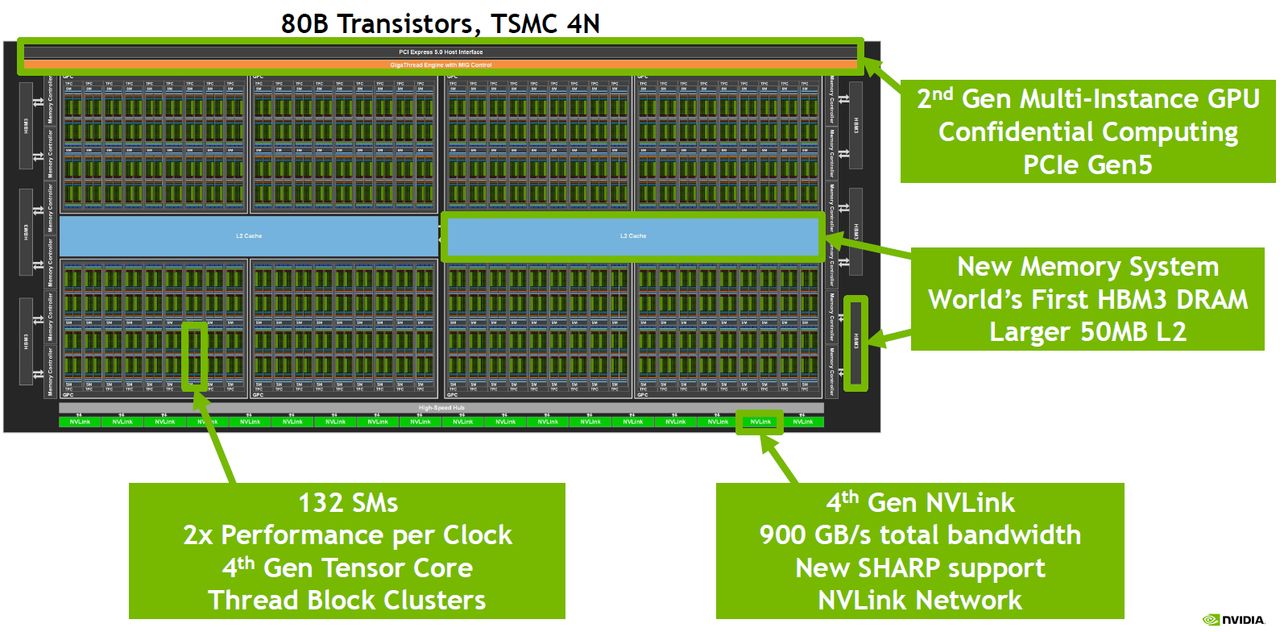
在運用的生產技術上,H100採用了台積電4N節點製程,內含800億顆電晶體,提供強勁的AI與HPC加速運算能力,而且率先採用PCIe 5.0的I/O介面,以及容量為80 GB的HBM3記憶體,以此提供3 TB/s或2 TB/s的記憶體頻寬。
相較之下,Nvidia目前主推的A100使用台積電7奈米N7製程,內含542億顆電晶體,採用PCIe 4.0的I/O介面,以及40 GB容量的HBM2、80 GB容量的HBM2e記憶體,以此提供1,555GB/s、1,935GB/s或2,039GB/s的記憶體頻寬。

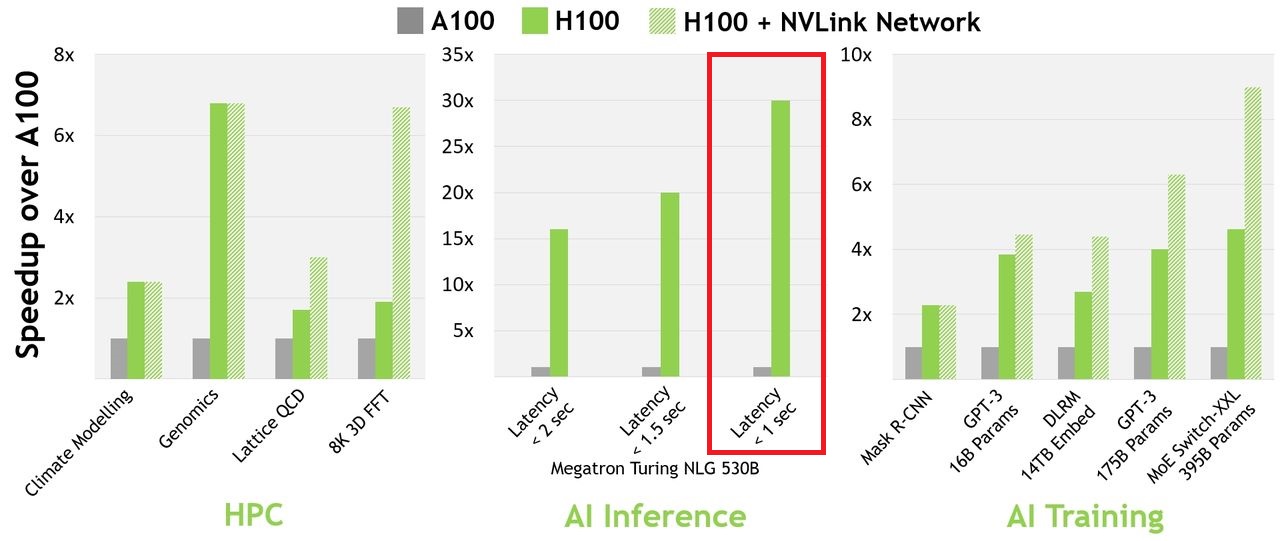
在運算效能的突破上,Nvidia在最初發布時,曾揭露一些他們測試的成效。例如,若搭配InfiniBand互連網路使用,H100可以達到30倍於A100的AI與HPC效能——運用Nvidia釋出的單體大型語言模型Megatron-Turing NLG 530B(Megatron 530B)時,在因應聊天機器人即時對話AI延遲需達到低於1秒之下的要求時,可提供30倍的吞吐量。
針對研究人員與開發者訓練大型模型時,使用H100能將所需時間從數週驟減至數天——處理帶有3,950 億個參數的Mixture of Experts(MoE)模型時,速度可提升至A100的9倍。
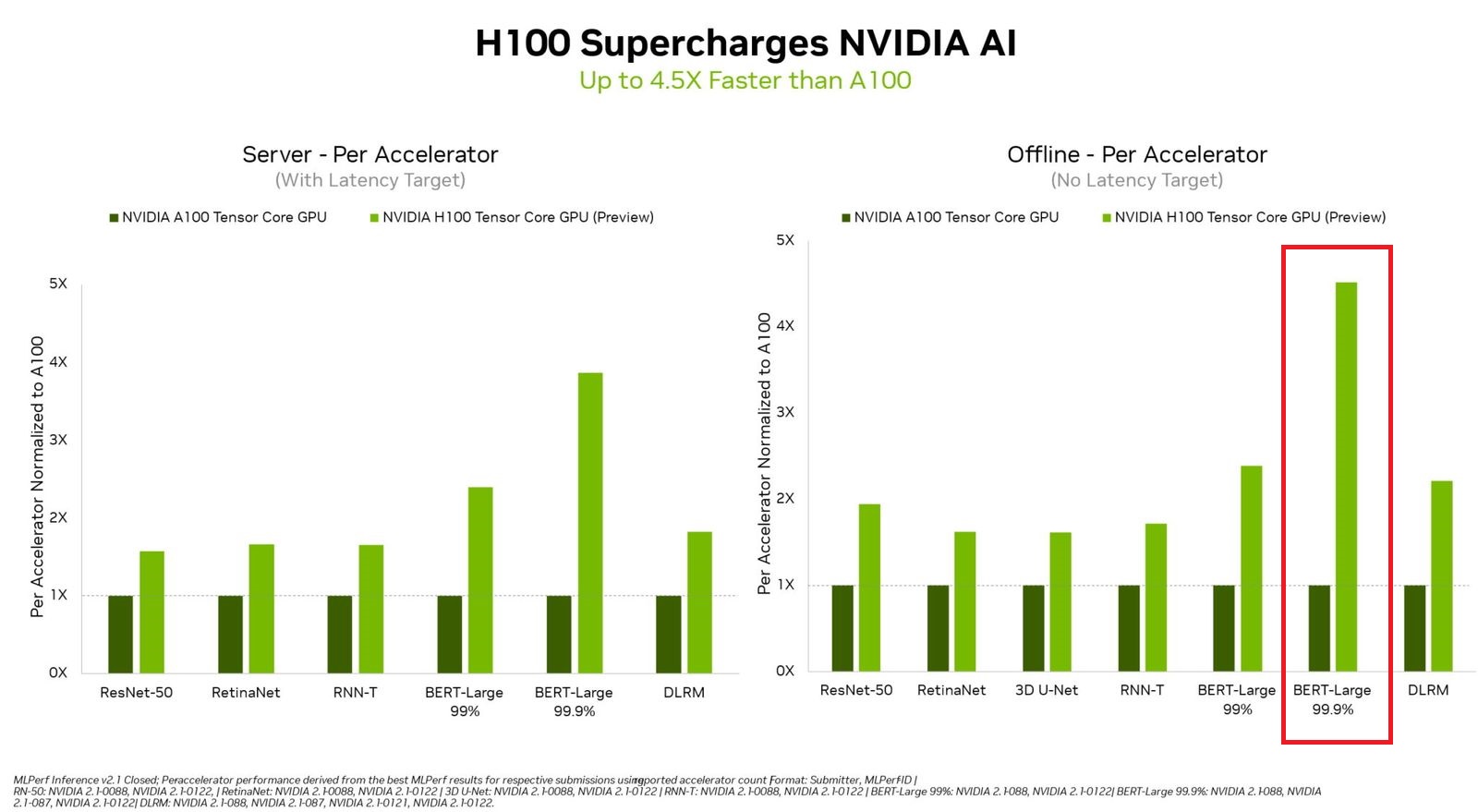
