
在2021年11月,AMD發表資料中心GPU產品Instinct MI200系列,時隔兩年之後的現在,他們終於推出新一代產品Instinct MI300X,採用CDNA3架構,導入先進的3D封裝與小晶片(chiplet)技術,而能提供更強大的運算效能。
相較於上一代產品MI250X,MI300X的運算單元數量增加幅度逼近40%(304個對上220個),記憶體容量達到1.5倍(192 GB HBM3對上128 GB HBM2e),記憶體最大頻寬為1.7倍(5.3 TB/s對上3.2 TB/s);在資料型別上,MI300X可支援FP8與稀疏(sparsity)等數學計算,種種新增與強化特色,皆為了支撐AI與高效能運算類型的工作負載而來。
在產品的使用上,MI300X本身的外形採用開放運算計畫(OCP)訂定的加速器模組標準(OAM),能讓廠商將其置入既有支援這類外形GPU的伺服器配置當中,可加速這類AI硬體平臺的採用。

GPU架構重新設計,提供數量略勝一籌與記憶體配置彈性更大的GPU分割方式
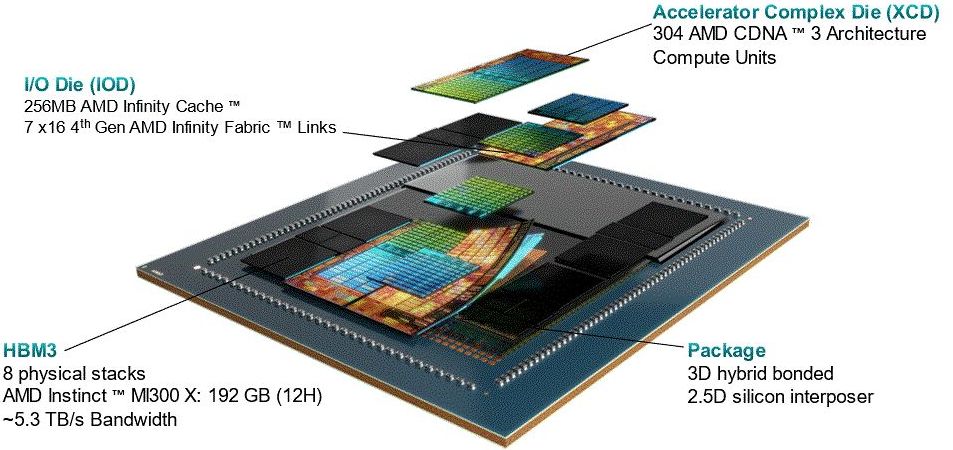
根據AMD公布的CDNA3架構白皮書指出,此架構重新畫分處理器的運算、記憶體、通訊元件,並且橫跨了異質封裝,MI300X整合8個垂直堆疊的「加速器複合晶粒(XCD)」——採用台積電5奈米製程,以及4個「I/O晶粒(IOD)」——採用台積電6奈米製程,以此涵蓋整個系統基礎架構,所有元件全部連接AMD Infinity Fabric技術當中,可接取8個高頻寬記憶體堆疊。