而在經歷了將近半年之久的現在,終於又有新的H100效能表現資訊。根據MLCommons在9月8日公布的最新AI推論效能測試結果,也就是MLPerf Inference v2.1,Nvidia首度提交H100的測試數據,相較於A100,這款最新推出的資料中心GPU可提供4.5倍的效能——在自然語言處理運用BERT這套模型的測試中,A100每秒可處理1756.84個樣本,H100每秒可處理7921.10個樣本。
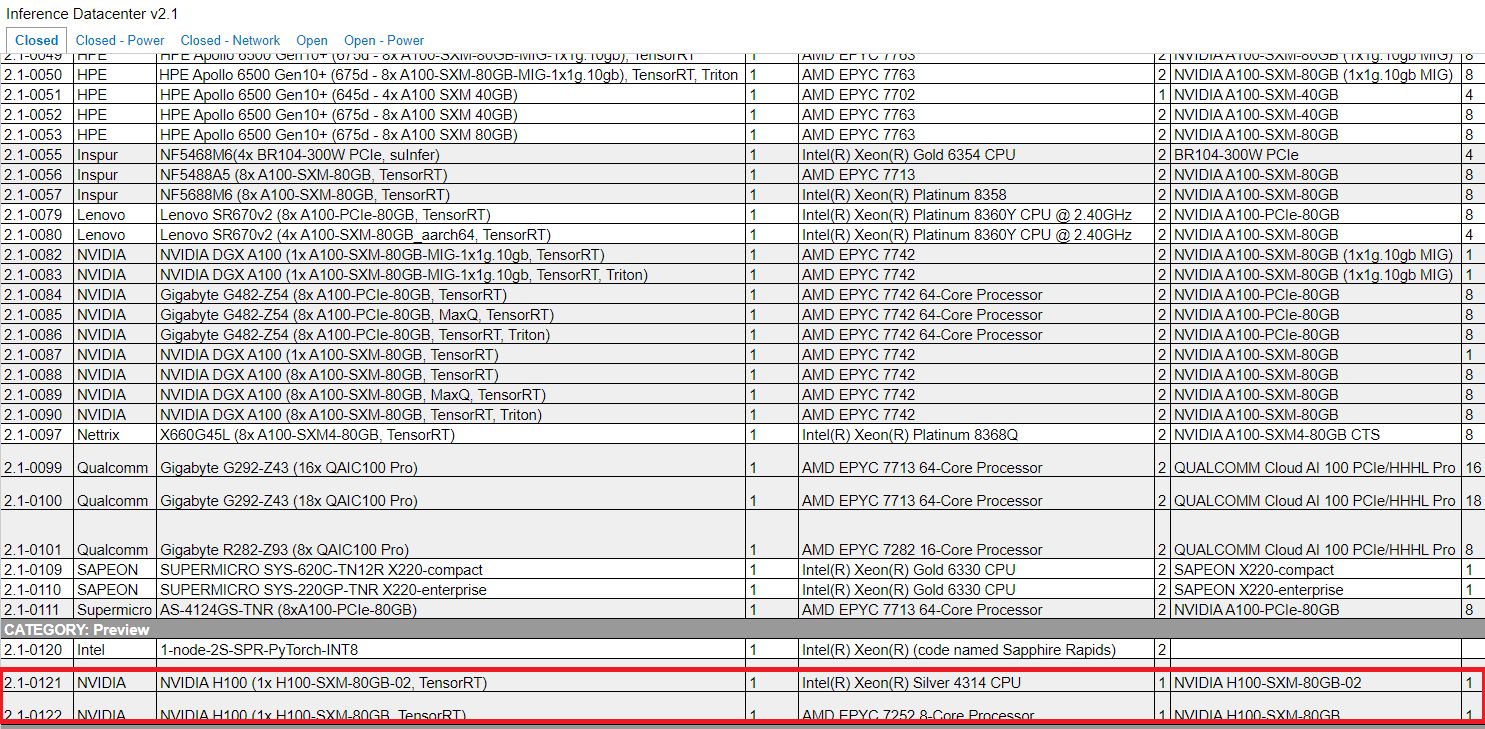
Nvidia表示,這些推論基準測試是H100首次公開展示,並預告此產品將在今年稍晚上市,以及未來將參與MLPerf訓練測試。
效能提升幅度創造新紀錄,但功耗也跟著水漲船高
GTC 2022春季大會期間,Nvidia執行長黃仁勳發表H100時,強調這款新一代資料中心GPU帶來多項運算效能的突破,舉例來說,在FP16、FP32、FP64、TF32等資料型別的處理效能上,H100都可達到A100的3倍,若用上這款GPU新支援的FP8資料型別,則可提供4,000 TFLOPS效能,相較於A100用現行支援資料型別FP16進行相關處理,H100現在可達到6倍的效能增長幅度。

在熱設計功耗(TDP)上,黃仁勳也提到H100是專為氣冷與液冷系統設計,並且是第一款為了效能而將功耗提升至700瓦的GPU。而在檢視H100的技術規格來看,SXM版本的最大熱設計功耗確實是700瓦,PCIe版本則是350瓦。相較之下,現行的A100,SXM版本為400瓦,PCIe版本則有250瓦、300瓦等兩種配置(GPU記憶體分別為40 GB、80 GB)。
700瓦的耗電量看起來很驚人,這似乎對整個GPU伺服器生態形成不小的挑戰。因為,從3月發表H100至今,除了Nvidia當時發表的AI整合應用設備DGX H100,確定是搭配此款GPU,截至目前為止,我們一直都沒看到有任何伺服器廠商,公布他們可搭配H100 SXM版本的伺服器產品機型。
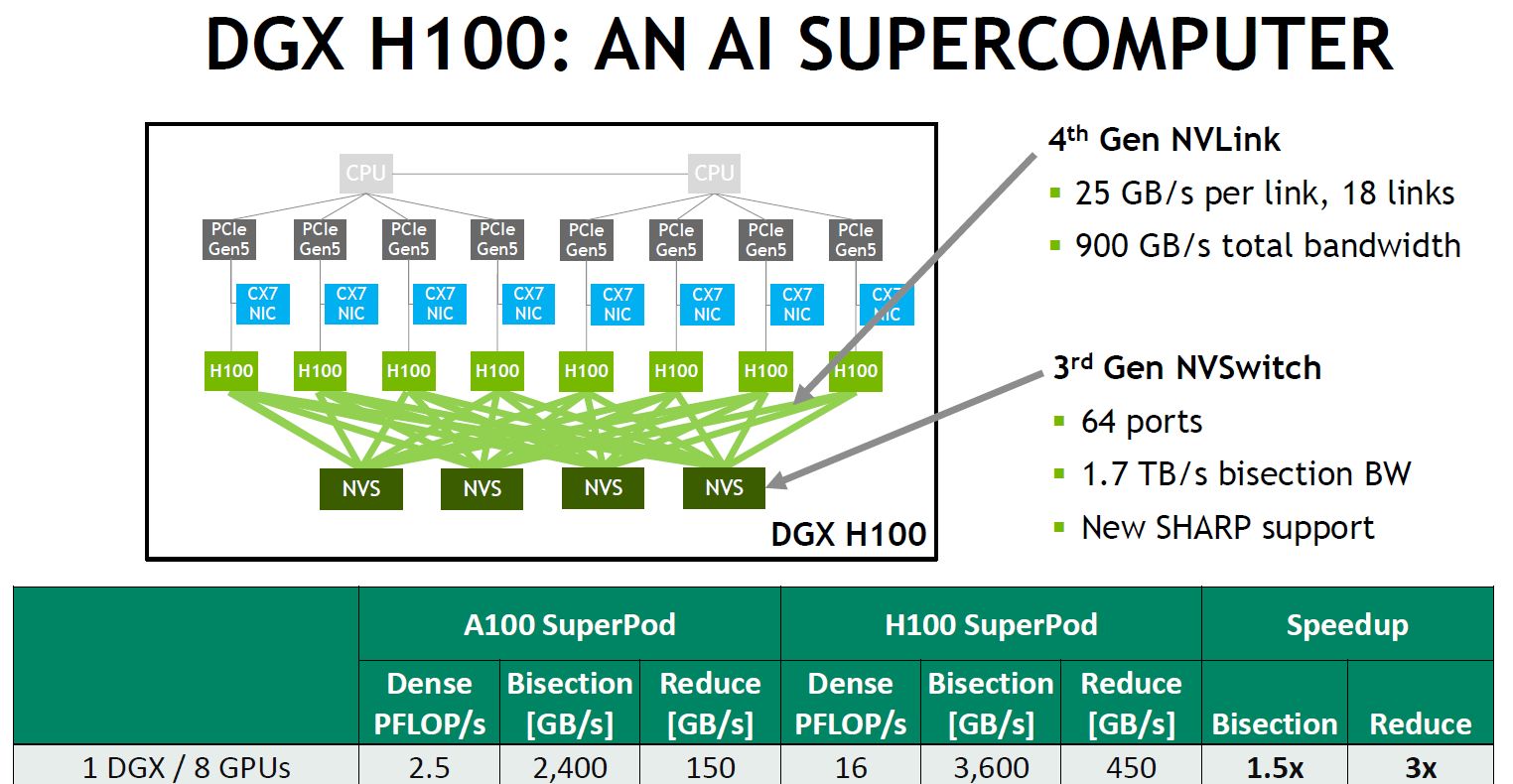
值得注意的是,Nvidia在H100的資料規格表與技術架構文件中,均提到SXM版本的伺服器搭配方式有兩種,一是採用8個H100的DGX H100,另一是透過搭配HGX H100整合伺服器主機板的合作廠商,當中將會配置4個或8個H100,其中的4-GPU組態將包含NVLink連結,以支援GPU之間的連接與CPU、GPU之間的連接;8-GPU組態將包含NVSwitch晶片,並且針對GPU之間的連接去提供完整的NVLink頻寬——黃仁勳在GTC 2022春季大會主題演講提到,在HGX系統主機板上,8個SXM版本的H100,將會透過4個NVSwitch晶片來連結,每個NVSwitch晶片將提供3.6 TFLOPS的SHARP網內運算能力。
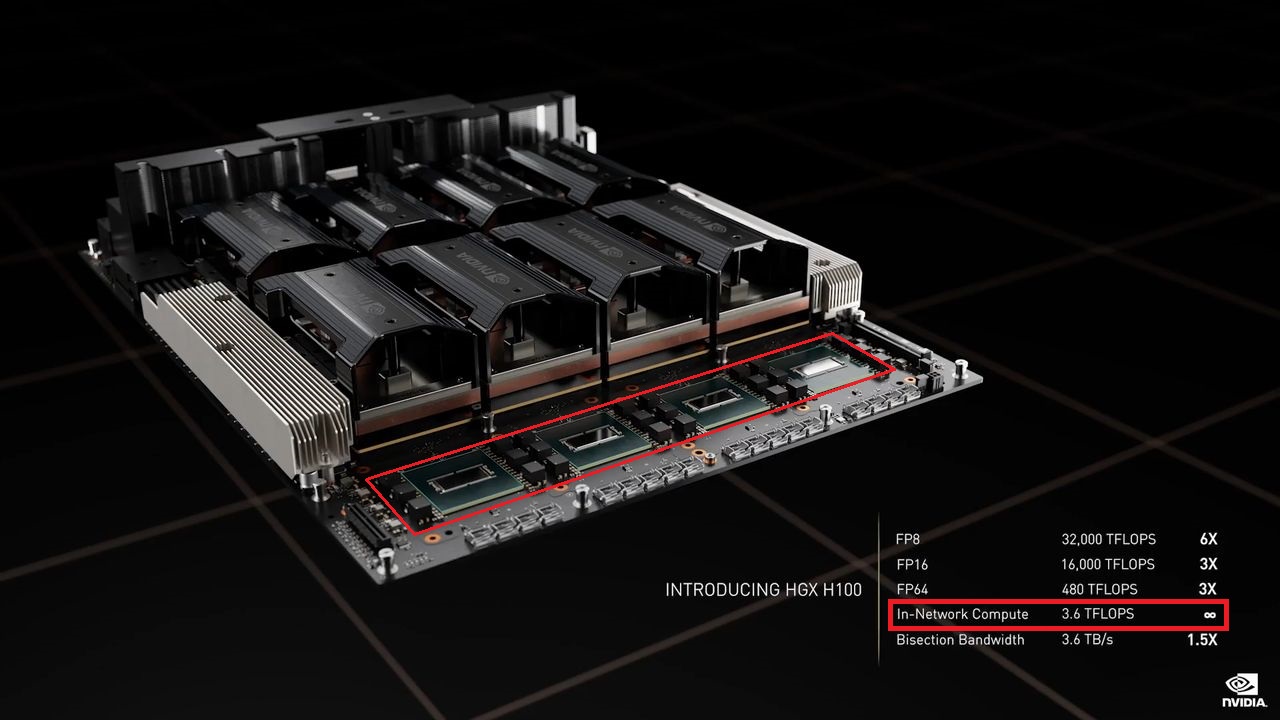
關於連接的特性上,這裡所用到的NVSwitch晶片是第三代技術,每個交換器可提供64個第4代NVLink連結埠,吞吐量可達到13.6 Tbps(第二代NVSwitch為7.2 Tbps),除此之外,第三代NVSwitch晶片也內建硬體加速,能用於集合型處理,如群播(multicast)、SHARP網內運算減量處理等。

串流複合處理器的設計突破