AMD表示,以最底層的技術架構來看,GPU核心在存取向量與矩陣資料時的運算吞吐量,可透過原生支援稀疏資料(sparse data)而獲得強化;而從巨觀角度而言,這樣從本質重新思考實作方式,搭配重新設計的快取與記憶體階層,可隨著運算量的增加而溫和地擴展執行規模,同時也整合快取一致性予以優先看待。
以MI300X為例,這款獨立GPU聚焦加速運算的應用,本身結合8個XCD,對於機器學習處理的運算精度降低資料(reduced precision data),最大可提供3.4到6.8倍的吞吐量,若用於FP8型別的資料,最大可提供2.6 PFLOPS效能,若處理使用單精度與雙精度的典型高效能運算工作負載,吞吐量可增加1.7到3.4倍,單個GPU的FP64矩陣運算效能為163.4 TFLOPS。
就CDNA3的運算單元而言,最大的改善是在矩陣核心單元(Matrix Core Unit),著重AI與機器學習的應用——針對頂尖訓練與推論常用的既有資料型別,強化運算吞吐量,其中一個關鍵是使用更緊緻的資料型別,可一併節省記憶體與快取容量資源的使用,改善吞吐量的同時,也降低耗電量,舉例來說,若使用FP16與BF16,可獲得3倍的效能提升,若使用INT8,效能增長幅度達到6.8倍(相較於MI250X)。
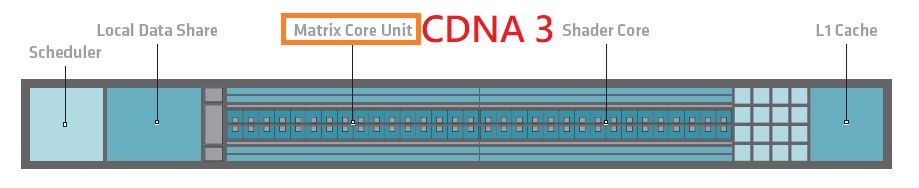
AMD CDNA 3 Matrix Core在資料型別上,新支援最便於使用的TF32,以及透過最小規模提供最大效能的FP8,也支援FP8的兩種變體,一是5位元指數搭配2位元尾數的E5M2,用於AI訓練,一是4位元指數搭配3位元尾數,用於AI推論,兩者都列於OCP訂定的8位元浮點數規格。
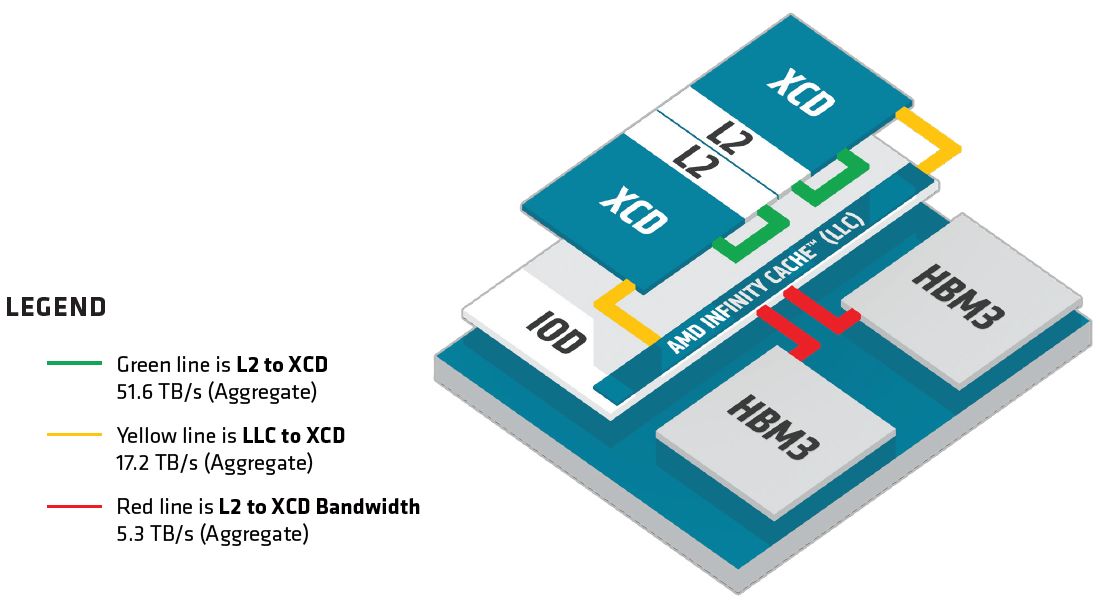
在CDNA3架構中,與先前世代差異最大的部分在於運算單元外面的記憶體階層,經過重新設計架構之後,可充分運用多個異質小晶片的優勢,促成共同封裝在處理器的小晶片,能有一致的快取使用。
AMD認為,這樣的記憶體階層重新設計,真正開放了XCD內部的L2快取共享,而L2快取隨著位於IOD的最末階快取AMD Infinity Cache的加入,有了本質的變化,部分記憶體原生的功能被移除而提升到AMD Infinity