在Nvidia歷代GPU架構當中,關於串流複合處理器(Streaming Multiprocessor,SM)內部的配置方式,以及新增的運算方式,經常是技術創新的關鍵。在這次報導當中,我們先介紹Tensor Core核心,以及新增的指令集DPX。
以現行的資料中心GPU產品A100而言,內含108個SM,今年登場的新一代GPU產品H100,SXM5版本內含132個SM,PCIe版本內含114個SM;而在每個SM內部設計上,A100採用6,912 顆FP32(CUDA)核心,432顆Tensor Core核心;到了H100,SXM5版本採用16,896顆FP32核心、528顆Tensor Core核心,PCIe版本採用14,592顆FP32核心、456顆Tensor Core核心。顯然H100不論在SM處理器、FP32核心、Tensor Core核心,都比上一代資料中心GPU產品配置了更多數量。
除此之外,H100也翻新部分運算核心設計。例如,相較於A100採用的第三代Tensor Core,H100使用第4代Tensor Core核心,運算速度可增長至6倍;針對相同的資料型別,H100執行矩陣乘積累加運算(Matrix Multiply-Accumulate,MMA)時,可提供2倍於A100的處理能力;若運用H100新支援的資料型別FP8,對比於使用FP16的A100而言,計算能力可增長至4倍之多。
H100另一個有別於過往資料中心GPU產品的新增運算功能,就是號稱可加速動態程式編寫(Dynamic Programming)的DPX指令集,黃仁勳表示,這種程式化處理方式,能將複雜的問題截斷,成為可透過遞迴處理方式解決的簡單子問題,使處理複雜度與所需時間減至由多項式處理的規模,他認為,若能運用這種方式,H100的DPX可將演算法的效能提升至原本僅靠CPU進行運算時的40倍,若是基於上一代GPU來處理這類狀況,DPX也能提供7倍的強化效果。
Nvidia表示,DPX可廣泛用於路線最佳化、基因體學、圖形處理最佳化等多種領域的演算法。舉例來說,在動態倉儲環境下,可能會運用Floyd-Warshall演算法,協助機器人在自動行進時尋找最佳路線;若要針對DNA、蛋白質進行分類、基因定序、摺疊處理時,則會用Smith-Waterman 演算法進行特徵比對、序列對準。
針對多種AI語言模型採用的Transformer模型,新設置專屬的加速引擎
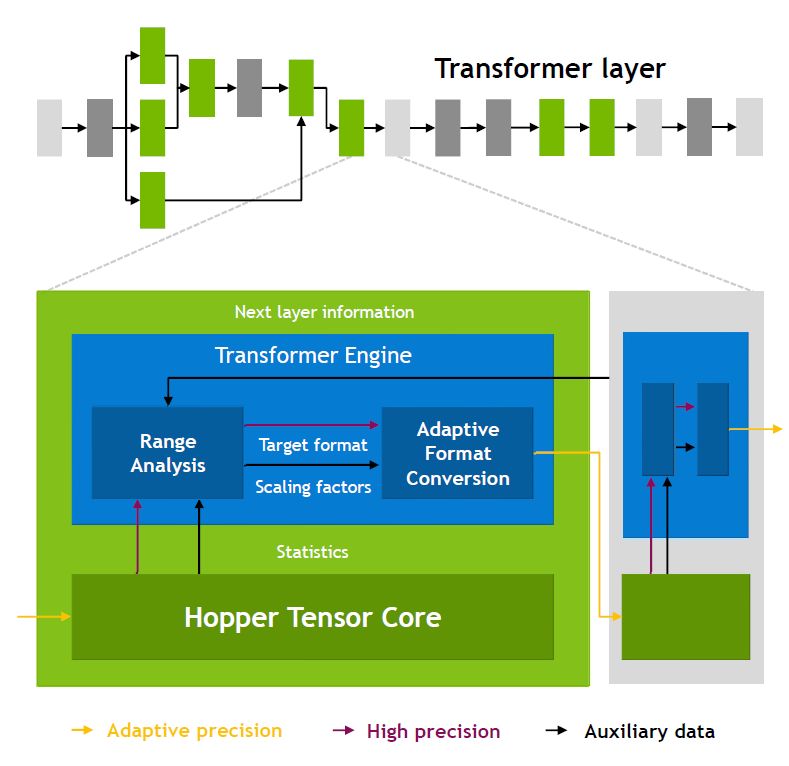
關於H100新增的加速引擎Transformer Engine,是專為自然語言處理的深度學習標準模型Transformer所設。事實上,Transformer是一套廣受BERT、GPT-3等知名語言AI模型所採用的模型,若以Nvidia前一代產品為基準,配備此引擎的H100在神經網路運算上,可達到6倍的速度,並兼顧精準度。
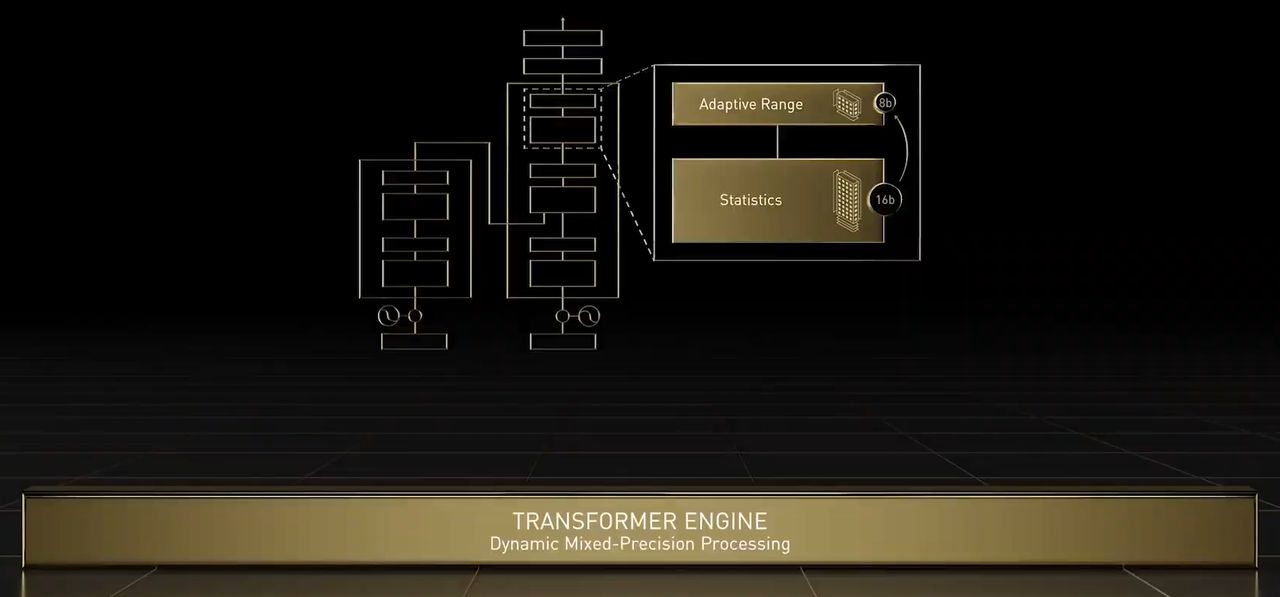
基本上,Transformer Engine結合特製的Hopper Tensor Core技術與軟體,能夠動態處理Transformer網路的多個層級,可用於加速Transformer模型的訓練與推論,黃仁勳表示,訓練Transformer模型所需時間,能從數週縮減至數天。這當中利用16位元精度與新增的8位元浮點資料格式(FP8),再搭配進階的軟體演算法,而能進一步加速AI效能與處理能力。