Cache來執行——L2快取變成最低階的快取,會由硬體來自動維護一致性,在此同時,記憶體可在運算單元維持更豐富的資源混合,可將它們從一致性流量當中隔離,並且針對連至AMD Infinity Fabric網路的介面進行最佳化處理。
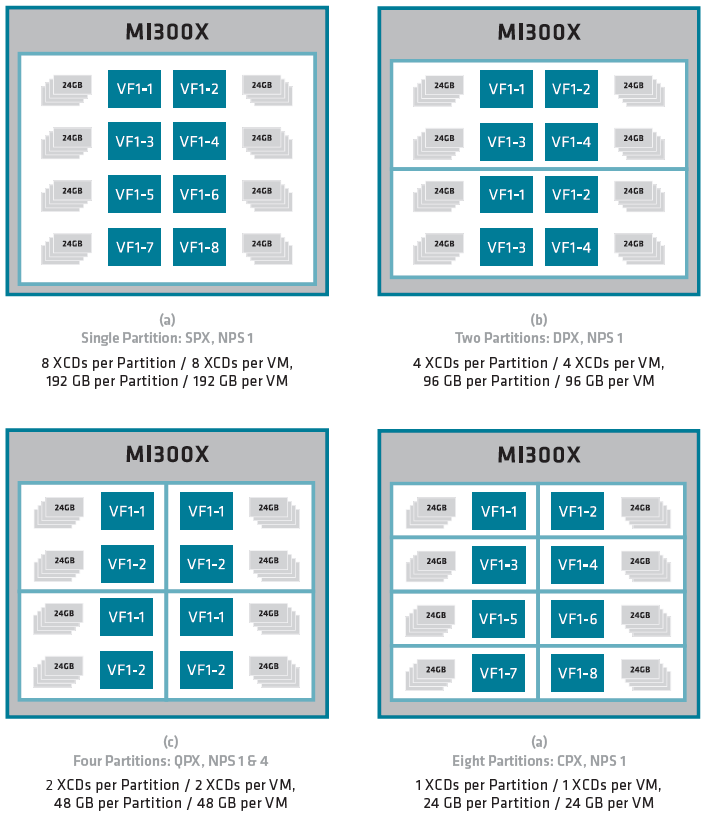
值得注意的是,AMD在CDNA3架構當中,也提供將單個GPU分割為多個虛擬GPU的功能,令人聯想到Nvidia的多執行個體GPU(MIG),目前已在Ampere架構與Hopper架構資料中心GPU產品提供(A100、H100最多可設置7個GPU執行個體,A30是4個)。
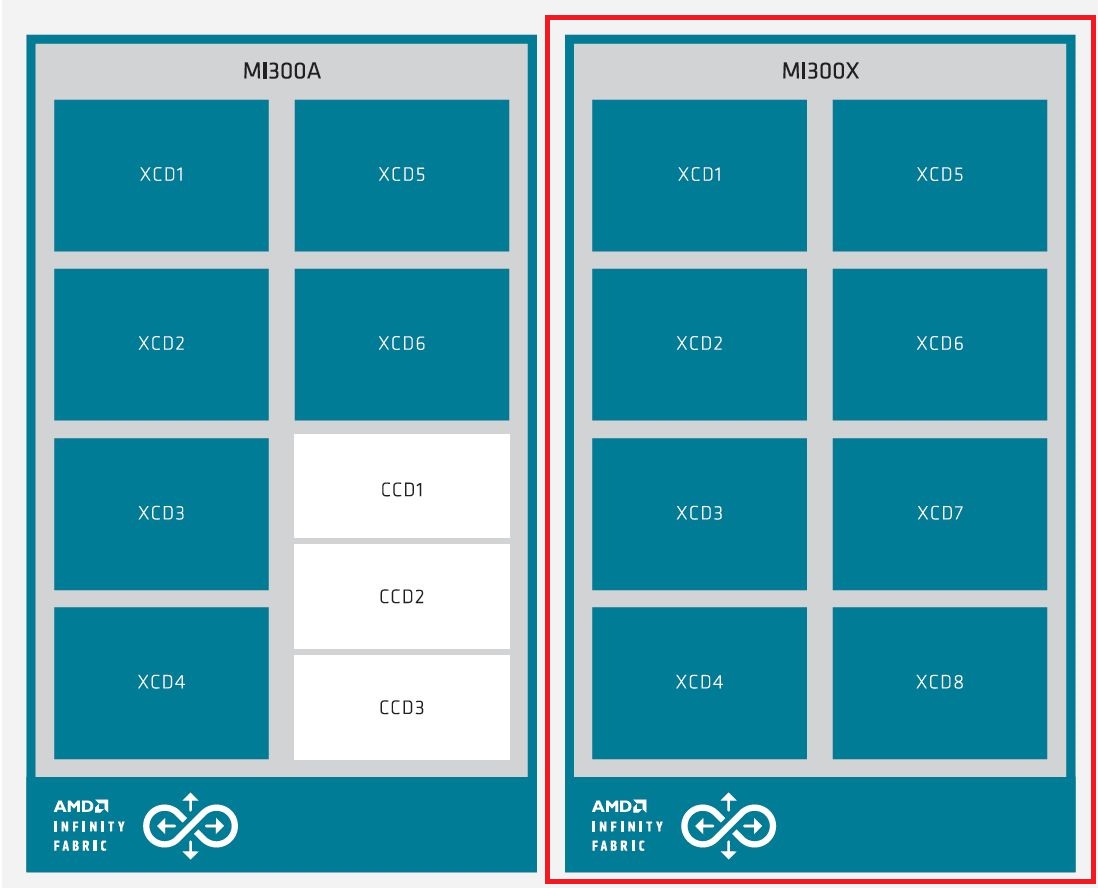
由於AMD Instinct MI300X包含8個XCD,這些硬體單元可各自分開、個別運作,形成多個虛擬GPU,最多能設置8塊區域,每一塊對應一個XCD,而且這裡也支援單根I/O虛擬化技術(SR-IOV),提供區分為多個虛擬功能(Virtual Functions,VF)的隔離執行機制,每個虛擬功能不能存取其他虛擬功能、實體功能(PF)的資訊或狀態。