對於FP8與16位元計算,它能以聰明的方式進行管理與動態選擇,在兩者之間的每一個曾集中,自動處理重新分派(re-casting)與規模擴展。因此,同樣面臨大型語言模型的處理,相較於A100,H100可獲得AI訓練速度提升至9倍,以及AI推論速度增長至30倍的成效。
多執行個體GPU技術邁入第二代
為了能夠更充分運用資料中心GPU,Nvidia從A100開始實作硬體層級的GPU分割技術,稱為多執行個體GPU(Multi-Instance GPU,MIG),能將單個GPU加速器區隔為7個較小、完整隔離的GPU執行個體。
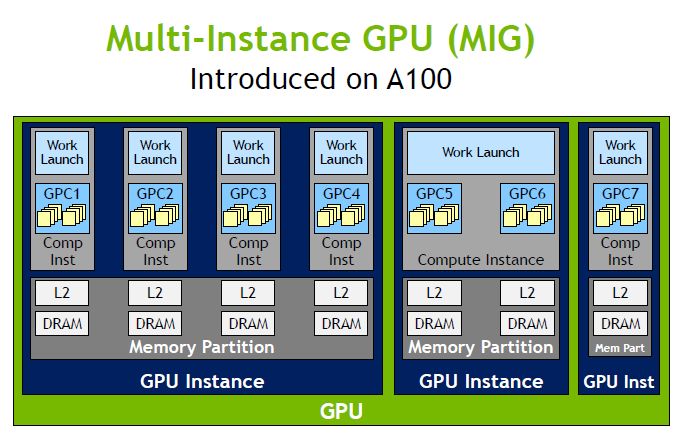
到了最新推出的H100,引進第二代MIG技術,處理能力可提升至原先的7倍,能在雲端環境中橫跨每個GPU個體,提供安全的多租戶服務組態。
對此,黃仁勳表示,Hopper架構增加了每個GPU執行個體的完整隔離,以及I/O虛擬化能力,支援雲端環境的多租戶應用需求。以H100為例,雲端服務租戶可同時承載7個,A100只能承載1個。
以每個GPU執行個體而言,若以A100的第一代MIG為基準,H100的第二代MIG可提供近3倍的運算容量,以及近3倍的記憶體頻寬。單就性能而言,黃仁勳認為,H100的單一GPU執行個體,可提供相當於2張Nvidia T4 GPU的效能。
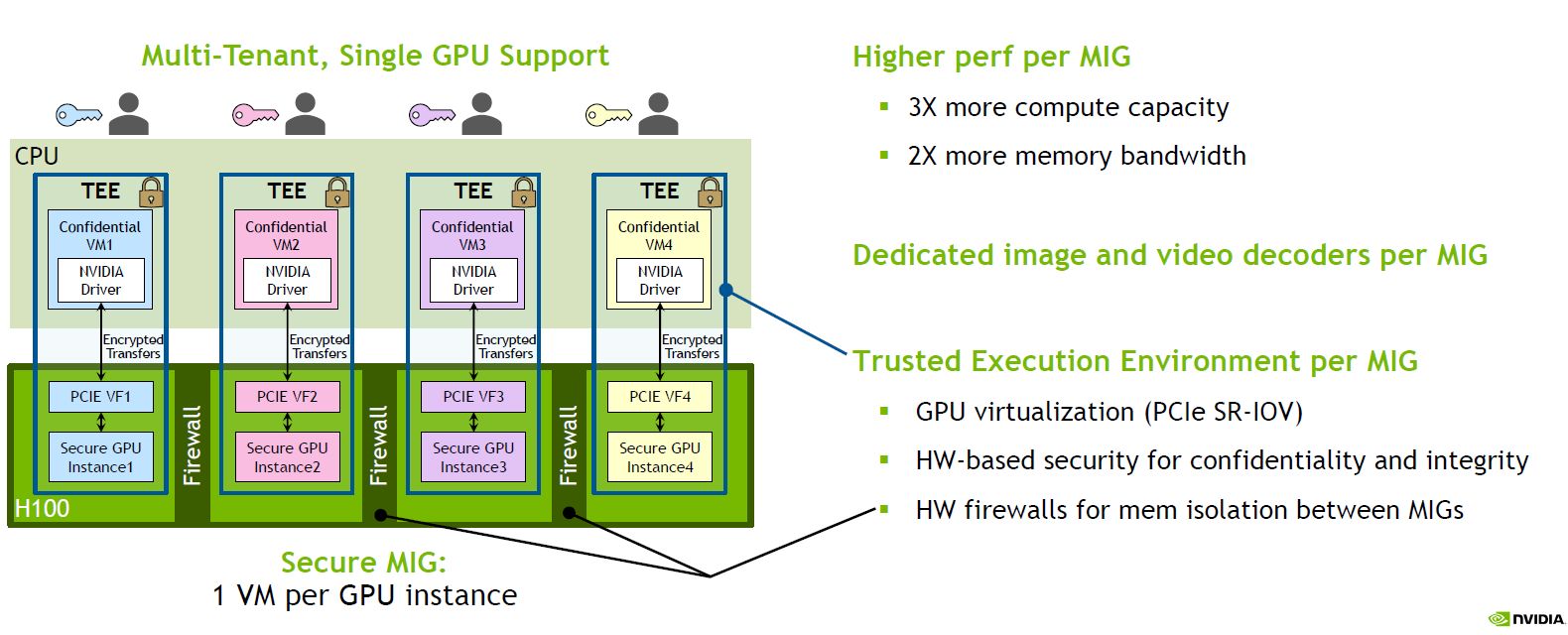
關於機密運算的支援,也是本次H100的最大賣點之一,黃仁勳強調過往這類資料保護應用僅限於CPU系統,而Hopper是率先提供GPU機密運算的解決方案,足以保護用戶AI模型、演算法的機密性與完整性,使開發者與服務業者在共用或遠端IT基礎架構環境當中,安心散布、部署各種寶貴的專屬AI模型,兼顧保護智慧財產與拓展業務模型的需求。
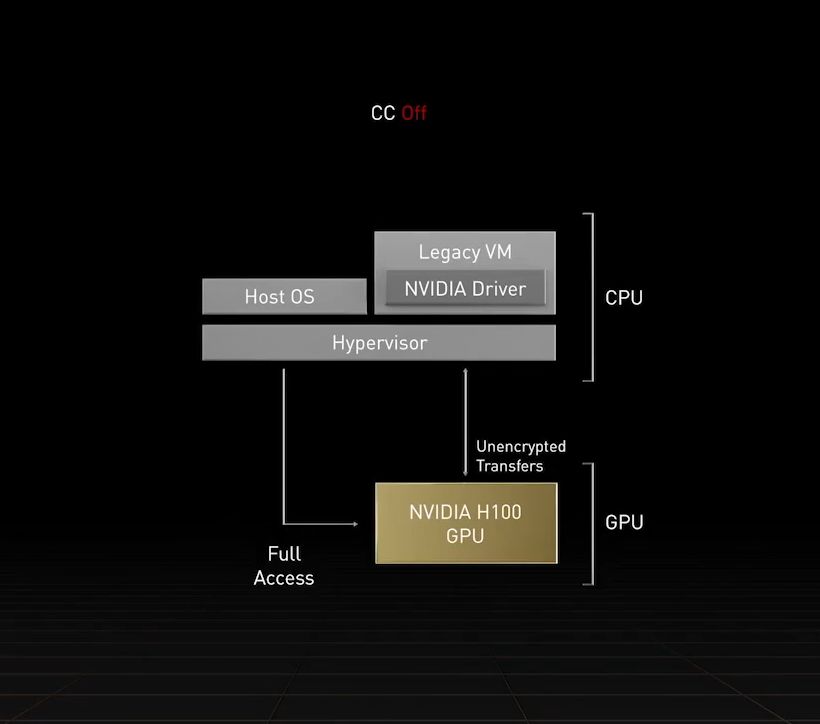
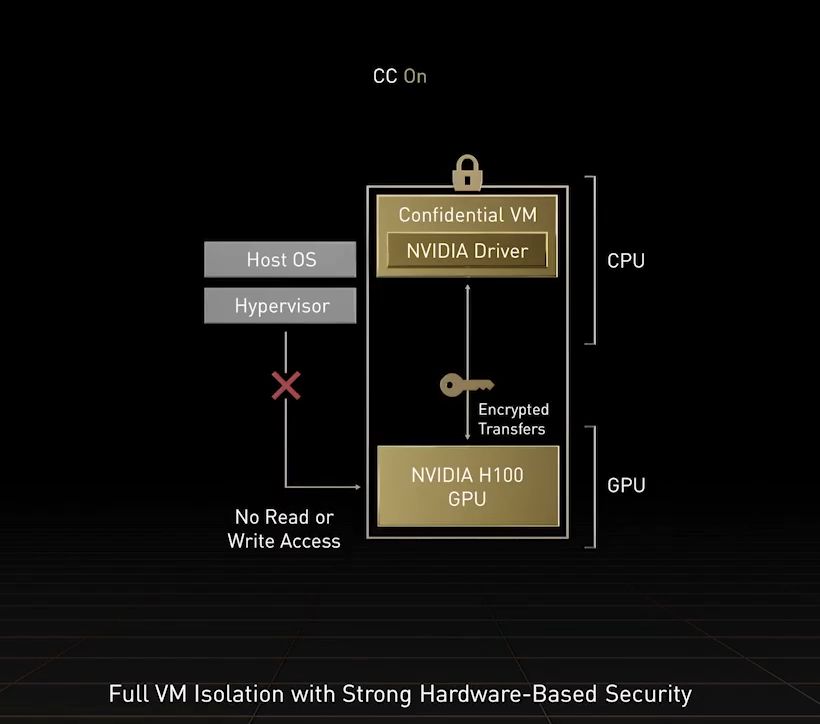
Nvidia宣稱這是第一款配備機密運算的加速器,能在處理AI模型與客戶資料時,提供保護。同時,企業也能運用這款產品,針對醫療照護、金融服務等隱私敏感產業的聯邦學習AI應用,以及雲端共用基礎架構,實施機密運算。
事實上,H100不僅是整個GPU支援機密運算,在MIG層級的信任執行環境(TEE),也提供實作機密運算的能力——內部的7個GPU執行個體均可支援,每個皆可配置專屬的NVDEC、NVJPG等兩種解碼器單元,也包含獨立的效能監控機制,可搭配Nvidia的開發者工具使用。
導入新一代NVLink與NVLink Switch,提升I/O頻寬
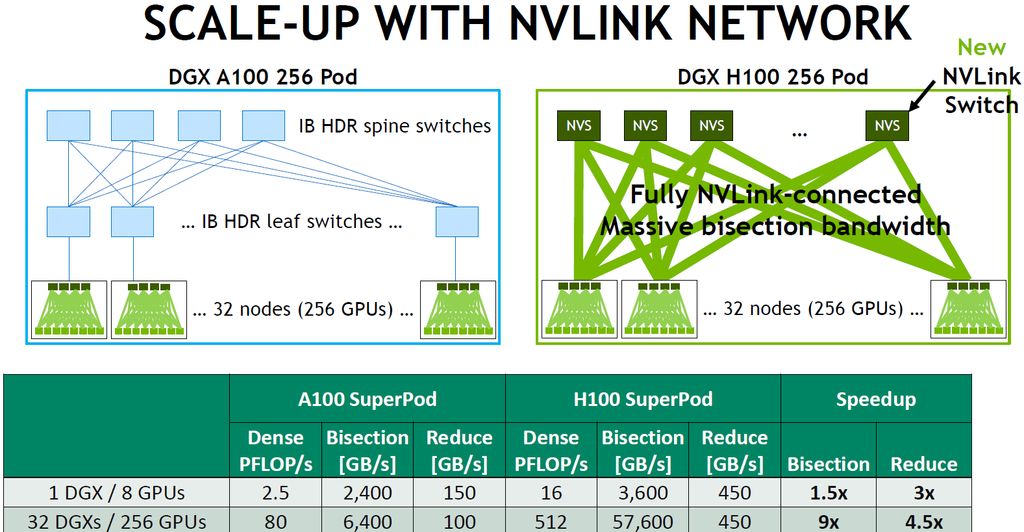
在晶片互連介面的部分,H100導入第4代NVLink,可結合第三代NVSwitch晶片,以及外部的NVLink交換器來延伸NVLink,能夠越過伺服器、向外建立可縱向擴展規模的網路系統,形成所謂的NVLink Switch System,不僅最多能同時連接256個H100,相較於前一代透過HDR Quantum InfiniBand網路連接的方式,還能提供9倍的存取頻寬。