MI300X內建的高頻寬記憶體也能根據GPU的分割而區隔,可設置為一大塊或4大塊,也能從GPU分割當中個別設定,AMD稱之為單體NUMA分割(NUMA partitions per socket,NPS),這些記憶體分區數量可等同或小於GPU分割數量。
標榜運算效能可超越競爭對手的產品
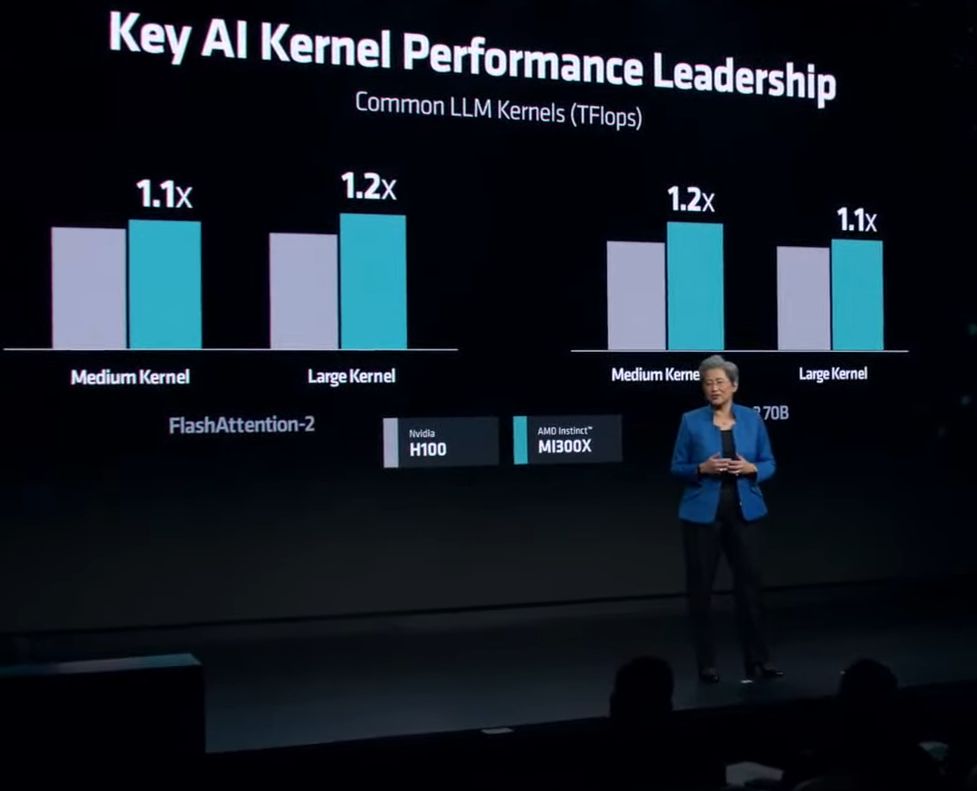
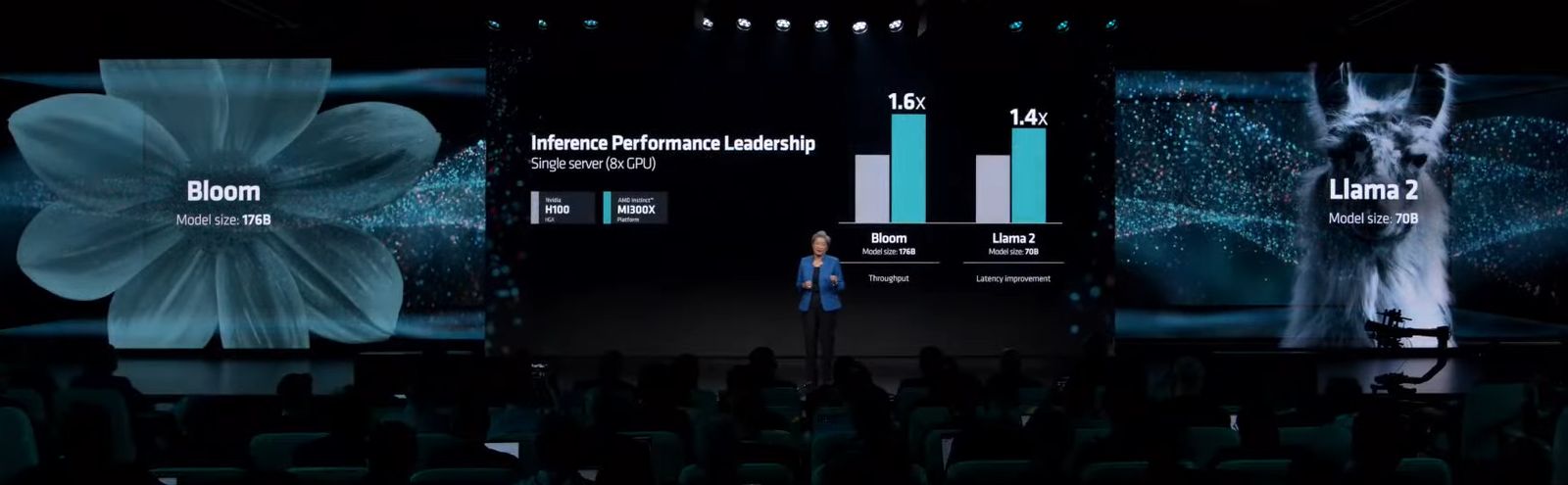
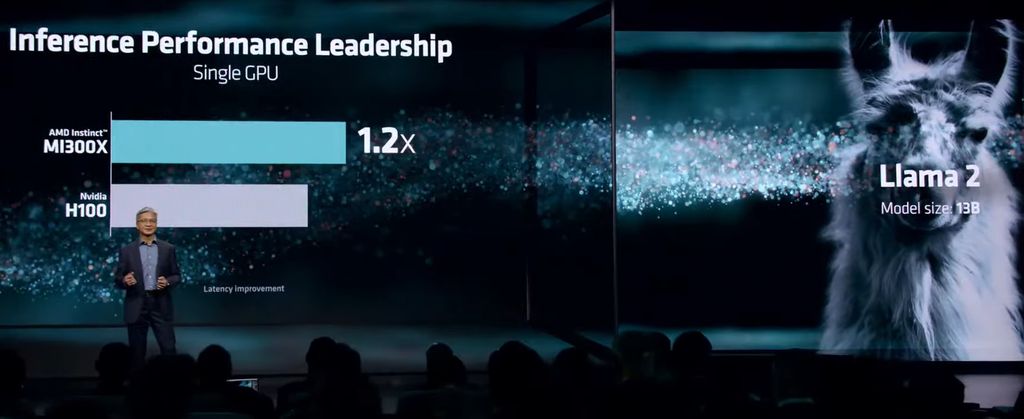
在大型語言模型(LLM)的使用上,AMD也特別強調MI300X的表現優於其他競爭產品。根據他們的內部測試,與市面上當紅的Nvidia H100 HGX整合多個資料中心GPU的平臺相比,同樣執行參數多達1,760億個的Bloom模型、使用DeepSpeed執行推論運算時,採用AMD Instinct Platform同樣匯集8個MI300X於一機的伺服器,吞吐量可達到1.6倍。若以單個GPU而言,要用於Llama2這類具有700億個參數大型語言模型的推論,AMD表示,MI300X是市場上唯一有辦法能承擔運算需求的產品。