Nvidia表示,NVLink Switch System能夠連結大量GPU,用於2比1的錐形、胖樹型(fat tree)拓樸,在多對多連結的狀態下,所有節點的存取頻寬可達到57.6 TB/s,足以支撐1 EFLOP的FP8型別AI運算,同時,還能以此提供隔離與保護機制。
產品資訊
Nvidia H100
●原廠:Nvidia
●建議售價:廠商未提供
●處理器製程:TSMC 4N
●I/O介面:PCIe 5.0
●外形:SXM5、PCIe雙槽介面卡(氣冷)
●GPU架構:Nvidia Hopper
●GPU核心:SXM5版本為16896顆CUDA核心、528顆Tensor Core,PCIe版本為14592顆CUDA核心、456顆Tensor Core
●GPU記憶體:80 GB,SXM5版本搭配HBM3,PCIe版本搭配HBM2e
●記憶體頻寬:SXM5版本為3 TB/s,PCIe版本為2 TB/s
●運算效能:雙精度(FP64)SXM5版本為30 TFLOPS,PCIe版本為24 TFLOPS
●GPU互連介面:第4代NVLink,SXM5版本為900 GB/s,PCIe版本為600 GB/s
●耗電量:SXM5版本為700瓦,PCIe版本為350瓦
【註:規格與價格由廠商提供,因時有異動,正確資訊請洽廠商】
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09

2026-02-06


2026-02-09

2026-02-09