基於這樣的配置與性能,他們認為MI300X可簡化企業級大型語言模型的運算系統部署,並且達到更理想的總體擁有成本。

關於有意採用的雲端服務業者方面,微軟在11月中舉行的Ignite年度用戶大會期間,搶先預告將推出採用這款GPU的運算服務ND MI300X v5;到了12月初AMD舉行的Advancing AI發表會,Oracle Cloud Infrastucture預告將會在裸機運算服務當中,推出搭配MI300X的解決方案,將支援該公司發展超級叢集網路OCI Supercluster,當中將配備超快速的RDMA網路技術,並表示他們的生成式AI服務很快就會支援MI300X。社群網站公司Meta也表示,他們將會擴展與AMD的合作,並在自家資料中心將MI300X用於AI推論的工作。


在伺服器廠商的部分,Dell、Supermicro、聯想也在這場活動前來站臺表達支持,並預告將推出搭配這款GPU的機型。
以Dell為例,旗下的6U、8-GPU伺服器PowerEdge XE9680,目前可搭配8個Nvidia頂級資料中心GPU(A100或H100),未來將提供搭配AMD Instinct MI300X的組態;

Supermicro將在H13世代的產品當中,推出6U、8-GPU伺服器AS-8125GS-TNMR2,搭配2顆AMD EPYC 9004處理器;

聯想表示,ThinkSystem平臺將會提供8-GPU伺服器,搭配2顆AMD EPYC處理器,預計2024年上半推出。

產品資訊
AMD Instinct MI300X
●原廠:AMD
●建議售價:廠商未提供
●外形:OAM
●晶片製程:微影製程TSMC 5nm FinFET,主動中介層晶粒製程TSMC 6nm FinFET
●I/O介面:PCIe 5.0 x16
●GPU架構:AMD CDNA3
●GPU核心:304個運算單元,19,456個串流處理器,1,216個矩陣核心
●GPU記憶體:192 GB HBM3
●記憶體最大頻寬:5.3 TB/s
●運算效能:FP64向量運算尖峰值為81.7 TFLOPS
●支援運算API:ROCm
●Infinity Fabric Links:7個
●耗電量:750瓦
【註:規格與價格由廠商提供,因時有異動,正確資訊請洽廠商】
熱門新聞

2026-02-09

2026-02-06

2026-02-09

2026-02-09


2026-02-09

2026-02-09

2026-02-06